近日,DeepSeek 团队发布了关于其最新模型 DeepSeek-V3的一篇技术论文,重点讨论了在大规模人工智能模型训练中遇到的 “扩展挑战” 以及与硬件架构相关的思考。这篇长达14页的论文不仅总结了 DeepSeek 在开发 V3过程中的经验与教训,还为未来的硬件设计提供了深刻的见解。值得注意的是,DeepSeek 的 CEO 梁文锋也参与了论文的撰写。

论文地址:https://arxiv.org/pdf/2505.09343
该研究表明,当前大语言模型(LLM)的迅速扩展暴露了现有硬件架构的许多局限性,比如内存容量、计算效率和互连带宽。DeepSeek-V3在2048块 NVIDIA H800GPU 集群上训练,通过有效的硬件感知模型设计,克服了这些限制,实现了经济高效的大规模训练和推理。
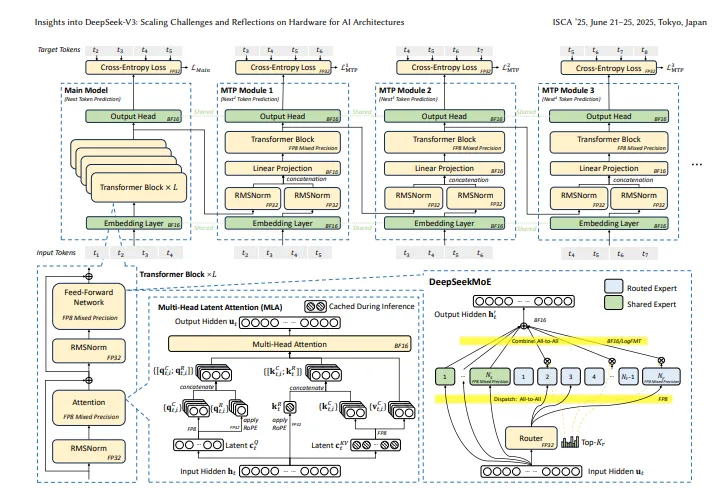
论文中提出了几个关键点。首先,DeepSeek-V3采用了先进的 DeepSeekMoE 架构和多头潜在注意力(MLA)架构,极大地提高了内存效率。MLA 技术通过压缩键值缓存,显著降低了内存使用,使得每个 token 只需70KB 的内存,相比其他模型大幅减少。
其次,DeepSeek 还实现了成本效益的优化。通过其混合专家(MoE)架构,DeepSeek-V3在激活参数的数量上实现了显著的降低,训练成本相比于传统密集模型降低了一个数量级。此外,该模型在推理速度上也进行了优化,采用双微批次重叠架构来最大化吞吐量,确保 GPU 资源得到充分利用。
DeepSeek 在未来硬件设计方面提出了创新的思考。他们建议通过联合优化硬件和模型架构,来应对 LLM 的内存效率、成本效益和推理速度三大挑战。这为日后的 AI 系统开发提供了宝贵的参考。