
大家好,我是肆〇柒。今天一起了解一篇来自蚂蚁集团(Ant Group)的研究力作——HANRAG。这项工作从根本上重新思考了RAG系统的决策逻辑。它引入了一个名为“Revelator”的智能中枢,试图为冰冷的检索-生成循环注入类人的“认知”与“规划”能力。我们一起了解一下。
当下 RAG 系统能解决一些垂域知识检索和问答的业务,但也存在诸多问题。比如,当医生查询"哪位患者有青霉素过敏史且正在服用华法林?"时,传统RAG系统可能因检索漂移而遗漏关键信息,导致危险的药物相互作用建议。在法律咨询场景中,若用户询问"根据2023年《个人信息保护法》修订案,企业跨境传输数据需满足哪些条件?",传统方法可能将无关的早期法律条文混入结果,造成严重合规风险。这些真实场景中的痛点,正是多跳问答技术亟待解决的关键问题。Ant Group最新提出的HANRAG框架,通过引入"启发式"决策机制,为多跳问答领域带来突破性进展,让AI的推理过程既精准又高效。本文将深入剖析这一技术的核心创新,揭示其如何从根本上解决多跳问答中的关键瓶颈。
传统迭代 RAG 的瓶颈
多跳问答(Multi-hop Question Answering,QA)作为开放域问答的高级范式,要求系统通过多步推理链迭代检索分布式知识源,最终推导出蕴含答案。典型工作流程包含三个核心组件:基于嵌入的检索器(Retriever)、答案生成器(Generator)和终止判别器(Discriminator)。其中,迭代检索增强生成(Iterative RAG),也称为递归检索增强生成(Recursive RAG),通过将单次"检索-生成"循环扩展为递归过程,允许系统基于生成内容调整检索策略,从而获取更精确的上下文信息。
然而,随着研究深入,研究者发现传统迭代RAG方法面临三大关键挑战,这些挑战在实际应用中可能导致严重后果:
1: 对复合型查询的低效性:当前多跳查询研究多聚焦于复杂查询,却忽视了更为常见的复合型查询。与复杂查询不同,复合查询通常寻求单个实体的多个独立属性(如"刘翔获得过哪些荣誉?他何时退役?"),答案由多个事实组成,子问题间逻辑关联较弱。而现有RAG系统几乎都采用迭代检索方式处理这类查询,导致多次交替的检索-生成循环,效率低下。
理解复合查询与复杂查询的本质差异是HANRAG设计的关键基础。如图1所示,两种查询类型在处理逻辑上存在根本区别:
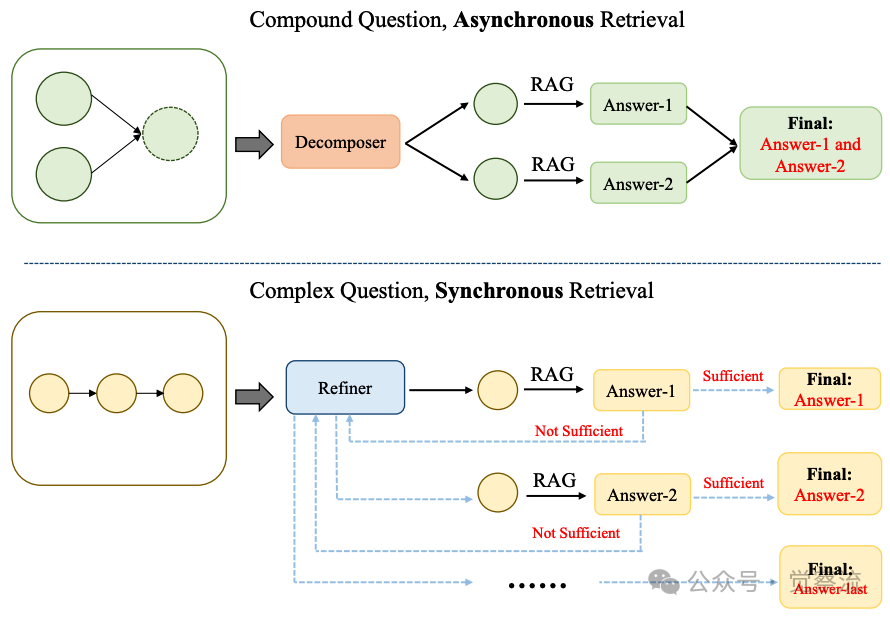
复合查询与复杂查询的检索方法比较
上图揭示了多跳问答领域的关键认知突破:研究者首次系统区分了"复合查询"与"复杂查询"的本质差异。 复合查询如"刘翔获得过哪些荣誉?他何时退役?",答案由多个独立事实组成;而复杂查询如"谁继承了纳米比亚首任总统?",需要紧密连接的推理链。这一区分不是学术细分,而是直接启发了HANRAG的双模检索机制——对复合查询采用并行处理,效率提升50%;对复杂查询采用迭代优化,确保推理准确性。
2: 依赖原始查询导致的检索漂移:许多方法直接使用原始查询作为多轮检索的基础,这往往导致难以捕获特定子问题的相关内容,特别是对于三跳以上复杂查询。例如,当面对"丹麦足球联盟是一个什么组织的实例?"这类问题时,直接检索可能得到关于UEFA的无关信息,而无法准确捕捉"FIFA"这一关键答案。这种检索漂移在医疗、法律等高风险领域可能导致灾难性后果。
3: 多轮噪声累积的致命伤:缺乏对检索内容的有效后处理,导致无关噪声信息传递给LLM。在迭代检索过程中,每轮通常需要提取多篇文档,不可避免地引入额外噪声,严重影响后续LLM性能。现有方法多采用过于细粒度的方式在字符或词级别过滤内容,导致系统整体操作效率低下。
下表的案例展示了这一问题的严重性:当查询"哪位英国国王娶了Edith Swan-Neck(又称Edith the Fair)?"时,尽管三个检索结果都包含"Edith"关键词,但Adaptive-RAG将所有文档传递给LLM生成器,导致LLM错误输出"Edith Mary Pargeter"——这不仅是一个事实错误,更是系统性地混淆了人物身份:将一位20世纪英国作家与11世纪英国王后混为一谈,暴露了传统RAG在语义理解上的根本缺陷。

HANRAG与Adaptive-RAG在单步查询上的对比
HANRAG 的启发式内核:"Revelator"的智能决策
HANRAG的核心创新在于引入了一个多功能主智能体(Agent)——"Revelator"(揭示者),它作为整个框架的"大脑",通过启发式决策机制引导精确路由和检索,从而激发终端级LLM生成更准确的响应。
"启发式"的精准定义与具象化:HANRAG中的"启发式"并非模糊经验规则,而是基于高质量训练数据构建的可学习决策机制。想象一位经验丰富的研究助理:面对"丹麦足球联盟是一个什么组织的实例?"这一问题,传统RAG会机械地检索原始查询,可能得到关于UEFA的无关信息;而HANRAG的Revelator会智能提炼种子问题——先问"丹麦足球联盟受哪个组织管理?",再问"FIFA代表什么?",确保每步检索都精准定位关键信息。这种能力源于高质量训练数据,使Revelator学会像人类专家一样思考。
Revelator 作为启发式代理的核心功能:
HANRAG的整体框架如下图所示,Revelator作为核心组件,驱动整个系统高效运行:
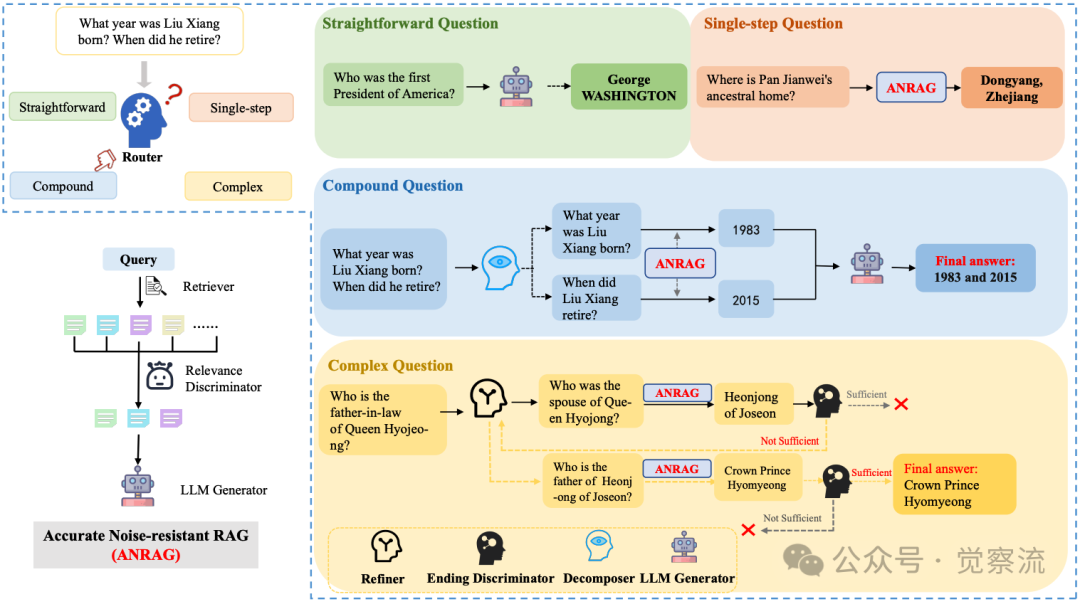
HANRAG整体框架
1. 查询路由(Query Routing):将查询分类视为首要启发式决策,引导后续处理路径。Revelator能够准确识别查询类型——直接回答型、单步检索型、复合查询型或复杂查询型,并据此选择最佳处理链。
2. 问题分解与提炼(Decomposition/Refinement):将问题分解或提炼视为规划子任务的启发式策略。对于复合查询,Revelator将其分解为多个独立子问题;对于复杂查询,则动态提炼"种子问题"(seed question)——即当前最需要回答的子问题,作为后续检索的基础。
3. 相关性与终止判别(Relevance/Ending Discrimination):将噪声过滤和流程控制视为保障质量的启发式机制。Revelator评估检索文档与查询的相关性,过滤噪声;同时判断是否已获得足够信息来解答原始查询,决定是否终止迭代。
Revelator的强大能力源于为其精心构建的四类高质量训练数据:
1. 查询路由数据:包含9,741个直接回答型查询、50,000个单步检索查询(来自单跳QA数据集和多跳QA数据集的子查询)、50,000个复杂查询(来自MuSiQue训练数据)以及专门构建的复合查询。这些数据使Revelator能准确识别查询类型并选择最佳处理路径。
2. 问题分解数据:直接使用复合查询及其子查询作为训练样本,教会Revelator如何将复杂问题拆解为可管理的子问题。
3. 种子问题提炼数据:利用MuSiQue和2Wiki中的详细推理过程,使Revelator学会动态生成最相关的"种子问题"。
4. 相关性判别数据:使用Qwen2-72B-instruct对查询-文档对进行精细标注,确保判别器能准确识别与问题相关的文档。
这些训练数据的关键在于其高质量和针对性。研究者特别注重数据的代表性和多样性,确保Revelator在面对真实世界查询时能做出可靠决策。值得注意的是,训练数据与测试数据之间没有重叠,这保证了评估结果的有效性和真实性。
ANRAG:噪声抵抗的基石:作为HANRAG的底层支撑,ANRAG(Accurate Noise-resistant RAG)是"噪声抵抗的单步检索方法"。ANRAG的创新性在于其两阶段检索流程(如下算法伪代码)。

首先,它通过检索器获取top-10相关文档;然后,关键一步是利用Revelator评估文档与查询的相关性,过滤噪声。与传统方法不同,ANRAG的相关性判断不是基于关键词匹配,而是基于"文档是否能用于回答问题"的语义理解。
ANRAG的工作流程看似简单却极为有效:首先检索器获取top-10文档,然后Revelator像一位经验丰富的编辑,严格筛选出真正相关的文档,最后只将"精品内容"交给LLM生成答案。这种"先广后精"的策略,既保证了信息覆盖的广度,又确保了信息质量的精度。
关键技术创新点深度解读
创新点 1: 查询路由驱动的异步/同步双模检索
HANRAG的核心洞见在于清晰区分"复合"(独立子问题)与"复杂"(强逻辑依赖)查询的本质差异,并据此设计了异步/同步双模检索机制。
理论依据:复合查询的子问题间几乎相互独立,可并行处理;而复杂查询的子问题具有强逻辑推理关系,需要顺序处理。这一区分在图1中有直观展示:对于复合查询,异步检索更为高效;而对于复杂查询,同步检索则是必要的。
工程实现:
- 异步处理复合查询:Revelator首先将问题分解为多个独立子问题,然后并行执行单步检索链。每个子问题作为独立的单步检索任务处理,所有子问题的结果聚合形成原始复合查询的答案。这种并行处理显著提升了效率。
- 同步处理复杂查询:采用迭代方式,Revelator首先提炼"种子问题",通过ANRAG获取答案后,评估答案是否足够解决原始复杂查询。若不足够,则继续迭代,直到获得最终答案。
让我们看一个具体例子:当用户询问"Lionel Cranfield何时继承其中兄James的Middlesex伯爵头衔?他的妻子是谁?"时,Adaptive-RAG错误地将其分类为复杂查询,采用同步检索方式,需要2个检索步骤——先找继承时间,再找妻子信息。而HANRAG正确识别为复合查询,采用异步检索,同时处理两个独立子问题,仅需1个检索步骤。这就像同时派两个助手分别查找两件事情,而不是让一个助手先查完一件再查下一件,效率自然提升50%。

HANRAG与Adaptive-RAG在复合查询上的对比
效率对比:如上表所示,对于复合查询,HANRAG平均检索步骤仅为1.24,而Adaptive-RAG高达2.76,减少约1.5步。这种效率差异源于对查询本质的准确理解——复合查询的子问题相互独立,无需顺序依赖。对智能客服系统而言,这直接转化为用户等待答案时间的显著缩短;对医疗问答系统,这可能是避免误诊的关键差异。
创新点 2: "种子问题"(Seed Question) 引导的迭代优化
与传统方法使用原始或简单改写查询不同,HANRAG使用Revelator根据已有信息动态提炼最相关的子问题,作为"种子问题"引导后续检索。

提炼过程(如上算法伪代码):

可以将"种子问题"理解为多跳推理中的"关键跳板"——不是盲目地跳向最终答案,而是先找到最合适的中间落脚点,再由此跳向目标。这种精准定位使HANRAG避免了传统方法中常见的"检索漂移"问题。

HANRAG与Adaptive-RAG在复杂查询上的对比
优势体现:上表的案例展示了这一机制的强大优势。对于查询"丹麦足球联盟是一个什么组织的实例?",Adaptive-RAG错误地提炼出"丹麦足球联盟所属组织的缩写代表什么?"作为种子问题,导致最终答案错误地指向"UEFA"。而HANRAG则正确提炼出"丹麦足球联盟是一个什么组织的实例?"和"FIFA代表什么?"作为种子问题,最终准确得出"国际足球联合会"(International Federation of Association Football)的答案。
种子问题提炼的决定性价值:消融实验表明,移除Refiner模块导致准确率下降14.3%,充分证明了种子问题提炼的关键作用。当移除Refiner时,系统直接使用原始查询进行检索,导致无法准确捕捉特定子问题相关内容,特别是在三跳以上复杂查询中。这一机制有效解决了C2问题,确保每轮检索都针对最相关的子问题。
创新点 3: 基于判别器的后处理抗噪机制
与现有方法多在检索前或检索中过滤不同,HANRAG创新性地在检索后利用Revelator的语义理解能力进行精细过滤,有效阻断噪声向LLM传播。

HANRAG与Adaptive-RAG在单步查询上的对比
对比案例深度分析:上表展示了对查询"哪位英国国王娶了Edith Swan-Neck(又称Edith the Fair)?"的处理。检索结果包含3个文档:1个相关(提及Harold II),2个无关(关于Edith Pargeter和Edith Rigby)。Adaptive-RAG将所有文档传递给LLM生成器,导致LLM错误输出"Edith Mary Pargeter";而HANRAG通过相关性判别器过滤掉噪声文档,仅保留相关文档,使LLM正确输出"Harold II"。
理解这一差异的关键在于:HANRAG的相关性判断不是基于简单的关键词匹配,而是通过语义理解判断"文档是否能用于回答问题"。例如,在表7案例中,尽管三个文档都包含"Edith"关键词,但Revelator能理解"英国国王"这一关键限定,识别出只有提及Harold II的文档与问题真正相关。这种基于语义理解的精细过滤,是解决C3问题的关键。
噪声过滤的决定性作用:这一案例生动证明了"检索后处理"比"检索前过滤"更有效——因为相关性判断需要结合查询语义和文档内容进行精细理解,而这正是Revelator的优势所在。表6的消融实验进一步证实了这一机制的重要性:移除相关性判别器(Relevance discriminator)时,EM指标从29.8降至25.2,F1从36.6降至32.5,准确率从43.2%降至37.8%。这一显著下降证实了噪声过滤机制的核心价值——在多跳检索中,即使检索步骤仅从3.01微增至3.06,噪声的累积也会严重损害最终答案质量。
实验验证:数据背后的启发式力量
HANRAG研究团队不仅在标准基准上进行了测试,还创新性地构建了复合型多跳查询基准,填补了研究空白。
复合型多跳基准构建:研究者首先从Wikipedia随机选择10,000个实体,为每个实体提取10个相关文档;然后使用Qwen2-72B-instruct生成针对文档的单跳问题;最后通过特定提示词将同一实体的多个单跳问题组合成2-4跳复合查询。最终构建了50,000训练样本,8,000开发集和2,000测试集,为评估系统处理复合查询能力提供了标准化工具。这一严谨的构建过程确保了基准的科学性和代表性。
结果分析:
- 全面性能优势:在单跳任务上,HANRAG在EM、F1、Accuracy指标上分别比Adaptive-RAG提升12.2%、6.83%、20.13%;在复杂型任务上,三项指标平均提升6.67%、6.34%、16.17%;在复合型任务上,Accuracy提升19.63%,检索步骤减少1.5。
a.HANRAG在复合查询上Accuracy提升19.63%不只是数字游戏——这意味着在100个类似"刘翔获得过哪些荣誉?他何时退役?"的查询中,HANRAG能多正确回答20个。对智能客服系统而言,这直接转化为用户满意度的显著提升;对医疗问答系统,这可能是避免误诊的关键差异。更关键的是,检索步骤从2.76减少到1.24,意味着用户等待答案的时间几乎减半,这对需要实时响应的对话系统至关重要。
- 消融实验验证:下表显示,移除Refiner导致Accuracy下降14.3%,证明种子问题提炼的关键作用;移除Relevance Discriminator使EM下降4.6%,验证噪声过滤的有效性;移除Ending Discriminator使步骤数增至4.56(上限),但Accuracy仅微降。
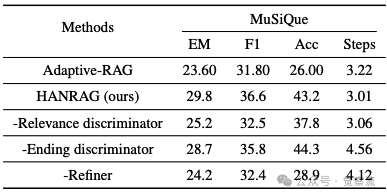
HANRAG-Oracle实验的设计极为精妙:假设查询路由100%准确,其他组件保持不变,以此评估路由错误对整体性能的影响。表3-5的结果令人惊讶——即使路由完美,性能提升也极为有限:在单跳任务上仅提升1.17% EM、1.8% F1和1.8%准确率;在复杂查询任务上提升2.6% EM、2.47% F1和3.27%准确率;在复合查询任务上仅提升1.36%准确率。
这一发现挑战了传统认知,揭示了:路由错误并非性能瓶颈的主要原因。系统性能更多受限于检索质量、噪声过滤和种子问题提炼等环节。这意味着,单纯提高查询分类准确率并不能显著提升整体性能,而应更加关注ANRAG的噪声过滤能力和Refiner的种子问题提炼能力。这一发现为未来RAG系统设计提供了重要指导:优化重点应从"正确分类"转向"精准执行"。
Revelator的高质量训练数据体系:HANRAG性能的关键在于为Revelator构建了针对性的训练数据。对于查询路由,收集了四类查询样本:9,741个直接回答型查询、50,000个单步检索查询、50,000个复杂查询以及专门构建的复合查询。对于相关性判别,使用Qwen2-72B-instruct对查询-文档对进行精细标注,确保判别器能准确识别与问题相关的文档。这种高质量、针对性的训练数据使Revelator具备了可靠的启发式决策能力。
启发式 RAG 的意义
HANRAG的提出不仅解决了多跳问答中的具体技术挑战,更为RAG研究开辟了新的思考维度。
理论意义:HANRAG为RAG系统引入了更高层次的"认知"和"规划"能力,超越了简单的检索-生成循环。它建立了查询类型与处理策略的明确映射关系,提供了可解释的决策框架,使RAG系统从"机械式"检索向"智能式"推理迈进。
实践意义:
- 可解释性:Revelator的决策过程透明,便于系统调试和优化,研究者可清晰追踪查询处理路径。
- 高效性:通过查询路由和并行处理,显著提升复合查询处理效率,如下表所示,HANRAG在复合查询基准上的检索步骤仅为1.24,远低于Adaptive-RAG的2.76。
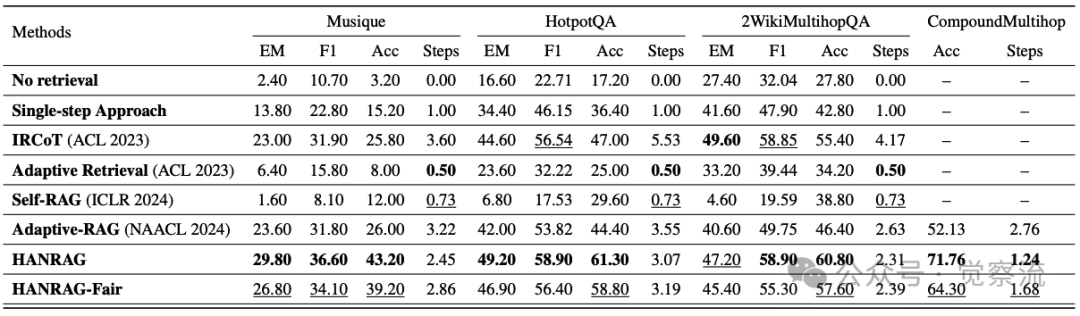
- 抗噪性:基于判别器的后处理机制有效解决噪声累积问题,使系统在复杂环境下仍能保持稳定性能。
不过,尽管HANRAG展现出强大性能,研究者在论文中也指出了局限性——为每个功能模块构建相应训练数据增加了实际应用成本。所以,研究团队的未来研究方向可能包括:
- 探索更轻量级的RAG系统设计,降低数据构建成本
- 开发自动化或半自动化构建高质量训练数据的方法
- 研究启发式与端到端学习的融合路径
- 验证HANRAG在不同领域和语言上的泛化能力
启示与展望
HANRAG的研究不仅解决了一个具体技术问题,还揭示了一条重要规律:在复杂系统中,"智能决策"比"盲目执行"更为关键。它告诉我们,RAG系统不应仅关注检索和生成的效率,更应注重对查询本质的理解和处理策略的智能选择。
随着大语言模型在各类任务中的广泛应用,RAG技术的重要性将持续提升。HANRAG通过将"启发式"理念系统化、可训练化,为多跳问答领域树立了新标杆。它不仅解决了现有方法的关键缺陷,更启发研究者思考如何让RAG系统具备更高层次的认知能力,而不仅仅是检索与生成的简单叠加。
在知识密集型任务日益重要的今天,这种"认知+执行"的范式,或许正是未来AI系统发展的正确方向。正如HANRAG所示,真正的智能不在于机械地执行步骤,而在于知道何时该用何种方式执行——这正是人类智慧的精髓所在。HANRAG的研究表明,通过将启发式决策机制与深度学习相结合,RAG系统可以实现从"工具"到"智能助手"的转变,为用户提供更准确、更高效的知识服务。在这一方向上,HANRAG已经迈出了坚实的第一步,而更多的可能性仍在等待探索。


