资讯列表

OpenAI 计划融资高达 1000 亿美元,估值或达 8300 亿美元
正文:根据 AIbase 的最新报道,OpenAI 正积极寻求融资,目标金额高达 1000 亿美元。 这一资金的募集旨在支持公司雄心勃勃的增长计划,而目前市场对人工智能的热情似乎有所减退。 知情人士透露,如果此次融资成功,OpenAI 的估值可能高达 8300 亿美元。

对标TPU、发力推理端:英伟达闪电集成Groq技术重塑AI工厂架构
英伟达(NVIDIA)近日斥资约200亿美元,获得了 AI 芯片初创公司 Groq 的技术非独家授权。 尽管 Groq 仍保持独立运营,但其创始人 Jonathan Ross 等核心团队已加入英伟达,这笔交易被外界视为一次旨在规避监管审查的“变相收购”,其交易金额高达 Groq 此前估值的三倍。 战略防御:围堵谷歌 TPU 威胁英伟达此举的核心目标是应对谷歌张量处理单元(TPU)日益严峻的挑战。

ChatGPT将推“技能(Skills)!OpenAI内部代号“榛子”,可组合、可移植、支持代码,2026年初或上线
OpenAI正悄然为ChatGPT构建新一代“能力操作系统”。 据BleepingComputer最新披露,OpenAI已在内部测试名为 “Skills”(技能)的全新功能,其设计理念与Anthropic的Claude Skills高度相似,但更强调模块化、可执行性与跨平台复用。 该功能代号“hazelnuts”(榛子),预计将于2026年1月前后正式上线,有望彻底改变用户与AI的协作方式。

阿里云开源通义千问图像编辑模型 Qwen-Image-Edit-2511!修复“图像漂移”问题,编辑一致性显著提升
阿里云持续加码AIGC开源生态。 今日,通义实验室正式开源其最新图像编辑模型——Qwen-Image-Edit-2511,重点解决前代版本(2509)中存在的图像编辑后“轻微漂移”问题(即编辑区域人物或物体位置发生偏移),通过多项技术优化,显著提升编辑前后的一致性与视觉稳定性,为开发者提供更可靠、精准的可控生成工具。 直击痛点:告别“越修越歪”的编辑体验在早期版本Qwen-Image-Edit- 2509 中,用户反馈在进行局部修改(如更换服装、调整发型、替换背景)时,目标对象常出现微妙但明显的位移或形变,破坏图像整体协调性。

比亚迪全系车型搭载豆包大模型!携手火山引擎打造行业最大规模智能座舱AI落地
智能座舱进入“全系AI化”时代。 在近日举行的火山引擎FORCE原动力大会上,比亚迪与火山引擎正式宣布达成深度合作,将字节跳动豆包大模型全面集成至比亚迪DiLink智能座舱系统,覆盖仰望、腾势、方程豹、王朝、海洋五大品牌所有在售车型,成为全球车企中智能座舱大模型落地规模最大、覆盖最广的案例。 豆包大模型深度嵌入,座舱交互全面升级此次合作并非简单语音助手叠加,而是将豆包大模型能力深度融合至座舱核心体验: - 智能语音交互:支持全场景连续对话、多意图识别与上下文理解,用户可自然表达如“调低空调、放点轻音乐,再导航到最近的充电站”; - 个性化内容推荐:基于用户偏好与行程,主动推荐音乐、播客、短视频及本地生活服务; - 出行服务闭环:打通充电、停车、餐饮等生态,实现“说走就走”的一站式服务调度。

北京发布开源生态三年行动方案!2028年前打造10个国际顶级开源项目,AI大模型落地目标100个
中国开源生态迎来政策强引擎。 近日,《北京市开源生态体系建设实施方案(2026— 2028 年)正式印发,明确提出:到 2028 年,培育 10 个具有国际影响力的开源项目(其中不少于 5 个达到国际引领水平),打造 30 个国内明星开源项目(AI领域占比超1/3),并推动 100 个行业大模型实现规模化落地应用。 这一方案标志着北京正以国家战略高度系统性构建全球领先的开源创新高地。

Cursor CEO警告“氛围编程”风险:盲目依赖 AI 正在构建不稳固的代码地基
随着生成式 AI 的普及,“氛围编程”(Vibe Coding)这一概念在开发者圈内走红,但热门 AI 编程助手Cursor的首席执行官 Michael Truell 对此发出了严肃警告。 他指出,过度依赖 AI 自动化而不审视底层代码的行为,正在为软件工程埋下隐患。 在近日举行的 Fortune Brainstorm AI 会议上,Truell 详细阐述了他的担忧。

告别对话框!OpenAI 上线“格式化块”,让 ChatGPT 秒变在线编辑器
OpenAI 近日悄然上线了名为“格式化块”的新功能,通过自动调整 UI 布局,使 ChatGPT 的交互界面能够根据特定任务进行适配,从而显著提升内容创作的体验。 以往 ChatGPT 在撰写邮件或博客时,仅能以普通聊天气泡的形式展示内容,用户体验较为单一。 此次更新推出的“格式框”本质上是一个迷你编辑器工具栏。

英伟达推LLM微调“新手友好指南”!集成Unsloth框架,RTX笔记本性能提升2.5倍,本地微调门槛大幅降低
大模型微调正从“实验室专属”走向“人人可及”。 英伟达近日发布面向初学者的LLM微调官方指南,系统性详解如何在从GeForce RTX笔记本到DGX Spark工作站的全系NVIDIA硬件上,利用开源框架Unsloth高效完成模型定制。 该指南不仅降低技术门槛,更通过性能优化,让普通开发者也能在消费级设备上实现专业级微调。

航母心脏变身 AI 引擎:美企提案用退役核反应堆填补美国能源缺口
AI在线 12 月 26 日消息,科技媒体 Tom's Hardware 昨日(12 月 25 日)发布博文,报道称得克萨斯州初创公司 HGP Intelligent Energy 近日向美国能源部(DOE)提交提案,计划重新利用两座退役的海军核反应堆,为位于田纳西州橡树岭国家实验室的 AI 数据中心供电。 图源:Pixabay彭博社报道指出,该公司计划利用这两座旧反应堆提供 450 至 520 兆瓦的电力,足以满足约 36 万户家庭的用电需求。 美国海军目前主要使用西屋公司的 A4W 核反应堆为尼米兹级核动力航空母舰(CVN)供电,并使用通用电气的 S8G 反应堆为洛杉矶级核动力攻击潜艇(SSN)提供动力。

火爆全网的 AI 片场探班玩法,手把手教会你!
往期作者教程:AI 视频玩法又进化了。 最近这一周,小红书上和 X 上铺天盖地的都是 AI 片场探班的视频,点开视频一看,大家都在跟各路明星、角色合影,非常热闹。 我看到这个玩法之后,也立刻随手做了个小东西。

从执行到思考:资深设计师总结的2026年 AI 设计趋势
AI 的出现是一个非常大的革新,改变了我们的工作流,影响了众多岗位的发展。 随着这几年 AI 的发展,从最早的工具协作逐步进化为带有温度的创作伙伴,正在悄然改变设计的本质。 今天黑马哥就和大家一起盘点一下,2026 年 AI 在设计中的趋势,它已经不只是工具,更像是工作中的创作伙伴。

揪出“AI 人脸”更简单,新研究称只需约 5 分钟针对训练即可
AI在线 12 月 25 日消息,据 Phys.org 今晚报道,一项发表在《皇家学会开放科学》的研究指出,只要进行大约 5 分钟的针对性训练,人们识别 AI 伪造人脸的能力就能明显提高。 研究团队来自利兹大学、雷丁大学、格林尼治大学和林肯大学,研究人员让 664 名参与者判断人脸是真实拍摄,还是由生成软件 StyleGAN3 合成。 在没有训练的情况下,具备极强人脸识别能力的“超级识脸者”识破假脸的成功率为 41%,普通参与者的成功率则只有 31%。

星尘智能开启“机器人 MART”千台级批量交付,自主售卖玩偶盲盒
AI在线 12 月 25 日消息,今日,全球首个由绳驱 AI 机器人自主运营的零售服务店“机器人 MART”开启千台级订单批量交付。 该项目由星尘智能与金马游乐联合推出,首批设备落地北京、上海、广州核心商圈,主要售卖“WAKUKU”玩偶盲盒,门店由机器人独立完成语音接待、抓取盲盒、商品递送等操作。 AI在线查询获悉,星尘智能今年 11 月宣布与国内文旅装备龙头企业金马游乐达成战略合作,联合研发新一代文旅文娱机器人系列产品,这是国内人形机器人在文旅文娱、商业服务场景最早一批规模化订单,全球首个由绳驱 AI 机器人自主运营的零售服务店「机器人 MART」也正式落地文旅场景。

用AI代码替换Windows里每一行C/C++!微软回应了
Jay 发自 凹非寺量子位 | 公众号 QbitAI微软光速辟谣了。 Windows Latest消息,微软表示并未打算用AI重写Windows 11。 这与此前内部杰出工程师,声称要用AI Rust淘汰C/C 的言论大相径庭:2030年,彻底消除微软代码中的每一行C/C 代码。

AI 推高“大厂实习生”薪资,OpenAI、谷歌等祭出全职员工级待遇
AI在线 12 月 25 日消息,在人工智能竞争加速的背景下,实习岗位早已不再只是练手机会。 今天晚间,据《商业内幕》报道,AI 领域短期入门岗位薪酬水平已经可以与不少行业的正式全职工作媲美。 报道提到,围绕 AI 研发展开的人才争夺战,让科技巨头不断刷新薪酬上限。
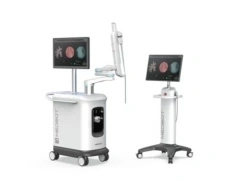
再次填补国产空白,微创独道支气管镜手术机器人获批上市
AI在线 12 月 25 日消息,12 月 23 日,由上海微创医疗机器人(集团)股份有限公司旗下上海微创微航机器人有限公司自主研发的支气管镜手术机器人 —— 独道® UniPath® 电子支气管镜手术导航系统(简称:独道®机器人)正式获得国家药品监督管理局(NMPA)上市批准。 至此,微创®机器人在手术机器人领域获批上市的产品数量增至 7 款,成为全球首家、也是目前唯一一家实现手术机器人“全赛道产品商业化上市”的企业。 这一里程碑式突破,不仅标志着国产手术机器人在微创与微无创诊疗关键技术路径上实现系统性全覆盖,也意味着中国在该领域已无关键技术“空白”。

DeepSeek 与元宝 “互动”!AI 助手日渐融入我们的生活
在科技迅速发展的今天,AI 助手已逐渐成为人们日常生活中不可或缺的一部分。 12 月 24 日,DeepSeek 官方在小红书上与元宝互动,点赞并回应了元宝发布的年度报告,这一罕见的公开互动引起了行业的广泛关注。 根据《元宝 ×DeepSeek 年度报告》,自今年 2 月接入 DeepSeek 以来,元宝的用户规模稳步增长,并在 12 月 14 日达到了使用高峰,增长幅度超过 100 倍。