近年来,ChatGPT、Llama等大语言模型在软件工程领域的能力突飞猛进,从需求分析、代码生成到测试与维护几乎无所不能。但一个核心问题是:我们如何客观评估这些模型在不同软件工程任务中的表现?
在SE领域,Benchmark既是分数卡,让不同模型在同一标准下比拼;也是方向盘,引导技术改进与未来研究方向。
然而,现有LLM-SE Benchmark存在三大痛点:
- 零散分布:缺乏覆盖全流程的软件工程任务Benchmark综述
- 构建方式各异:评估指标、数据来源五花八门,难以横向比较
- 研究空白:此前从未有系统文献综述全面汇总软件工程相关的大语言模型Benchmark
这使得开发者和研究者在选择评估方法时常陷入「信息孤岛」,甚至可能被不全面的评估结果误导。
为填补这一空白,来自浙江大学、新加坡管理大学、渥太华大学等机构的团队开展了一项系统文献综述,首次全面梳理了291个用于评估大语言模型在软件工程任务中的Benchmark,并从任务覆盖、语言分布、构建方式到未来趋势进行了深入分析。

论文链接:https://arxiv.org/pdf/2505.08903
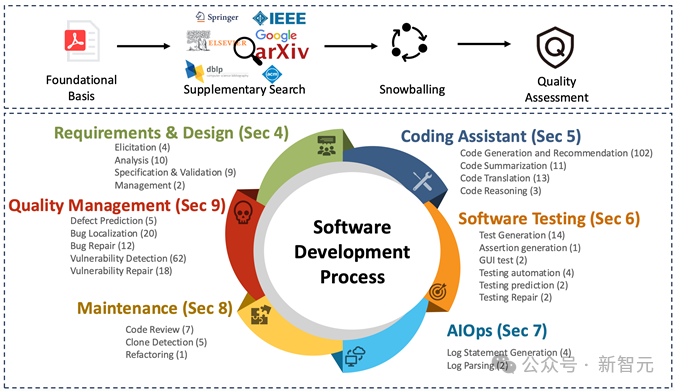
图1 综述框架总览
研究聚焦三大核心问题:
- 现有LLM-SE Benchmark有哪些?
- 它们是如何构建的?
- 它们面临哪些挑战与改进机会?
为了确保全面、系统,研究人员开展「地毯式搜索」:
数据来源:覆盖IEEE Xplore、ACM DL、ScienceDirect、Springer Link等八大数据库;
- 补充检索:采用前向与后向的「滚雪球」检索,确保重要Benchmark不遗漏;
- 严格筛选:设置包含与排除标准,剔除与LLM-SE无关或信息不全的Benchmark;
- 质量评估:从描述清晰度、SE相关性、方法严谨性、可复现性、学术影响五个维度打分;
- 最终成果:汇总291个在2025年6月前发表的Benchmark,按任务、语言、构建方式等多维度分类分析。
六大任务全覆盖
Benchmark演化脉络清晰
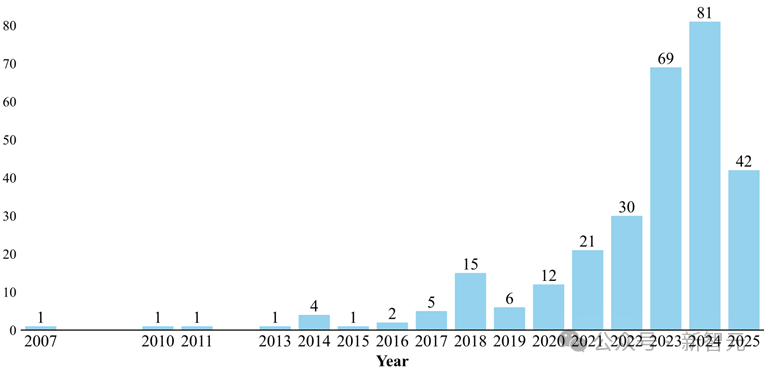
图2 Benchmark年份分布
统计显示,自2022年起Benchmark数量快速增长,2023和2024年分别新增近70个,增长势头迅猛。
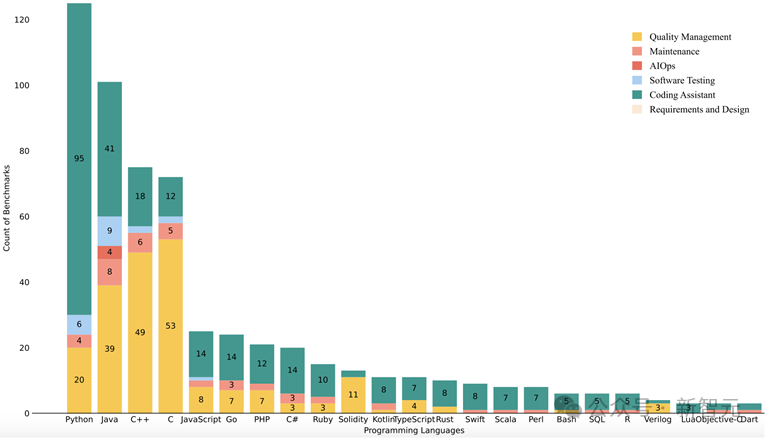
图3 Benchmark语言分布
Python在评估Benchmark中一骑绝尘,主要用于代码生成与推荐类任务;Java、C++、C语言在质量分析与维护任务中占有重要地位;Go、PHP、Ruby等小众语言的Benchmark仍然稀缺。
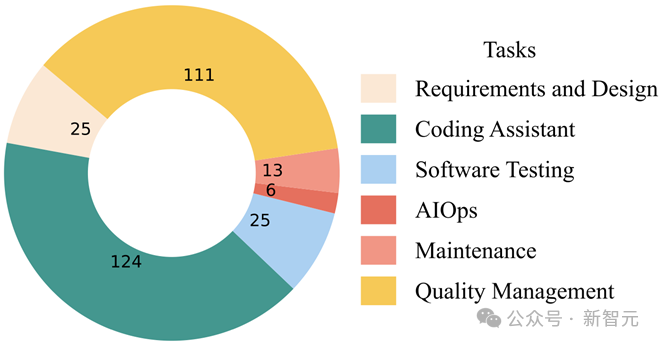
图4 Benchmark任务分布
任务分布(六大类)
- 需求与设计(25个):需求获取、分类、冲突检测、规格化与验证;
- 编码辅助(124个):代码生成、补全、摘要、多语言迁移(占比超40%,最多);
- 软件测试(25个):测试生成、GUI测试、断言生成、自动修复;
- AIOps(6个):日志生成与解析;
- 软件维护(13个):代码审查、克隆检测、代码重构;
- 质量管理(111个):缺陷检测、漏洞识别、修复建议(占比38%)。
其中「编码辅助」任务相关Benchmark数量最多,占比超过40%,其次是质量管理类任务,占比达38%。
现实挑战
Benchmark还远远不够用!
研究指出,当前Benchmark建设存在五大瓶颈:
- 任务定义模糊、评价不一致:缺乏统一标准,难以横向对比;
- 规模受限、计算成本高:多数数据集规模偏小,覆盖不了复杂系统;
- 泛化能力不足:Benchmark表现好,真实场景却「水土不服」;
- 更新滞后:难以及时跟进新技术与框架;
- 数据隐私限制:真实企业数据难以共享,影响高质量Benchmark建设。
未来机会
Benchmark建设仍是「蓝海」
团队提出了五大改进方向:
- 多维评估:引入准确率、可维护性、效率、安全性、可解释性等指标;
- 跨语言、跨任务:统一评估框架,提升通用性;
- 贴近真实场景:引入真实项目数据,提高落地性;
- 人类反馈与伦理考量:纳入有害性检测、隐私风险等维度;
- 动态可扩展平台:支持任务扩展、新模型接入与持续测评。
总结
Benchmark是推动LLM落地的「发动机」
正如作者所言——当前LLM在软件工程中的应用正处于「黄金发展期」,但真正能驱动其走向工业落地、提升工程可信度的,是那些更真实、更多维、更动态的Benchmark体系。
这项研究不仅填补了LLM软件工程评估的综述空白,也为AI4SE研究者、开发者和企业提供了清晰的「下一步方向」。
如果说模型是「马达」,Benchmark就是「方向盘」。谁能把握住它,谁就能在AI软件工程的未来之路上走得更远。


