
在AI领域,RAG(检索增强生成)早已不是新鲜词——它就像给大模型装了一个“外部知识库”,通过检索真实文档来回答问题,避免“瞎编乱造”。但很多人不知道,RAG的效果好坏,很多时候卡在一个看似基础的环节上:文档分块,对于在实际落地中,文档分块也是一个令人非常头疼的难题。
简单说,“分块”就是把长文档切成小片段(比如每200词一段),方便后续检索。可问题来了:传统分块要么“一刀切”(不管语义逻辑,固定长度切分),要么“看局部”(只关注句子级关联,忽略文档的章节、子章节结构)。这就导致大模型检索时,要么漏了关键信息,要么抓了一堆无关内容。
针对这个痛点,腾讯优图实验室近期发布了新作 HiChunk——一个能“读懂文档结构”的分层分块框架,还配套了专门的评估基准 HiCBench。下面来聊聊这两个工具如何让RAG分块“更聪明”。
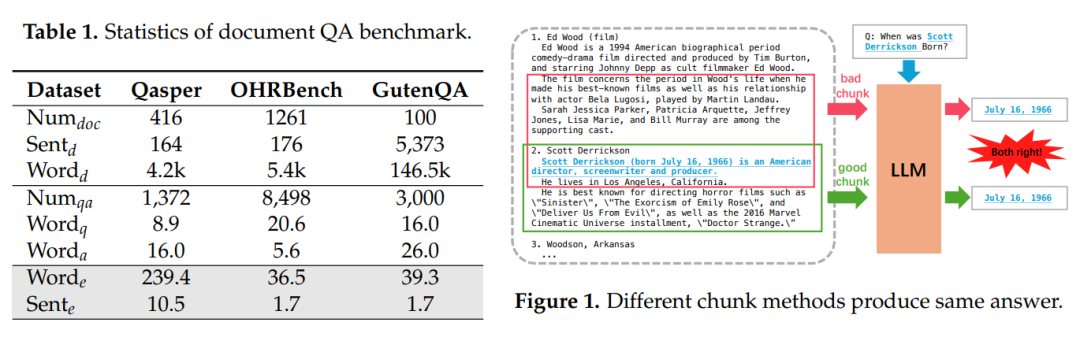
一、先搞懂:为什么“分块”对RAG这么重要?
在聊HiChunk之前,得先明确一个前提:分块不是“切豆腐”,而是决定RAG质量的“第一道关卡”。
举个例子:如果我们有一篇关于“气候变化”的长文档,里面包含“原因”“影响”“解决方案”三个章节,每个章节下还有子主题。
- 若用“固定长度分块”(比如每200词切一段),可能会把“气候变化原因”的后半段和“影响”的前半段切到同一个块里——检索“原因”时,会把“影响”的内容也带进来,干扰判断;
- 若用传统语义分块(只看句子相似度),可能会把“解决方案”章节里的不同子主题拆成多个块——检索“解决方案”时,需要拼多个块才能凑齐完整信息,效率低。
更关键的是,现有评估基准“不给力”:之前的数据集(比如Wiki-727、HotpotQA)要么把文档切成“扁平的句子/段落”(不考虑章节层级),要么只关注“检索器准不准”“回答对不对”,却没专门评估“分块好不好”。就像老师批改作文,只看最终得分,却不看草稿纸的逻辑是否清晰——根本没法判断“分块”这个环节的问题在哪。
这就是HiChunk要解决的核心矛盾:现有分块方法没利用文档层级,现有评估标准没管好分块质量。
针对上述问题,HiChunk给出了“一测一解”的方案:先用HiCBench基准把“分块质量”的评估标准立起来,再用分层分块框架+自动合并算法解决分块本身的问题。
二、先有“尺子”:HiCBench基准——终于能精准评估分块了
之前评估分块,就像用“体重秤量身高”,工具不对。HiCBench则是一把专门的“分块尺子”,它的核心思路是:让QA对的证据“绑定”文档层级,分块好不好,看证据能不能完整召回。
比如传统数据集里,一个问题的证据可能只在1-2个句子里——哪怕分块切得乱,只要找到这两个句子,回答就对了,根本测不出分块的问题。而HiCBench专门设计了三种任务,精准覆盖不同场景:
- T0(稀疏证据):证据只在1-2个句子里(对应日常简单问答);
- T1(单块密集证据):证据全在一个完整语义块里(比如一个章节下的“气候变化原因”段落);
- T2(多块密集证据):证据分散在多个语义块里(比如“解决方案”下的“政策”“技术”两个子章节)。
举个T1任务的例子:问题是“文档中提到的气候变化主要人为原因有哪些?”,证据全在“气候变化原因”这个2000词的语义块里。如果分块把这个块切散了,哪怕找到部分句子,也会漏关键信息——这样就能直接测出分块的好坏。
为了保证质量,HiCBench还做了两件关键事:
- 人工标层级:先给文档标好“章节-子章节-段落”的层级,确保语义块清晰;
- 严筛QA对:用大模型生成候选QA对后,反复验证“证据是否完整”“回答是否符合事实”,最后只保留“证据占比超10%、事实准确率超80%”的样本。
有了HiCBench,终于能说清:“这个分块方法在密集证据场景下更好”“那个方法在超长文档里不行”——评估不再是“凭感觉”。
三、再出“方案”:分层分块框架——让分块懂文档结构
有了评估标准,下一步就是解决分块本身的问题。HiChunk的核心是“让分块像人读文档一样,先看章节,再看段落”,具体分两步:
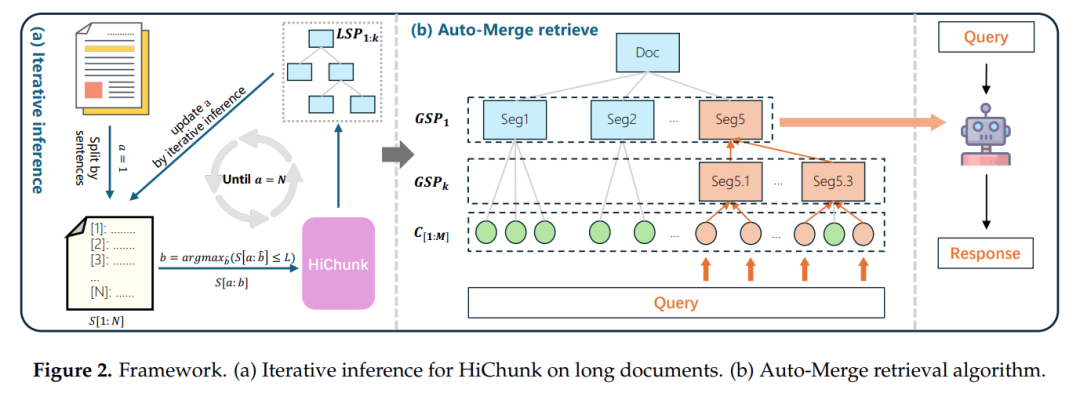
第一步:用大模型“读懂”文档层级
传统分块要么靠规则(固定长度),要么靠相似度(相邻句子像不像),而HiChunk直接用微调后的大模型(基于Qwen3-4B)“理解”文档结构,输出“分层分块点”。
比如处理一篇论文,大模型会自动识别:
- 第1层级分块点:摘要、引言、实验、结论的分隔处;
- 第2层级分块点:引言下“研究背景”“现有问题”的分隔处;
- 第3层级分块点:“现有问题”下“分块问题”“评估问题”的分隔处。
这样一来,文档就从“扁平的文本流”变成了“有树状结构的语义块”,就像给文档建了一个“目录”,后续检索能精准定位到“章节-子章节”级别。
针对超长文档(比如50页的报告),HiChunk还设计了“迭代推理”:先处理前N个句子,标出局部分块点,再衔接下一部分,避免大模型“看不完长文档”的问题。

第二步:自动合并算法——动态适配检索需求
分层分块解决了“结构问题”,但新问题来了:HiChunk 构建的分层树结构具备语义完整性,但语义分块方法导致的分块长度分布差异可能引发语义粒度不一致问题,进而影响检索质量。简单来说,不同语义块的长度不一样(比如一个章节3000词,一个子章节500词),直接检索可能要么“抓太多冗余”,要么“漏关键信息”。
为缓解这一问题,HiChunk 在分块结果的基础上采用固定大小分块方式,得到分块序列C[1:M],并提出 自动合并(Auto-Merge)检索算法,以平衡语义粒度差异与检索分块的语义完整性问题。
它的核心逻辑是:根据查询需求和Token预算,动态把小分块合并成大分块,或保留小分块。
举个例子:假设检索Token预算是4096词,查询是“文档中气候变化的解决方案有哪些?”,算法会这么做:
- 先检索出和“解决方案”相关的小分块(比如“政策方案”“技术方案”两个子章节块,各800词);
- 检查条件:这两个块的父块是“解决方案”(2000词),且当前用了1600词(没超预算),满足“子块交集≥2个、长度够、预算够”的条件;
- 自动合并:把两个子块合并成“解决方案”父块,这样检索到的信息更完整,还没超预算。
如果查询是“政策方案里提到的碳税措施有哪些?”,算法则会保留“政策方案”这个小分块,不合并——避免把“技术方案”的内容带进来,减少冗余。
简单说,这个算法让RAG的检索从“固定粒度”变成了“按需调整”,既不浪费Token,又能保证信息完整。

四、实验说话:HiChunk到底好不好用?
HiChunk在多个数据集上做了对比实验,结果很直观——我们挑几个关键结论看:
分块更准:层级识别能力远超传统方法
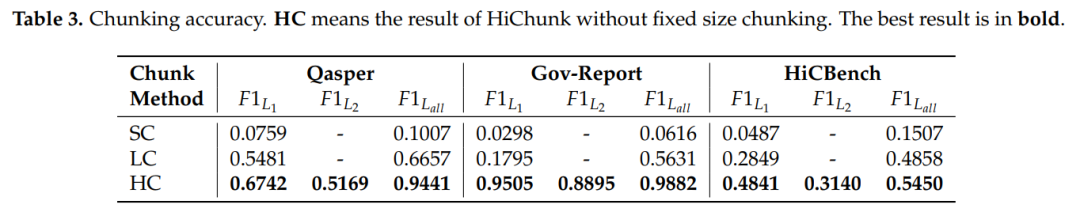
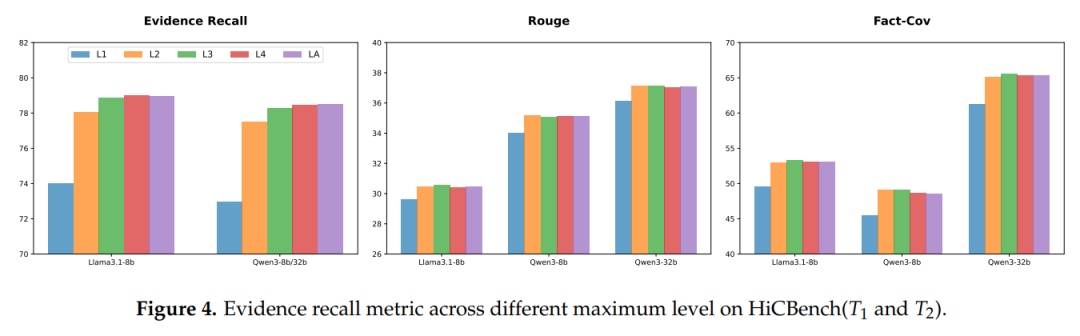
在Qasper(学术论文数据集)和Gov-report(政府报告数据集)上,HiChunk的分块点F1值(越接近1越准)比传统语义分块(SC、LumberChunker)高15%-20%。哪怕在没见过的“域外数据集”(比如陌生领域的报告)上,优势更明显——说明它真的“懂”文档结构,而不是死记硬背。
这些结果表明,HC 方法通过专注于分块任务,有效提升了基础模型在文档分块中的性能。
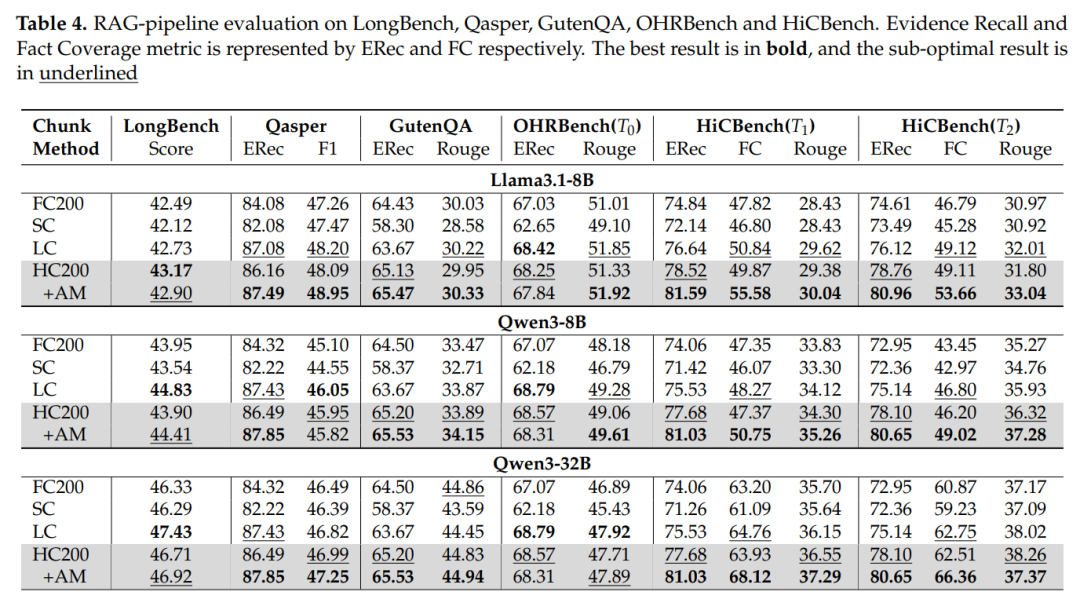
RAG效果更好:尤其在密集证据场景
在HiCBench的T1(单块密集)和T2(多块密集)任务中,HiChunk(HC200+AM)的回答F1值比固定分块(FC200)高10%-12%,比传统语义分块(LC)高5%-8%。而在T0(稀疏证据)任务中,差距不大——这正好说明:在需要完整语义块的场景下,HiChunk的优势才真正凸显,而这正是企业知识库、学术检索等核心场景的需求。
速度够快:兼顾质量和效率
语义分块LC 方法虽表现出较好的分块质量,但其分块速度远慢于其他基于语义的分块方法,处理一篇长文档要好几分钟,这限制了其在实际应用中的适用性。而HiChunk的分块速度是它的3-5倍,同时保持了更高的分块质量。对企业来说,这意味着“既能保证回答准,又能让用户等得少”,落地性大大提升。
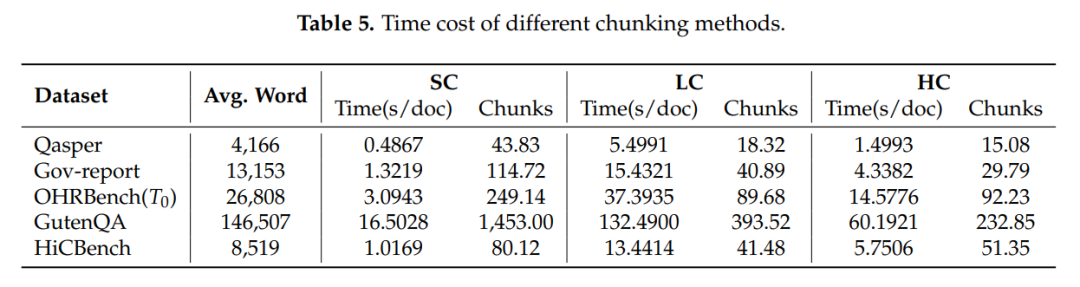
检索 Token 预算的影响
结果表明,更大的检索 Token 预算通常能带来更优的响应质量,因此在相同的检索 Token 预算下对比不同分块方法十分必要。在各种检索 Token 预算设置下,HC200+AM 方法始终保持着更优的响应质量,这些实验结果进一步证实了 HC200+AM 方法的有效性。
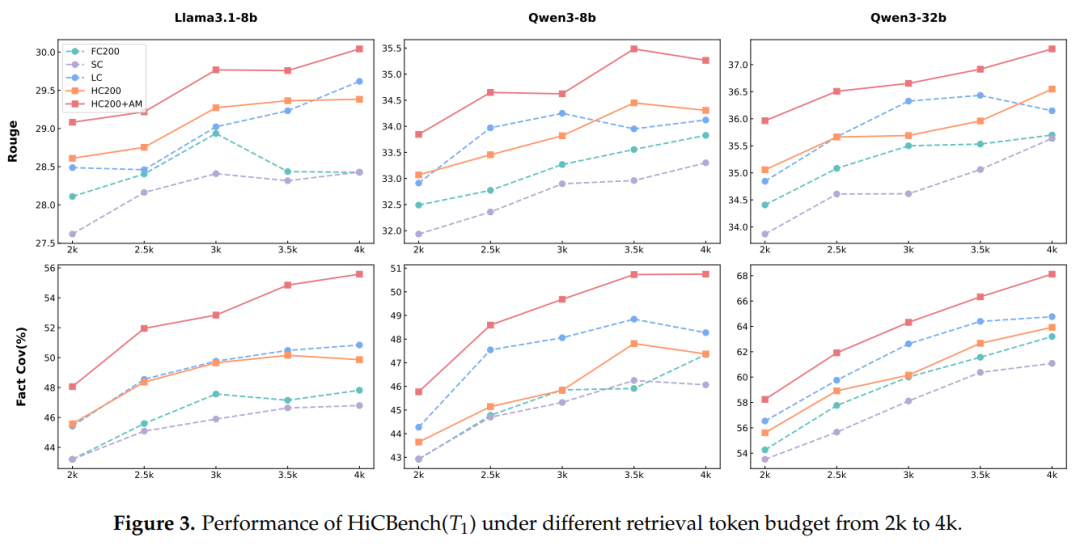
文档结构最大层级的影响
文档结构的最大层级范围设为 1 至 4,分别记为 L1 至 L4;其中 LA 代表不限制最大层级。通过实验验证HiChunk 所得到的文档结构最大层级对实验结果的影响。
结果显示,在L1设置下(即仅保留第 1 层级分块),由于分块的语义粒度过于粗糙,自动合并(Auto-Merge)检索算法会导致 RAG 系统性能下降;当最大层级从 1 增加到 3 时,证据召回率指标逐渐提升,且在层级达到 3 之后基本保持稳定。这些结果凸显了文档层级结构对提升 RAG 系统性能的重要性。
五、总结
HiChunk不只是一个技术框架,更给RAG落地提供了明确方向:
- 分块要“懂结构”:别再只盯着“固定长度”或“句子相似度”,优先利用文档的天然层级(章节、标题),HiChunk的分层思路可直接参考;
- 检索要“动态调”:Auto-Merge算法的核心是“按需合并”,在设计检索逻辑时,可加入“子块数量”“Token预算”等条件,平衡召回率和冗余度;
- 场景优先选“密集证据”:HiChunk在企业知识库、学术问答、法律文档检索等“需要完整语义块”的场景中价值最大,可优先落地这些场景;
- 性能指标看“双维度”:评估RAG产品时,别只看“回答准确率”,还要加“分块完整性”(比如HiCBench的Fact-Cov指标),避免“分块差导致的准确率低”被误判为“检索器不行”。
过去做RAG,很多人把精力放在“检索器怎么调”“大模型怎么换”上,却忽略了“分块”这个基础环节。HiChunk的价值在于:它让“分块”从“无差别切割”变成了“有结构的语义组织”,让RAG的每一步都更“精准”。
对行业来说,这可能是一个信号:RAG的竞争正在从“堆模型、堆数据”走向“精细化优化”——谁能把分块、检索、生成的每个环节都打磨到位,谁就能做出更实用的AI产品。
最后,附上论文和项目地址,感兴趣的同学可以深入研究:
复制

