创建 Next 项目
首先,使用 npx create-next-app@latest 根据提示完成 Next 项目的创建:
复制# 创建 Next 项目 npx create-next-app@latest
创建好项目之后,在 src/app 目录下新建 rag 目录,本次 demo 的代码都将放在这里。
知识库构建
接下来,我们将构建知识库,主要目标是将准备好的 pdf 通过向量化存到向量数据库中,以便后续的检索。
由于本次 RAG 系统的开发都要依赖 LangChain 框架,所以我们先在项目中安装 LangChain 框架和核心依赖:
复制# LangChain 框架和核心依赖 npm install langchain @langchain/core
文档加载
LangChain 的 DocumentLoaders[1] 提供了种类丰富的文档加载器,可加载文件系统的文件也可以加载线上文件,包括 csv、docx、pdf、pptx、html、github、youtube等等。
现在我们使用 PDFLoader[2] 来实现 pdf 的数据加载。
先安装所需的依赖包:
复制# @langchain/community:包含第三方集成,这些集成实现了 LangChain Core 中定义的基本接口,如:文档加载、文档嵌入、向量数据库等等 # pdf-parse:读取 pdf 文本 npm install @langchain/community pdf-parse
然后添加加载 pdf 的代码:
复制import { PDFLoader } from '@langchain/community/document_loaders/fs/pdf';
const loader = new PDFLoader('public/example.pdf', { splitPages: false });
const docs = await loader.load();文档分割
加载完成后,由于加载的文档可能过长,不适合模型的上下文窗口,需要将文档分割成合适的大小。
LangChain 提供了 TextSplitter[3] 组件来实现文档分割:
复制import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
// chunkSize:分割文档的长度
// chunkOverlap:分割文档间的重叠长度
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const texts = await textSplitter.splitDocuments(docs);文档向量嵌入
接下来我们需要对分割后的文本块进行向量嵌入,然后使用 Chroma 向量数据库存储。
向量模型使用 ollama 安装的 nomic-embed-text 模型,可用 ollama run nomic-embed-text进行下载和运行,完整的代码如下:
复制import {
Chroma,
ChromaLibArgs,
} from'@langchain/community/vectorstores/chroma';
import { ChatOllama, OllamaEmbeddings } from'@langchain/ollama';
import { EmbeddingsInterface } from'@langchain/core/embeddings';
// 初始化 embeddings 函数
exportfunctioninitOllamaEmbeddings(model = 'nomic-embed-text') {
returnnewOllamaEmbeddings({ model });
}
// 初始化向量数据库
exportfunctioninitChroma(
embeddings: EmbeddingsInterface = initOllamaEmbeddings(),
args: ChromaLibArgs = {
collectionName: 'rag_collection',
url: 'http://localhost:8000',
}
) {
returnnewChroma(embeddings, args);
}
// 初始化向量数据库
const chromadb = initChroma();
// 保存文本块
const documents = await chromadb.addDocuments(texts);到此就构建好了一个简单的知识库。
RAG 系统构建
在创建好知识库之后,接下来就可以开始构建一个基础的 RAG 系统。该系统包括检索器与生成器两部分,具体工作流程如下:对于用户输入的问题,检索器先搜索与该问题相关的文档,接着将检索到的文档与初始问题一起传递给生成器,即大语言模型,最后将模型生成的答案返回给用户。
检索器创建
我们先基于 VectorStoreRetriever 创建检索器,利用向量相似度进行检索。
复制// 初始化向量数据库 const chromadb = initChroma(); // 创建检索器 const retriever = chromadb.asRetriever();
生成器创建
接下来我们创建生成器,这里我们使用 Ollama 安装的 deepseek-r1:14b 大模型作为生成器。
复制import { ChatOllama } from '@langchain/ollama';
export function initOllamaLLM(model = 'deepseek-r1:14b') {
return new ChatOllama({ model });
}
// 创建生成器(初始化大模型)
const ollamaLLM = initOllamaLLM()然后再设置提示模版:
复制// 设置提示模版
const prompt = PromptTemplate.fromTemplate(
'你是负责回答问题的助手。使用以下检索到的上下文片段来回答问题。如果你不知道答案,就说你不知道。\n\n上下文:{context}\n\n问题:{question}\n\n回答:'
);RAG 链生成答案
最后我们通过 RAG 链将检索器和生成器整合在一起,这里可以使用 LangChain 表达式语言(LangChain Execution Language,LCEL)来方便快捷地构建一个链,将检索到的文档、构建的输入 Prompt 以及模型的输出组合起来。
复制// 使用 LCEL 构建 RAG 链
const ragChain = RunnableSequence.from([
{
context: retriever.pipe((docs) => {
// 文档列表使用 \n\n 拼接为字符串
return docs.map((doc) => doc.pageContent).join('\n\n');
}),
question: newRunnablePassthrough(),
},
prompt,
ollamaLLM,
newStringOutputParser(),
]);
// 使用 RAG 链生成答案
const answer = await ragChain.invoke(question);项目代码
代码:https://github.com/laixiangran/ai-learn
启动项目之后在浏览器输入 http://localhost:3000/rag 即可访问该 RAG 系统,然后在输入框输入问题:互联网的人才缺口有哪些

也可以通过访问 http://localhost:3000/rag/generate?questinotallow=互联网的人才缺口有哪些
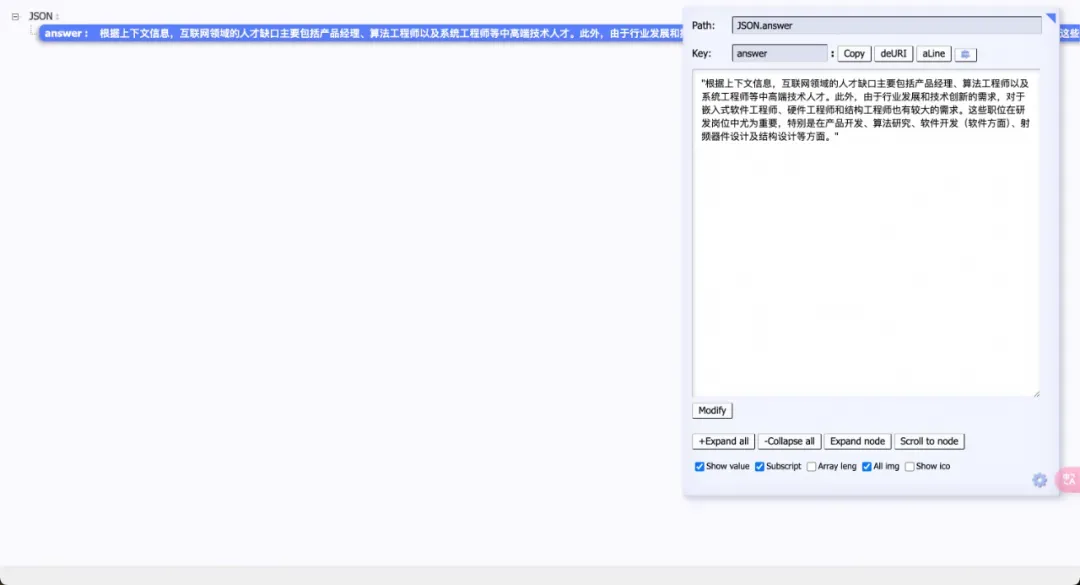
通过以上步骤,我们就完成了一个基础 RAG 系统的搭建,其中借助于 LangChain 提供了一系列强大的工具和组件,使得构建和整合检索与生成过程变得简单而高效。而借助 Ollama 我们也能够在本地部署大语言模型和向量模型,这让我们可以以较小的资源进行 AI 的开发学习实践。
引用链接
[1] DocumentLoaders: https://js.langchain.com/docs/concepts/document_loaders
[2] PDFLoader: https://v03.api.js.langchain.com/classes/_langchain_community.document_loaders_fs_pdf.PDFLoader.html
[3] TextSplitter: https://js.langchain.com/docs/concepts/text_splitters