想象一下这个场景:你正在设计一个品牌Logo,客户突然要求修改颜色、调整字体,还要保持角色的一致性。以往你可能需要在Photoshop里折腾半天,但现在,只需要一句话就能搞定——"把这个logo改成蓝色调,让角色表情更友善一些"。
这不是科幻电影,而是谷歌刚刚发布的Gemini 2.5 Image模型,代号"Nano Banana"正在创造的现实。
 图片
图片
一个"香蕉"代号背后的技术突破
这个有着可爱代号的模型,实际上是Gemini 2.5 Flash Image的最新版本。说实话,刚听到"Nano Banana"这个名字时,我还以为是谷歌工程师们的某种内部玩笑。但看到实际表现后,才明白这个"香蕉"可不简单。
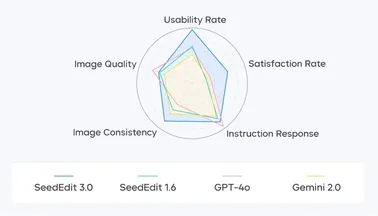
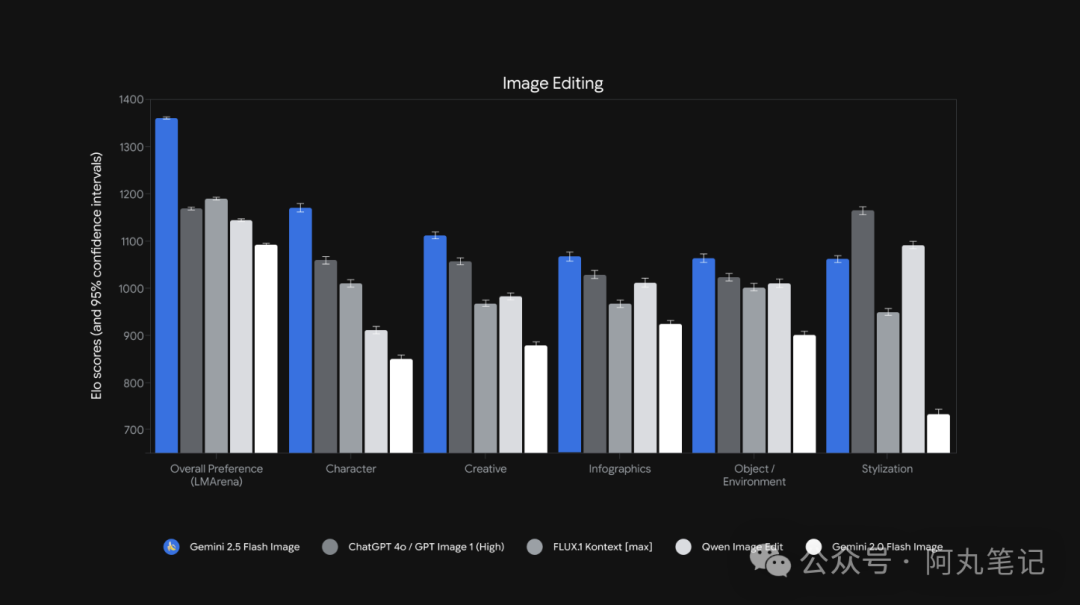
在图像编辑领域,Gemini 2.5 Image获得了+180 ELO的评分优势,在角色一致性方面表现尤其突出。这意味着什么?简单来说,它能在生成或编辑图像时,确保同一个角色在不同场景下保持一致的外观特征,这在以往的AI图像模型中是个老大难问题。
 图片
图片
更令人惊喜的是,这个模型现在已经在Gemini App中免费提供。是的,你没听错,免费。相比其他需要付费订阅的图像生成服务,这种门槛降低确实让人眼前一亮。
图像编辑的"对话时代"来了
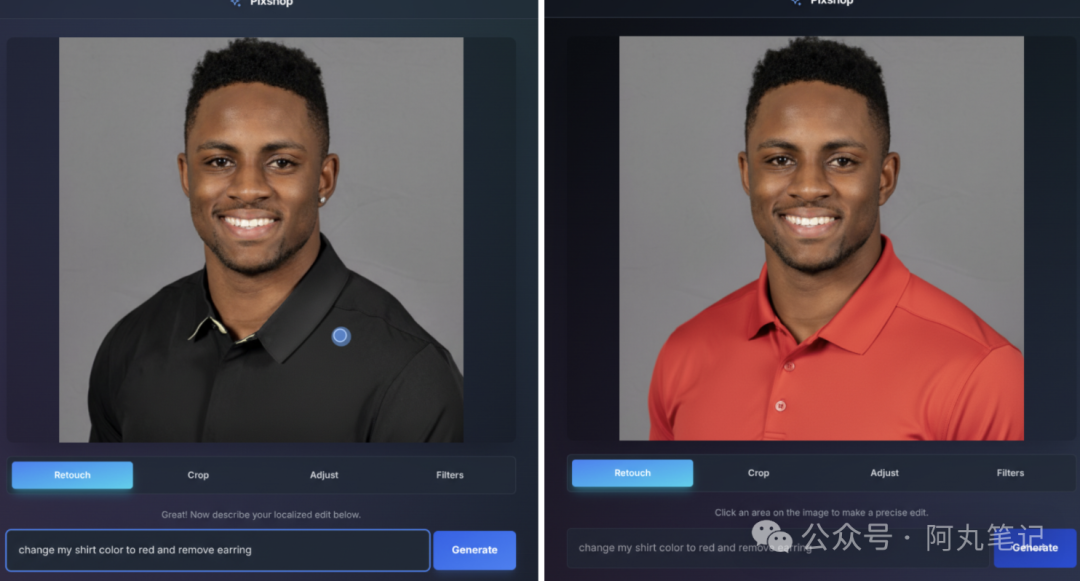
传统的图像编辑软件需要你掌握各种工具和技巧,但Gemini 2.5 Image把这个过程变成了一场对话。你可以说"让这个人物的表情更开心一些",或者"把背景改成海滩场景",模型就能理解并执行你的指令。
 图片
图片
这种多轮对话式编辑特别实用。比如你先让它生成一个角色,然后说"把头发改成棕色",接着又说"给他戴个帽子",模型能够在每一步都保持角色的基本特征不变,只修改你指定的部分。
我特意试了一下这个功能,让它生成一个卡通猫咪,然后逐步修改颜色、表情、服装。整个过程就像在和一个很有耐心的设计师对话,而且它真的能记住之前的修改,保持一致性。
文字渲染能力的新高度
AI图像生成的另一个老大难问题是文字渲染。以往生成的图片中,文字经常是扭曲的、不完整的,或者干脆就是乱码。但Gemini 2.5 Image在这方面有了显著改进。
现在它能准确渲染长段文字序列,这对创建广告、海报或者社交媒体内容来说非常有用。你可以让它生成一张包含完整产品描述的海报,文字不仅清晰可读,排版也相当专业。
这种能力的提升背后,体现了谷歌在AI图像生成领域的技术积累。毕竟,要让AI准确理解文字内容,并将其以视觉形式完美呈现,需要对语言理解和视觉生成两个领域都有深度掌握。
免费工具的市场冲击
Gemini 2.5 Image的免费策略,确实给图像生成市场带来了不小的冲击。对比一下其他主流服务:Midjourney需要月费订阅,DALL-E有使用次数限制,而谷歌直接选择了免费开放。
当然,免费往往意味着某种战略考量。谷歌可能是想通过这种方式快速获取用户数据,改进模型性能,同时在AI图像生成这个新兴市场中占据先发优势。
对用户来说,这无疑是个好消息。特别是对于内容创作者、小企业主或者设计爱好者,不需要高昂的软件费用,就能享受到先进的AI图像编辑能力。
技术背后的思考
Gemini 2.5 Image的发布,其实反映了AI图像生成技术的一个重要发展方向:从单纯的"生成"向"编辑和交互"转变。
早期的AI图像工具更像是"一次性"的创作,你输入提示词,得到结果,要修改就得重新生成。但现在的趋势是让AI成为一个可以对话的创作伙伴,你可以和它反复沟通,逐步完善作品。
这种变化背后,是对用户真实需求的深度理解。在实际创作过程中,很少有人能一次就得到完美的结果,更多时候需要反复调整和优化。Gemini 2.5 Image正是抓住了这个痛点。
未来的想象空间
虽然目前Gemini 2.5 Image已经表现不错,但还有很大的改进空间。比如在复杂场景的理解、多个角色的协调、以及特定风格的掌握等方面。
但有一点很明确:AI图像编辑正在从专业工具变成大众工具。就像当年智能手机让每个人都能拍出不错的照片一样,现在的AI图像工具正在让每个人都能创作出专业级的视觉内容。
所以,如果你还没试过这个"香蕉"模型,不妨去Gemini App里体验一下。毕竟,现在是免费的,说不定哪天就要收费了。