图片
图片
引言
聊天机器人的进步
近期生成式AI的进展显著增强了聊天机器人的能力。这些由生成式人工智能驱动的聊天机器人在各个行业中的应用正在被探索[Bahrini等人,2023年;Castelvecchi,2023年;Badini等人,2023年],其中制药行业是一个显著的关注领域。在药物发现领域,最近的研究表明,由生成式人工智能驱动的聊天机器人在推进药物发现方面可以发挥重要作用[Wang等人,2023年;Savage,2023年;Bran等人,2023年]。这样的进步不仅简化了发现过程,而且为聊天机器人提出新的研究想法或方法铺平了道路,增强了研究的协作性。在医疗保健领域,聊天机器人在提供个性化支持方面被证明特别有效,这可以带来更好的健康结果和更有效的治疗管理[Ogilvie等人,2022年;Abbasian等人,2023年]。这些聊天机器人可以提供及时的用药提醒、传递有关潜在副作用的信息,甚至协助安排医生咨询。
聊天机器人对药物监管指导的需求
在制药行业中,另一个可以充分利用生成式人工智能的关键领域是确保符合监管指南的要求。对于行业从业者来说,应对像美国食品药品监督管理局(FDA)和欧洲药品管理局(EMA)等机构提供的复杂而广泛的指南通常是一项令人生畏且耗时的任务。大量的指导方针,加上其复杂的细节,可能使公司难以快速找到并应用相关信息。这通常导致成本增加,因为团队花费宝贵的时间浏览庞大的指导方针资料库。最近的一项研究强调了遵守监管指导方针的财务影响[Crudeli, 2020]。研究发现,合规工作可能消耗掉中型或大型制药制造运营预算的25%。鉴于这些挑战,制药行业需要一种更高效的方法来导航和解释监管指导方针。大型语言模型(LLMs)可以有助于解决这个问题。然而,尽管它们经过了广泛的预训练,LLMs在获取未包含在其初始训练数据中的知识时常常遇到固有的限制。特别是在高度专业化和详细的制药监管合规领域,很明显这种特定领域的知识并未完全包含在训练材料中。因此,LLMs可能不足以准确回答该领域的问题。
检索增强生成(RAG)模型作为连接这一差距的桥梁而脱颖而出。它不仅利用了这些模型的内在知识,还从外部来源获取额外信息以生成响应。如[Wen等人,2023年]和[Yang等人]的工作所示,RAG框架能够做到这一点。[2023年]的研究展示了如何巧妙地将丰富的背景资料与答案相结合,确保对查询进行全面准确的回应。这些研究突显了RAG在多种应用中的多功能性,从复杂故事的生成到定理的证明。
此外,有证据表明,RAG模型在典型的序列到序列模型和某些检索与提取架构中表现卓越,特别是在知识密集型的自然语言处理任务中。尽管RAG取得了进步,但我们认识到,传统RAG方法在监管合规领域的准确性可能不足,该领域需要特定领域的、高度专业化的信息。因此,我们引入了问答检索增强生成(QA-RAG)。QA-RAG模型专为需要专业知识的高度特定领域设计,它精确地将监管指南与实际实施对齐,简化了制药行业的合规流程。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何在制药行业中利用生成式AI和检索增强生成(RAG)方法来提高监管合规的效率和准确性。
- 研究难点:该问题的研究难点包括:制药行业监管指南的复杂性和详尽性,传统RAG方法在处理高度专业化信息时的局限性,以及如何在保证准确性的同时提高检索效率。
- 相关工作:该问题的研究相关工作包括生成式AI在药物发现和医疗保健中的应用,RAG模型在复杂故事生成和定理证明中的应用,以及在知识密集型NLP任务中的优势。
研究方法
这篇论文提出了QA-RAG模型用于解决制药行业监管合规问题。具体来说,
- 整体结构:QA-RAG模型利用微调后的LLM代理提供的答案和原始查询来检索文档。一半的文档通过微调后的LLM代理提供的答案获取,另一半通过原始查询获取。然后,系统对检索到的文档进行重新排序,只保留与问题最相关的文档。
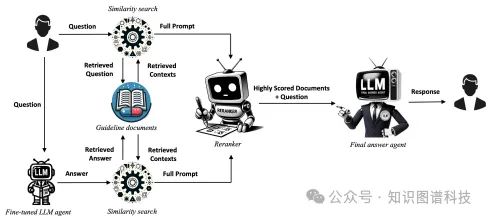
- 文档预处理和相似性搜索:使用密集检索方法(如Facebook AI Similarity Search, FAISS)来提取文档。文档通过OCR技术转换为文本,并分割成多个块。使用LLM嵌入器对文档进行嵌入。
- 双轨检索:结合微调后的LLM代理的答案和原始查询进行文档检索。这种方法不仅扩大了搜索范围,还捕捉了更广泛的相关信息。
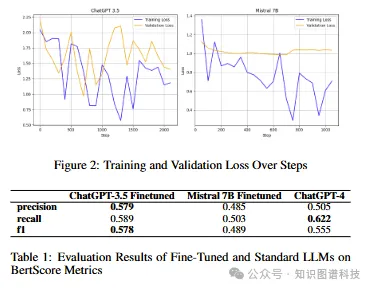
- 微调过程:使用FDA的官方问答数据集进行微调。选择了ChatGPT 3.5- Turbo和Mistral-7B作为基础LLM模型。微调过程中使用了LoRA技术来高效地调整模型参数。
- 重新排序:使用BGE重新排序器对检索到的文档进行重新排序,评估每个文档与查询的相关性,并保留相关性最高的文档。
- 最终答案生成:使用ChatGPT-3.5- Turbo模型作为最终答案代理,通过少样本提示技术生成最终答案。
实验设计
- 数据集:使用FDA的官方问答数据集进行微调,共收集到1681个问答对。数据集分为训练集(85%)、验证集(10%)和测试集(5%)。
- 实验设置:在实验中,固定每次检索的文档数量为24个,并在后处理阶段筛选出前6个最相关的文档。比较了不同方法在上下文检索和答案生成方面的性能。
- 基线选择:包括仅使用原始查询的方法、多查询问题和HyDE方法等。
结果与分析
 图片
图片
- 重新排序与评分代理的比较:重新排序器在上下文精度和召回率方面几乎在所有方法中都优于评分代理,表明重新排序器在准确识别相关文档方面的优势。
- 上下文检索性能评估:QA-RAG模型结合了微调后的LLM代理的答案和原始查询,实现了最高的上下文精度(0.717)和召回率(0.328)。HyDE方法的性能次之,而仅使用原始查询的方法表现最差。
- 答案生成性能评估:QA-RAG模型在精度(0.551)、召回率(0.645)和F1分数(0.591)方面均表现出色,接近于上下文检索性能的前三名。
- 消融研究:仅使用假设答案的方法在上下文精度上略低于完整模型,但显著高于仅使用原始查询的方法。这表明假设答案在提高精度方面的关键作用。
伦理声明
在QA-RAG模型的开发和应用中,我们强调其作为医药领域专业人士的补充工具的作用。虽然该模型提高了导航复杂指南的效率和准确性,但其设计目的是增强而非取代人类的专业知识和判断。
用于训练和评估模型的数据集包括来自美国食品药品监督管理局(FDA)和国际人用药品注册技术协调会(ICH)的公开可访问文档,并遵守所有适用的数据隐私和安全协议。
总体结论
这篇论文提出的QA-RAG模型在制药行业监管合规领域展示了其有效性。通过结合生成式AI和RAG方法,QA-RAG模型能够高效地检索相关文档并生成准确的答案。该模型不仅提高了合规过程的效率和准确性,还减少了对人类专家的依赖,为未来在制药行业及其他领域的应用奠定了基础。未来的研究应继续评估和改进该模型,以应对不断变化的数据和行业实践。
论文评价
优点与创新
- 显著提高了准确性:QA-RAG模型在对比实验中展示了显著的准确性提升,超过了所有其他基线方法,包括传统的RAG方法。
- 结合了生成式AI和RAG方法:该模型巧妙地将生成式AI与检索增强生成(RAG)方法结合,利用生成式AI的强大生成能力和RAG方法的检索能力。
- 针对领域高度定制化:QA-RAG模型专为制药行业的高度专业化领域设计,能够精确地将监管指南与实际实施对齐,简化了合规流程。
- 双重检索机制:通过结合用户问题和微调后的LLM生成的假设答案进行文档检索,扩大了搜索范围并捕捉了更广泛的相关信息。
- 细调后的LLM:使用在特定领域数据上细调的LLM生成假设答案,显著提高了检索文档的精度和准确性。
- 多种评估指标:采用了Ragas框架和BertScore等多种评估指标,全面评估了上下文检索和答案生成的准确性。
- 公开可用:研究团队将工作公开发布,以便进一步研究和开发。
不足与反思
- 长期影响需要持续评估:像任何新兴技术一样,QA-RAG模型在各个行业的长期影响需要持续的评估和改进。
- 适应性和鲁棒性:需要确保模型在面对数据和行业实践的变化时保持适应性和鲁棒性。
- 模型性能的提升:未来的发展应继续关注提升模型的性能,确保其与不断发展的生成式AI技术保持同步。
- 伦理声明:开发和应用QA-RAG模型时,强调其作为专业人员的补充工具的角色,旨在增强而非取代人类的专业知识和判断。
关键问题及回答
问题1:QA-RAG模型在文档检索过程中如何利用生成式AI和RAG方法?
QA-RAG模型采用了双轨检索策略,结合了生成式AI和RAG方法。具体步骤如下:
- 文档预处理和相似性搜索:使用密集检索方法(如Facebook AI Similarity Search, FAISS)来提取文档。文档通过OCR技术转换为文本,并分割成多个块。使用LLM嵌入器对文档进行嵌入。
- 双轨检索:结合微调后的LLM代理的答案和原始查询进行文档检索。一半的文档通过微调后的LLM代理提供的答案获取,另一半通过原始查询获取。这种方法不仅扩大了搜索范围,还捕捉了更广泛的相关信息。
- 重新排序:系统对检索到的文档进行重新排序,只保留与问题最相关的文档。使用BGE重新排序器对检索到的文档进行重新排序,评估每个文档与查询的相关性,并保留相关性最高的文档。
问题2:在QA-RAG模型中,微调后的LLM代理在文档检索和答案生成中的作用是什么?
- 文档检索:微调后的LLM代理生成的假设答案被用于检索文档。具体来说,一半的文档通过微调后的LLM代理提供的答案获取,另一半通过原始查询获取。这种方法不仅扩大了搜索范围,还捕捉了更广泛的相关信息。
- 答案生成:最终答案通过少样本提示技术生成,使用ChatGPT-3.5- Turbo模型作为最终答案代理。微调后的LLM代理在生成假设答案时,能够提供与制药监管指南高度相关的信息,从而指导后续的文档检索和最终答案的生成。
问题3:QA-RAG模型在实验中表现如何,与其他基线方法相比有哪些优势?
- 上下文检索性能:QA-RAG模型结合了微调后的LLM代理的答案和原始查询,实现了最高的上下文精度(0.717)和召回率(0.328)。相比之下,HyDE方法的性能次之,而仅使用原始查询的方法表现最差。
- 答案生成性能:QA-RAG模型在精度(0.551)、召回率(0.645)和F1分数(0.591)方面均表现出色,接近于上下文检索性能的前三名。
- 重新排序与评分代理的比较:重新排序器在上下文精度和召回率方面几乎在所有方法中都优于评分代理,表明重新排序器在准确识别相关文档方面的优势。
- 消融研究:仅使用假设答案的方法在上下文精度上略低于完整模型,但显著高于仅使用原始查询的方法。这表明假设答案在提高精度方面的关键作用。
总体而言,QA-RAG模型通过结合生成式AI和RAG方法,显著提高了制药行业监管合规的效率和准确性,减少了对人类专家的依赖。