资讯列表

陈丹琦,入职Thinking Machines Lab了?
陈丹琦加入 Thinking Machines Lab 了? 注:Thinking Machines Lab 由前 OpenAI CTO Mira Murati 于 2025 年 2 月创立,团队成员主要由多位前 OpenAI 员工构成,目前人数在几十人左右。 该公司致力于前沿的多模态 AI 模型与技术研发。

刚刚,全球AI百强榜发布!ChatGPT稳坐第一,DeepSeek第三,前50有22个来自中国
就在刚刚,a16z最新一期的「Top 100消费级GenAI应用榜单」出炉! 本期榜单传递出一个最核心信息:AI产品竞争的生态格局正日趋稳定! 网页排行前50移动应用排行前50不论是你常用的DeepSeek、豆包、夸克,还是一直领先的ChatGPT和Gemini,或者是新进榜单Lovable等,这场AI产品的「百团大战」依然在继续!

从汉语言文学学生到鸿蒙先锋:林子亿的跨界成长与生态探索
当汉语言文学的诗意撞上鸿蒙开发的代码,会迸发出怎样的创新火花? 林子亿,这位汉语言文学专业的大二学生,用行动给出了答案。 作为十年"花粉"的他自2019年HarmonyOS发布后便埋下技术火种,2022年正式踏上鸿蒙开发之路。

英伟达再次炸场!单季营收467亿美元暴涨56%,AI芯片王者地位无人撼动
全球市值最高的科技巨头英伟达再次用一份亮眼的财报征服了整个市场。 周三发布的最新财报显示,这家AI芯片巨头在第二季度实现营收467亿美元,同比暴涨56%,延续了令人瞩目的高速增长轨迹。 驱动这一惊人增长的核心引擎依然是AI主导的数据中心业务,该板块营收同比飙升56%,成为公司业绩爆发的最强动力源。

OpenAI 将监测用户聊天记录并向警方报告威胁性内容
最近,OpenAI 在其博客中透露,该公司将开始扫描用户与 ChatGPT 的聊天记录,以检测潜在的有害内容。 此举引发了广泛关注,因为它与公司之前对用户隐私的承诺存在矛盾。 OpenAI 表示,当用户显示出对他人构成威胁的迹象时,其对话将被转交给专门的团队进行审核。

OpenAI 与 Anthropic 进行首次合作测试,推动 AI 安全标准
在当前竞争激烈的人工智能(AI)领域,OpenAI 和 Anthropic 两家顶尖 AI 实验室决定进行一项前所未有的合作,联合对彼此的 AI 模型进行安全性测试。 这一举措旨在识别各自内部评估中的盲点,并展示在确保 AI 安全与对齐方面,领先企业之间如何能够携手共进。 OpenAI 联合创始人沃伊切赫・扎伦巴(Wojciech Zaremba)在接受采访时指出,随着 AI 技术逐步成熟并被广泛使用,这种跨实验室的合作显得尤为重要。

AI 助力解决 911 紧急呼叫中心人手不足难题
近年来,911紧急呼叫中心面临着严重的人员短缺问题,这不仅影响了应急响应效率,还给在职的调度员带来了极大的压力。 在这种背景下,一家名为 Aurelian 的初创公司应运而生,专注于开发一种 AI 语音助手,旨在帮助911呼叫中心处理非紧急呼叫。 图源备注:图片由AI生成,图片授权服务商MidjourneyAurelian 的创始人 Max Keenan 在参与 Y Combinator 的2022年夏季项目时,最初专注于为美发沙龙自动化预约。

谷歌"香蕉"模型nano banana震撼发布!图像编辑能力碾压所有对手
想象一下这个场景:你正在设计一个品牌Logo,客户突然要求修改颜色、调整字体,还要保持角色的一致性。 以往你可能需要在Photoshop里折腾半天,但现在,只需要一句话就能搞定——"把这个logo改成蓝色调,让角色表情更友善一些"。 这不是科幻电影,而是谷歌刚刚发布的Gemini 2.5 Image模型,代号"Nano Banana"正在创造的现实。

不靠高薪靠信仰!以文化破局,Anthropic凭「使命驱动」杀出AI人才血路
如今的大模型厂商,如足球豪门一样争夺开发者,动辄开出百万甚至千万的年薪。 例如Meta花五千万年薪来招募AI工程师,身价已经超过了足球明星姆巴佩和内马尔。 在Meta与OpenAI等科技巨头之间,顶尖AI人才的争夺战已近白热化。

破解人机协作密码:工作技能拆成两层,AI执行人类决策成功率狂飙 | ICML 2025
人类和AI在工作中如何协作? 耶鲁和南大的研究人员合作的这篇论文讲清楚了。 这篇论文提出了一个数学框架,通过把工作技能拆分成两个层次来解释这个问题,具体包括:决策层子技能(decision-level subskill):确立目标、界定问题、权衡取舍的认知工作。

告别「面瘫」配音,InfiniteTalk开启从口型同步到全身表达新范式
传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。 现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。 为解决这些痛点,Infinitetalk 引入 “稀疏帧 video dubbing”。

从需求分析到代码生成,LLM都能干点啥?一文读懂291个软工Benchmark!
近年来,ChatGPT、Llama等大语言模型在软件工程领域的能力突飞猛进,从需求分析、代码生成到测试与维护几乎无所不能。 但一个核心问题是:我们如何客观评估这些模型在不同软件工程任务中的表现? 在SE领域,Benchmark既是分数卡,让不同模型在同一标准下比拼;也是方向盘,引导技术改进与未来研究方向。
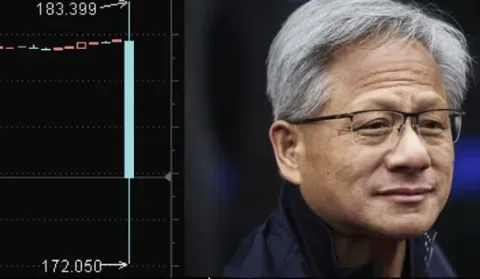
老黄太难了!英伟达Q2营收467亿美元创纪录,股价盘后还跌了5%
英伟达最新财报,营收和每股收益双双超预期! 刚刚公布的第二季度营收467亿美元,高出市场预期1.3%。 调整后每股收益1.05美元,也高于市场预期的1.01美元。

当数字世界的“万能钥匙”被滥用,谁来守护核心资产?来自火山的 MCP 安全授权新范式
摘要本文旨在深入剖析火山引擎 Model Context Protocol (MCP) 开放生态下的 OAuth 授权安全挑战,并系统阐述火山引擎为此构建的多层次、纵深防御安全方案。 面对由 OAuth 2.0动态客户端注册带来的灵活性与潜在风险,我们设计了从“事前预防”到“事中限制”,再到“事后兜底”的完整安全闭环。 该体系通过授权前二次确认、令牌身份与权限隔离、以及 API 级别精细化管控等关键举措,在确保 MCP 生态灵活开放的同时,最大限度地保障用户资产与数据安全,构建值得信赖的开发者生态。

人人都能看懂!一篇文章帮你彻底搞懂AI绘画的底层原理
现在 ComfyUI 慢慢被很多人接受,但是更多的是工程师,作为一名设计师,我发现很难理解 AI 绘画的底层逻辑,如果没有了解本质,只是了解大概,不理解里面各个参数后面的原理,那么之后面临的最直接的一个问题是不知道怎么微调模型,只能照着人家的教程 1:1 模仿。 知其然,不知其所以然是不可取的,这就是“知识”和“懂”的区别。 所以,我一直好奇,AI 绘画是怎么输入描述词,输出一张高质量的又好看的图片的?

揭秘Mem0的卓越架构:打造真正拥有记忆的AI系统
在人工智能应用迅猛发展的当下,聊天机器人已成为企业服务用户、个人提升效率的重要工具。 然而,许多开发者都遭遇过这样的尴尬场景:花费数周精心打造的聊天机器人在演示时表现出色,能流利回答问题、提供帮助,看似智能十足。 但当用户次日再次访问时,机器人却仿佛患上了“失忆症”,只会机械地问“今天我能为您提供什么帮助?

预测型AI vs. 生成型AI:哪种更适合你的企业?
根据Resume Builder最近的一项调查,66%的美国管理者在裁员决策时曾咨询过ChatGPT或其他大型语言模型。 大多数管理者也会使用AI来决定加薪(78%)和晋升(77%),这些数据反映出GenAI正在渗透到业务流程中,这些流程本不应依赖它。 基础模型并非为处理高风险、领域特定的情况而设计,正是这些场景最为敏感。

正确采用AI,防止影子AI迅速蔓延的实战经验
企业采用AI已不再是理论,而是正在发生的现实——无论企业是否做好准备。 员工正在使用公开可用的AI工具完成实际工作:总结文档、撰写邮件、生成报告、翻译资料、编写代码、解答问题。 他们并非因为被强制去做,而是因为这些工具能快速、有效地解决实际问题。