资讯列表

OpenAI CEO 薪资曝光: 2024 年收入增长显著,前董事因丑闻辞职
根据彭博社的报道,OpenAI 首席执行官萨姆・奥特曼(Sam Altman)在2024年的薪酬为113,674美元,相较于2023年的76,001美元增长了大约50%。 现年40岁的奥特曼同时也是 OpenAI 董事会的成员。 他曾表示,这一收入足以覆盖他的医疗和其他开支,并明确表示未持有 OpenAI 的股权,其财富主要来源于其他投资。

马斯克:未来五年太空 AI 算力将成新趋势,黄仁勋对此表示质疑
在近日的一次公开讲话中,特斯拉首席执行官埃隆・马斯克预测,未来 4 至 5 年内,太空中的 AI 算力将会成为最具成本效益的选择。 他认为,这得益于太空中 “免费的” 太阳能和便捷的辐射冷却方式。 马斯克提到,随着 AI 计算集群的规模不断扩大,地球的电力和散热需求将达到现有基础设施无法承受的水平。

丰田旗舰,用上华为车机
一凡 发自 广交会. 智能车参考 | 公众号 AI4Auto广汽丰田,要停产两款主力油车? 广州车展前夕,这则消息传遍车圈,但智能车参考刚刚在广州看到的最新产品,让传言不攻自破:.

豆包输入法低调现身小米商店,主打智能语音交互
今日“豆包输入法”正式在小米应用商店上线。 然而,这款备受关注的新应用目前暂时处于“维护中”状态,截至发稿时,用户尚无法下载安装。 作为豆包生态的新成员,该输入法核心亮点在于搭载了与豆包 App 同源的语音输入技术。

中国已成为全球开源 AI 大模型的最大提供者
在北京举行的2025开放原子开发者大会上,中国工程院院士倪光南强调,中国已成为全球开源人工智能大模型的最大提供者,特别是如 Qwen、DeepSeek 和 Kimi 等模型在国际评估中表现突出。 他指出,开源技术正成为推动全球信息技术发展的重要力量,尤其是在快速发展的 AI 领域。 倪光南表示,开源的趋势顺应了时代的发展需求,体现了全球信息技术领域的创新活力。

小米汽车回应智驾“起步晚”质疑:2025年AI投入超70亿
据新浪科技报道,在2025广州车展开幕首日的小米汽车发布会上,小米汽车副总裁李肖爽针对外界关于“小米辅助驾驶起步晚、技术能否跟上”的质疑进行了正面回应。 李肖爽表示,团队对技术发展“充满信心”,并指出辅助驾驶的核心本质即是 AI 技术。 他透露,为支撑这一核心战略,2025年小米在 AI 领域的研发投入将超过70亿元。

戴盟新一代视触觉解决方案全球首发,四大功能全新升级
戴盟机器人是一家专注于触觉感知与灵巧操作的具身智能头部企业。 戴盟机器人孵化于香港科技大学,由国际机器人权威王煜教授和段江哗博士联合创立,团队成员来自全球顶尖高校和研究机构。 值得注意的是,自戴盟机器人2023年正式运营至今,已完成了累计数亿元的多轮融资,创下全球视触觉领域新高。
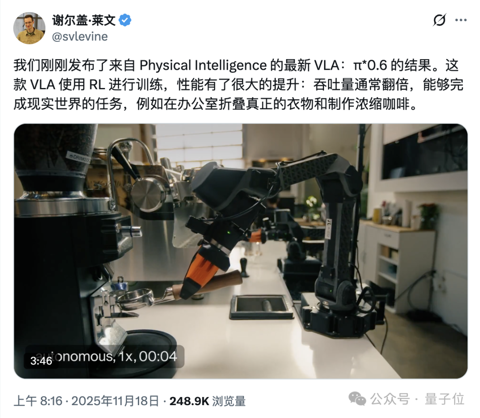
“最强具身VLA大模型”,究竟强在哪儿?
henry 发自 凹非寺. 量子位 | 公众号 QbitAI看似轻描淡写,实则力透纸背。 Physical Intelligence刷屏全网的机器人基础模型π*0.6,一亮相就秀出了实力:.

振臂一挥,大半个具身机器人圈都来了!智源研究院:别藏了,谁贡献数据多,谁的大脑就更好用
允中 发自 凹非寺. 量子位 | 公众号 QbitAI昨天,具身智能的圈子“炸”了。 不是因为某家公司发布了新产品,而是因为一场“具身武林大会”—— 2025智源具身智能Open Day。

维基百科揭秘:如何识别 AI 写作的技巧
近年来,随着大型语言模型(LLM)的发展,越来越多的文本出现在互联网上,让人难以判断其是否为 AI 生成。 为了帮助公众识别 AI 写作,维基百科编辑们开展了一项名为 “AI 清理项目” 的工作,制定了一份关于 “AI 写作迹象” 的详细指南。 这份指南为识别 AI 生成的内容提供了实用的参考。

月之暗面计划明年下半年上市,估值或达 40 亿美元
近日,有消息人士透露,备受瞩目的 “月之暗面” 计划将于明年下半年正式进行首次公开募股(IPO)。 这一消息引发了投资者的热烈讨论,并为公司未来的发展增添了更多期待。 据悉,月之暗面目前正处于筹备新一轮融资的阶段,预计将在 2025 年底前完成这一融资计划。

元宝推出 “一句话生视频” 功能,让视频创作变得简单有趣
近日,元宝正式发布了其全新功能 ——“一句话生视频”,这项创新能力的推出意味着每个人都能轻松成为视频创作者。 该功能的亮点在于用户无需任何视频剪辑的基础,只需简单一句话或一张静态照片,就能快速生成生动有趣的视频内容。 这项技术的核心基于腾讯最新开源的 HunyuanVideo1.5模型。

14万,家务机器人带回家!斯坦福华人博士具身创业首款产品亮相
henry 发自 凹非寺. 量子位 | 公众号 QbitAI斯坦福明星华人博士生的创业机器人,终于正式亮相! 虽然之前卡帕西已经提前剧透,但实际颜值和轮廓大差不差~ 转过身来,它长这样:卡通小脸蛋、头顶棒球帽,白橙配色,轮式驱动,可伸缩的小蛮腰。

智元远征A2完成全球首次人形机器人百公里跨省行走,获吉尼斯世界纪录认证
近日,智元远征A2(SNA210041BA00652号机器人)成功完成了从苏州金鸡湖到上海外滩的百公里跨省行走挑战,创造了一项足以记录在全球机器人发展史上的新纪录。 11月20日,吉尼斯世界纪录认证官向智元远征A2(SNA210041BA00652号机器人)颁发了认证证书,正式确认智元远征A2全程行走距离为106.286km,成为“人形机器人行走最远距离 / Longest journey walked by a humanoid robot”吉尼斯世界纪录保持者,得益于智元研发的快速热插拔换电系统,远征 A2 全程未关机、连续运行完成了挑战。 本次挑战自苏州金鸡湖畔著名地标“东方之门”起,中途穿越市区、景区、国道、省道等多种复杂路段,应对柏油马路、瓷砖路、桥梁、盲道、坡道及夜间照明不足等多样化地形与环境挑战,全程遵守交通规则,最终抵达上海外滩。

维基百科公开“AI写作识别指南”:这些套路暴露了AI的“语言指纹”
你是否曾读到一段文字,总觉得“这不像人写的”?直觉或许没错——但真正识别AI生成内容,不能靠猜“delve”“underscore”这类所谓“AI高频词”。 近日,维基百科编辑团队公开其内部使用的《AI写作识别指南》,首次系统性揭示大语言模型(LLM)在行文中的“行为指纹”,为公众提供了一套可操作、有据可依的AI文本鉴别方法。 自2023年启动“AI清理计划”(Project AI Cleanup)以来,维基百科编辑们每天面对数百万条编辑提交,积累了海量AI写作样本。

OpenAI 推出 “教师专属 ChatGPT”,助力 K-12 教育
OpenAI 近日宣布推出 “ChatGPT for Teachers”,这是一个面向美国 K-12教师的免费 AI 聊天机器人版本。 该项目将持续到2027年6月,旨在为经过验证的教师提供一个安全的工作空间。 OpenAI 表示,该平台在默认情况下不会将用户数据用于模型训练,确保教师的隐私和安全。

OpenAI 发布新 GPT-5 模型,加速数学与科学研究
近日,OpenAI 宣布推出其最新的 GPT-5模型,这一新技术有望在数学和科学研究领域带来显著的加速。 随着人工智能技术的快速发展,各大科技公司纷纷看好 AI 在药物研发和新材料发现方面的潜力。 GPT-5模型的推出,正是顺应这一趋势,旨在帮助科研人员更高效地解决复杂问题。

Gemini 3 登场后,哈萨比斯要「改造」Google 全系产品
在人工智能竞争全面升温的当下,Gemini 3 的登场无疑再次把 Google 推上了聚光灯的中心。 这一代模型上线后也是迅速引发技术圈热议,无论是推理、多模态处理,还是工具调用的稳定性,都展现出显著的提升,被许多人视为 Google 近年最稳健、最成熟的一次升级。 在热度持续攀升的同时,Google DeepMind CEO 德米斯·哈萨比斯接受了一场访谈,系统谈起了 Gemini 3 背后的研发过程,并谈到团队正在推进的能力、内部仍处于原型阶段的方向,以及 Google 心中下一代智能体的样貌。