智能体在执行长周期任务时,始终受限于上下文长度。为此,字节联合提出上下文折叠(Context-Folding)框架,使智能体能够主动管理其工作上下文。该框架允许智能体通过程序分支进入子轨迹以处理子任务,完成后将中间步骤折叠压缩,仅保留结果摘要。为使该行为可学习,研究人员开发了端到端强化学习框架FoldGRPO,通过特定过程奖励鼓励有效的任务分解与上下文管理。
在复杂长周期任务(Deep Research与软件工程)测试中,基于Seed-OSS-36B-Instruct的折叠智能体仅使用1/10的活跃上下文,持平或优于ReAct基线,显著优于基于摘要的上下文管理方法,并与基于100B+参数量大模型所构建智能体的性能相媲美。
 图片
图片
- 论文标题:Scaling Long-Horizon LLM Agent via Context-Folding
- 论文链接:https://arxiv.org/abs/2510.11967
- 项目地址:https://context-folding.github.io/
一、方法
1.上下文折叠框架
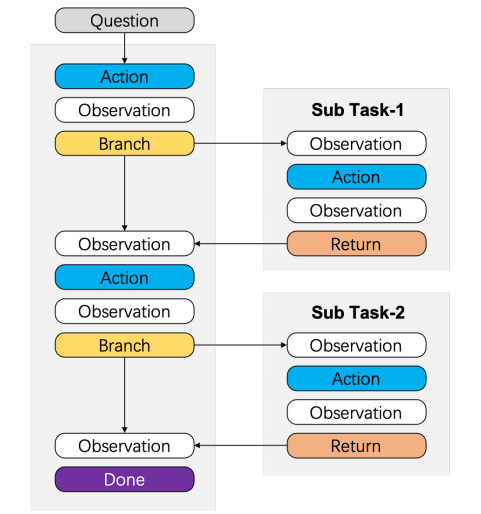 图片
图片
为应对智能体在执行长周期任务时的上下文挑战,论文提出上下文折叠,允许智能体通过分支与折叠主动管理其工作上下文。具体而言,论文设计了两个可供智能体调用的上下文管理工具。从主线程开始解决问题q,智能体可以:
- branch(description,prompt):从主线程分支,使用独立工作上下文完成用于解决q的子任务q′。其中“description”是子任务的简要摘要,“prompt”是该分支的详细指令。该工具返回一个模板消息,表明分支已创建。
- return(message):折叠本分支中生成的上下文并返回主线程。“message”用于描述该分支的执行结果。调用此工具后,智能体上下文将切换回主线程,并附加来自分支的模板消息。
上下文折叠智能体的公式建模为:
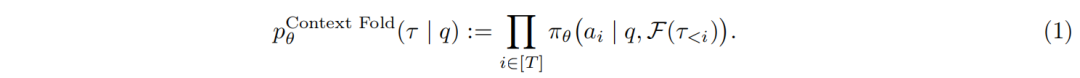 图片
图片
此处τ<i=(a1, o1, ..., ai-1, oi-1)表示第i步之前所有动作-观测对的完整历史记录,F是上下文管理器,负责折叠branch与return工具调用之间交互历史。
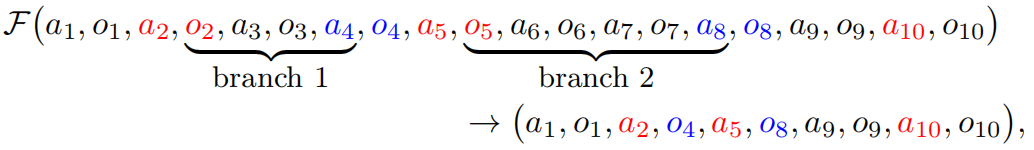 图片
图片
在上述示例中,a2至a4之间以及a5至a8之间的交互片段均被折叠。
推理效率:在推理过程中,智能体管理着上下文KV-cache:当调用return操作时,KV-cache将回滚至对应的branch位置,该位置的上下文前缀需与调用branch操作前的状态保持一致。这一机制使得上下文折叠方法在推理效率方面表现优异。
实例化:为在长周期任务中实例化上下文折叠,采用规划-执行框架,其中智能体在两种状态间交替:
- 规划状态:智能体在主线程进行高层推理,分解任务,并决定何时为子任务创建分支。在此状态下,为保持主上下文聚焦高层策略,不鼓励使用消耗大量token的工具。
- 执行状态:智能体在分支内运行以完成指定子任务。为保持清晰的结构并避免复杂嵌套,执行状态下禁止创建新的分支。
2.FoldGRPO强化学习
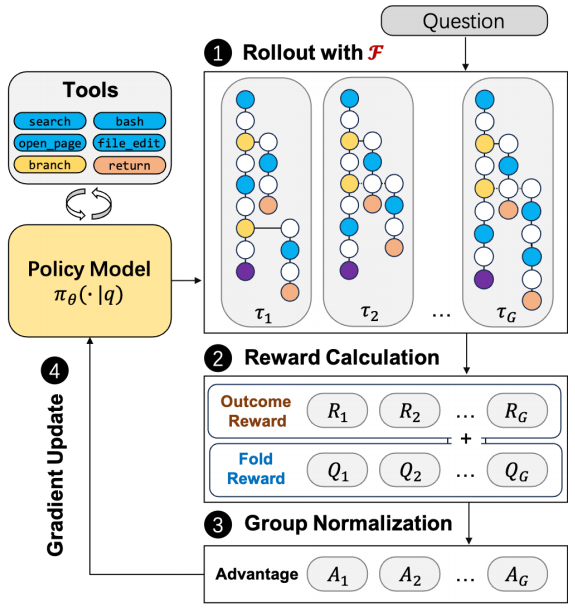 图片
图片
为优化上下文折叠智能体,论文提出一种端到端强化学习训练框架FoldGRPO。该框架联合优化包含主线程及子任务分支的完整交互轨迹,并基于上下文折叠建模(公式1)对rollout历史进行折叠,从而在训练过程中保持紧凑的工作上下文。此外,FoldGRPO采用创新的过程奖励设计,可有效指导智能体分支行为的训练。
(1)整体算法设计
在FoldGRPO的每个训练步骤中,对于训练数据集D的任务q,根据上下文折叠建模(公式1)从旧策略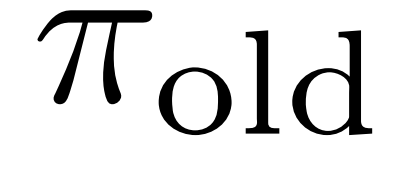 中采样G条轨迹
中采样G条轨迹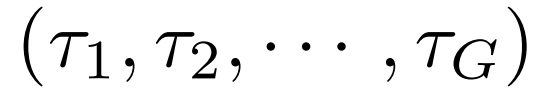 。每条完整轨迹(例如
。每条完整轨迹(例如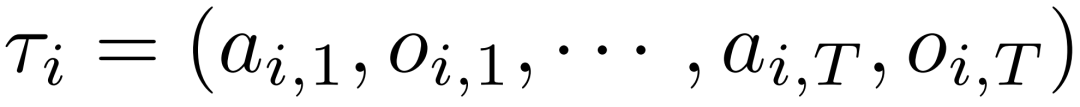 )被定义为token序列
)被定义为token序列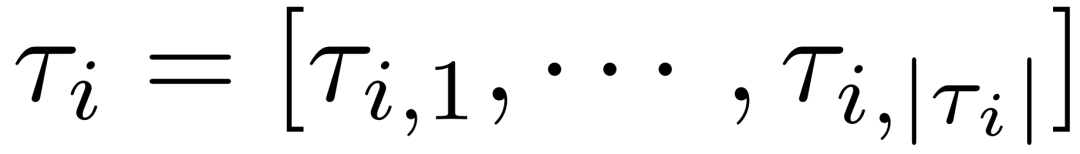 。每条轨迹τᵢ对应最终奖励Rᵢ∈{0,1},遵循可验证奖励的强化学习。
。每条轨迹τᵢ对应最终奖励Rᵢ∈{0,1},遵循可验证奖励的强化学习。
学习目标:FoldGRPO的学习目标定义为:
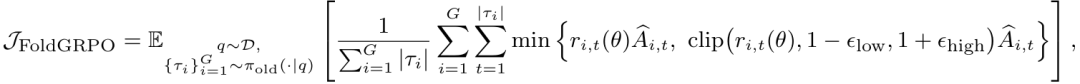
其中重要性采样比率与组相对优势估计为:
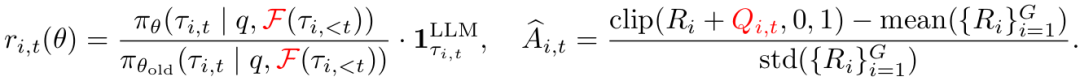
此处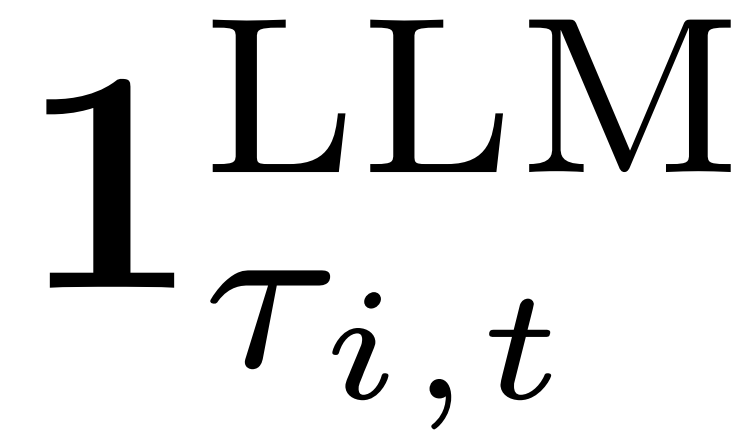 确保仅优化LLM生成的token,并掩码工具观察token。
确保仅优化LLM生成的token,并掩码工具观察token。
其中,FoldGRPO以红色标出两个关键特性:
- 上下文折叠:与在策略优化时将完整交互历史追加至上下文的标准多轮LLM强化学习算法不同,FoldGRPO将上下文管理器F(⋅)应用于历史τi,<t,基于branch-return操作对token τi,t的上下文进行折叠。
- 过程奖励信号:在计算优势
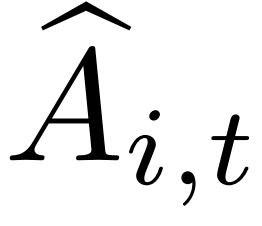 时,加入token级过程奖励
时,加入token级过程奖励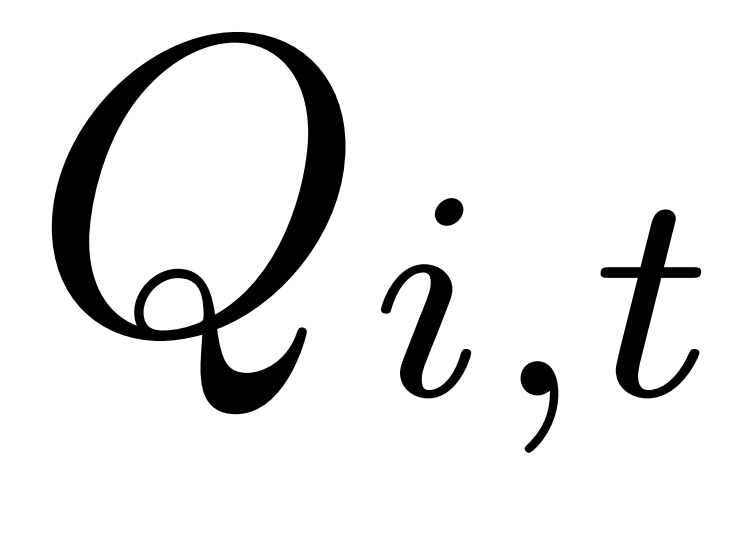 以规范模型的branch-return行为。
以规范模型的branch-return行为。
(2)过程奖励设计
在RLVR中,智能体通常通过基于任务成功或失败的二元结果奖励进行优化。然而研究人员发现,这种稀疏奖励信号不足以有效学习上下文折叠行为。具体表现为两种关键失败模式:
- 智能体未能进行策略性规划,将token密集型操作保留在主上下文中未作折叠,迅速耗尽可用token预算;
- 智能体难以进行有效的分支管理,常在子任务完成后未能从子分支返回,反而在同一分支内继续后续工作。
为有效优化折叠智能体,分别针对主轨迹token和分支轨迹token引入token级过程奖励。
未折叠token惩罚:当主线程的总上下文长度超过工作上下文限制的50%时,对主线程中所有token(创建分支的回合对应的token除外)施加Qi,t=-1的惩罚。此举旨在惩罚智能体在主线程非分支环境下执行的token密集型操作,并鼓励其将此类操作在分支中执行。
超范围惩罚:针对每个分支,采用GPT-5-nano模型,基于分支提示词与返回消息判断智能体是否执行了指定子任务范围之外的操作。若存在此类行为,对该分支内所有token施加Qi,t=-0.2的惩罚,这促使智能体仅执行当前分支既定的确切子任务。
失败惩罚:对失败工具调用回合中的所有token施加Qi,t=-1的惩罚。其余所有情况下,Qi,t=0。
3.上下文折叠与其他方法的关联
与多智能体系统的关系:上下文折叠可被视为广义多智能体系统的一种特定实现形式,主智能体将子任务委托给子智能体执行。但与主流多智能体系统相比存在以下差异:
- 上下文折叠不采用预定义的子智能体,而是由主智能体动态创建;
- 所有智能体共享相同的上下文前缀,使其对KV-cache友好;
- 主智能体与子智能体交替运行而非并行执行。
与基于上下文摘要方法的关系:相较于基于启发式摘要的上下文管理方法(其在任意节点丢弃细节信息),上下文折叠可视为一种与子任务边界对齐的可学习摘要机制。这能确保推理在执行期间得以完整保留,仅在其效用实现后才被压缩。
二、实验
 图片
图片
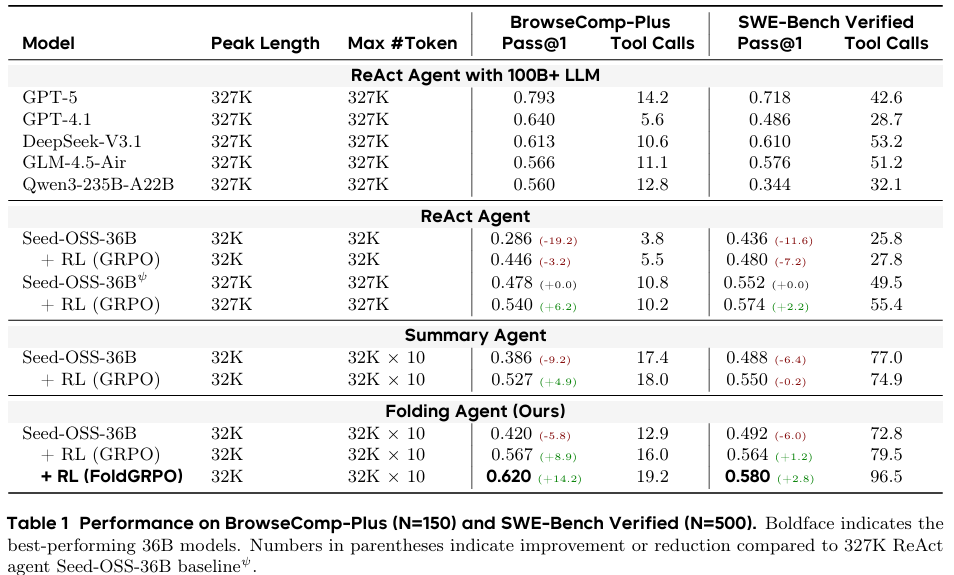
表1总结了在BrowseComp-Plus(Deep Research任务)和SWE-Bench Verified(软件工程任务)数据集上的主要结果。对于折叠智能体,论文将LLM的最大上下文长度设定为32,768个token,并允许最多创建10个分支,从而实现327,680个token的理论上下文上限。
在未进行强化学习训练时,折叠智能体的表现已超越32K上下文的ReAct及上下文摘要基线,但尚未达到长上下文ReAct智能体的性能水平。经过强化学习训练后,智能体性能显著提升:在BrowseComp-Plus数据集上Pass@1达到0.620(+20%),在SWE-Bench Verified数据集上Pass@1达到0.580(+8.8%)。折叠智能体不仅超越了所有基线(包括具有相同327K最大上下文长度的长上下文ReAct智能体),更与基于100B+参数量大模型所构建智能体的性能相媲美。
深入分析表明,FoldGRPO性能显著优于基准GRPO(如在BrowseComp上提升7.7%,在SWE-Bench上提升1.6%);其次,性能提升与工具调用频率的增加相关,而强化学习训练进一步促进了该行为。表明论文框架使智能体能够对环境进行更全面的探索,从而发现更鲁棒的解决方案。
 图片
图片
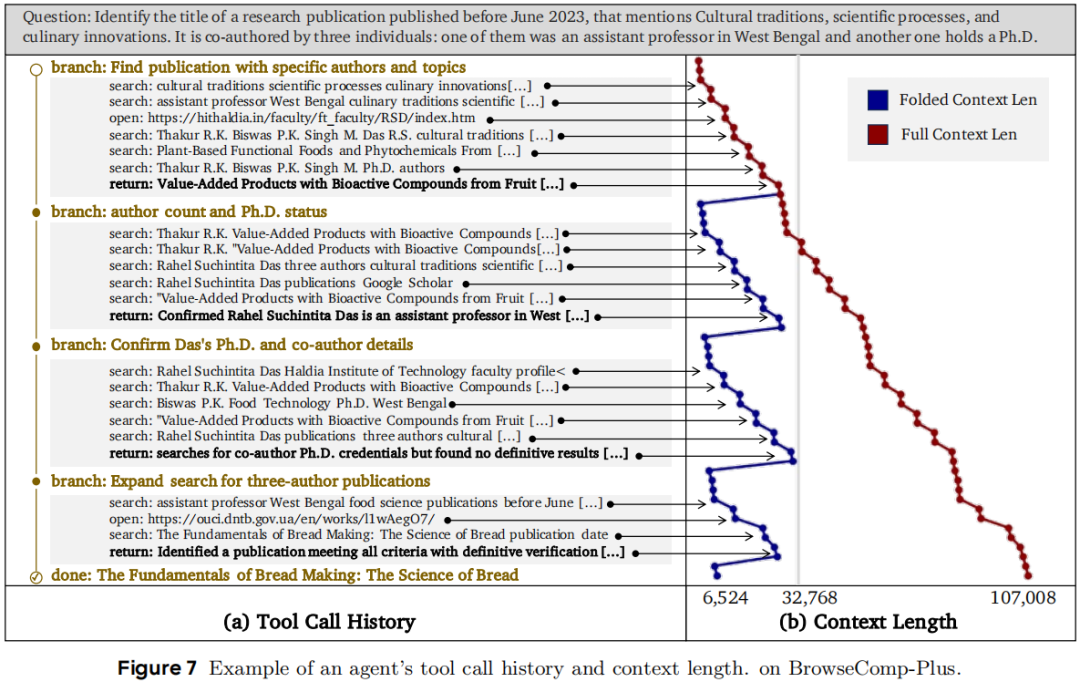
上图展示了折叠智能体在BrowseComp-Plus上的定性案例。针对需要满足特定条件的文献检索任务,智能体首先探索高层主题并确定候选文献,随后通过分支搜索验证具体条件,在获得关键信息但未能完全确认所有要求后,进一步扩展搜索范围并最终找到正确答案。在此过程中,4个分支将完整的107K token上下文压缩至仅6K。


