
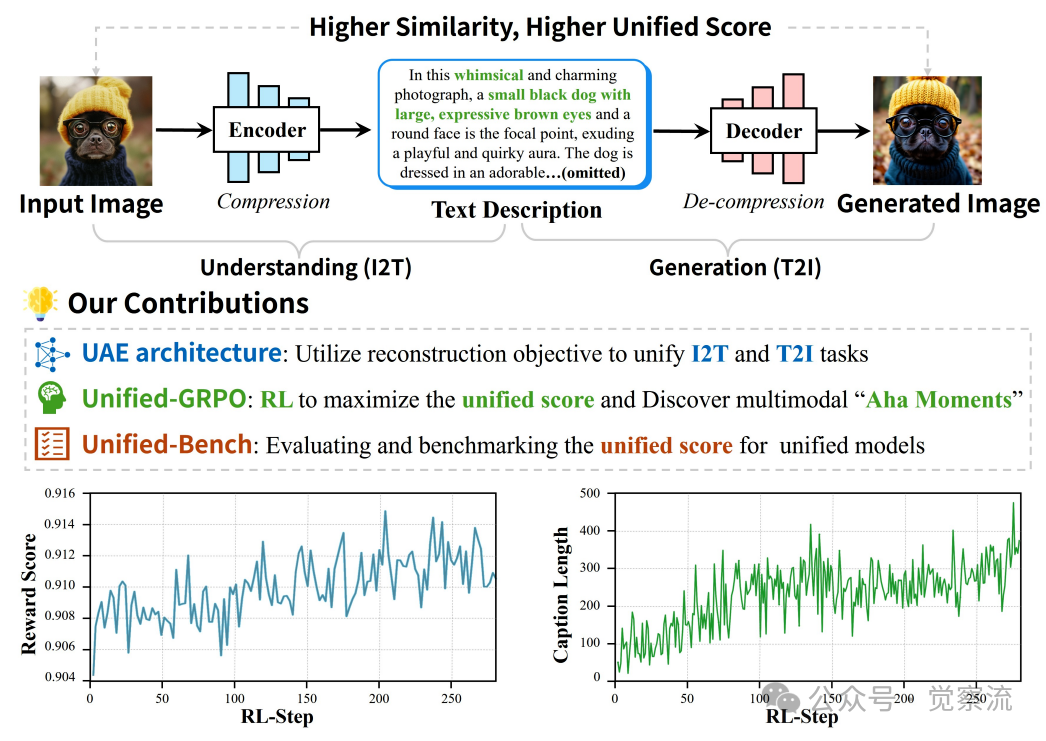
大家好,我是肆〇柒。今天这篇论文是一项来自北京大学与百度ERNIE团队的研究。面对当前多模态模型“理解”与“生成”模块貌合神离、甚至相互拖后腿的行业困局,这支研究团队另辟蹊径,提出了一种名为UAE的全新框架,不仅让二者真正“统一”,更催生了令人振奋的“啊哈时刻”。
当你上传一张戴着黄色针织无檐便帽、佩戴黑色框架眼镜的小黑狗照片时,大多数"统一"多模态模型会犯下三类典型错误:(i)将小黑狗误识别为猴子,导致生成错误物种;(ii)描述遗漏关键物品(豆豆帽、眼镜)或将服装颜色错配,导致重建结果扭曲;(iii)场景描述不足,无法在推理时保持一致的摄影风格。这些错误揭示了一个残酷现实:当前所谓的"统一多模态模型"(UMMs)大多只是将理解与生成两个独立训练的模块并排放置,而非真正实现能力的相互促进。近期发表的论文《Can Understanding and Generation Truly Benefit Together -- or Just Coexist?》直指这一行业痛点,不仅证明了理解与生成可以且必须相互成就,更通过实证展示了"啊哈时刻"(Aha Moment)的降临——当理解能力提升时,生成质量同步飞跃,反之亦然。本文将深入剖析这一开创性工作,揭示多模态统一的本质路径。
多模态统一的"皇帝新衣"

Unified-Bench案例研究
上图:Unified-Bench案例研究。 评测使用四种视觉编码器(CLIP、LongCLIP、DINO-v2、DINO-v3)计算统一分数,确保对比学习和自监督特征的全面评估。案例显示,UAE能避免三类典型错误:(i)类别漂移(将狗误识别为猴子);(ii)属性遗漏或错配;(iii)场景描述不足,从而实现高保真重建。
让我们从一个具体场景开始:当你上传一张小黑狗戴着黄色针织无檐便帽、佩戴黑色框架眼镜的照片,希望模型能准确理解并重建这一场景。当前大多数"统一"模型会犯下上图中展示的三类典型错误:(i)将小黑狗误识别为猴子,导致生成错误物种;(ii)描述遗漏关键物品或将服装颜色错配,导致重建结果扭曲;(iii)场景描述不足,无法保持一致的摄影风格。这些错误不仅影响用户体验,更揭示了当前多模态领域的一个核心问题:理解(I2T)与生成(T2I)任务在训练目标上割裂,甚至相互损害。
正如论文所尖锐指出的,"优化扩散生成目标会负面损害理解能力及学习表征(反之亦亦然),使联合训练变得脆弱"。这一现象迫使许多研究者不得不将两个任务解耦,分别训练理解与生成模块,从而"放弃潜在的跨任务收益"。这种割裂状态导致了一个尴尬的现实:理解模块可能擅长回答视觉问题,生成模块可能精于创作逼真图像,但二者之间缺乏内在联系。
想象一下两个人玩"传话游戏":如果只关注"我说了什么"或"你听到了什么",很容易出错;但如果目标是"确保最终听到的与最初说的一样",双方就会自然调整自己的表达和理解方式,形成默契。当前多模态研究的问题就在于,我们只关注了单向的"说"或"听",而忽略了"确保信息无损传递"这一终极目标。
小结一下:当前多模态领域存在理解与生成割裂的普遍问题,传统"统一"模型往往只是将两个独立模块并排放置。真正的统一需要一个能将二者"焊接"在一起的统一目标,使理解与生成相互成就。
自编码器——统一的"元架构"
论文提出的突破性洞见源于对自编码器(Auto-Encoder)原理的创造性应用。研究者将理解模块重新定义为"编码器"(Encoder),负责将图像压缩为富含语义的文本描述(I2T);将生成模块视为"解码器"(Decoder),负责根据该文本重建图像(T2I)。这一视角转变看似简单,实则解决了长期存在的理解与生成割裂问题。
自编码器视角的多模态理解与生成
上图:自编码器视角下的多模态理解与生成。 编码器将输入图像转换为详细描述,解码器基于该描述重建图像。重建相似度作为统一评分,通过Unified-Bench量化并由Unified-GRPO优化。
在这一框架下,重建保真度(Reconstruction Fidelity)成为衡量信息在"压缩-解压"过程中是否无损传递的黄金标准。论文明确指出:"训练系统使重建匹配输入——通过语义相似度评估——将双方绑定在一个单一目标下"。高保真重建意味着理解模块捕捉了所有关键信息,生成模块能完美解读并还原。
这种设计创造了理解与生成之间的共生关系:任务呈现对称互补性——编码器将视觉内容压缩为语义丰富的描述,解码器将该描述扩展回像素。成功的重建信号表明连贯的双向信息流和改进的视觉-语言对齐。随着统一训练的深入,编码器将自发产生更详尽的描述,解码器将同步进化出更强的解读能力,形成正向循环。这一现象——论文中称为"啊哈时刻"——将成为真正统一的实证标志。
一个直观类比:传话游戏的启示
想象两个人玩"传话游戏":如果只关注"我说了什么"或"你听到了什么",很容易出错;但如果目标是"确保最终听到的与最初说的一样",双方就会自然调整自己的表达和理解方式,形成默契。UAE框架正是基于这一思想:通过重建保真度作为统一目标,将理解与生成绑定在同一个闭环中。当理解模块输出的描述不够详细时,生成模块无法重建原始图像,这会反过来"惩罚"理解模块,迫使其提供更丰富的信息;同样,当生成模块无法准确解读描述时,理解模块也会调整其输出方式。这种双向反馈机制使两个模块在训练过程中自然形成默契,实现真正的统一。
关键发现:自编码器视角将理解与生成统一在一个重建目标下,解决了传统方法中理解与生成目标冲突的问题。成功的重建信号直接反映了"连贯的双向信息流和改进的视觉-语言对齐"。
Unified-GRPO工作流程
论文提出的Unified-GRPO(Unified Group Relative Policy Optimization)算法是实现这一自编码器框架的核心。该算法通过三个阶段逐步加强理解与生成的协同:
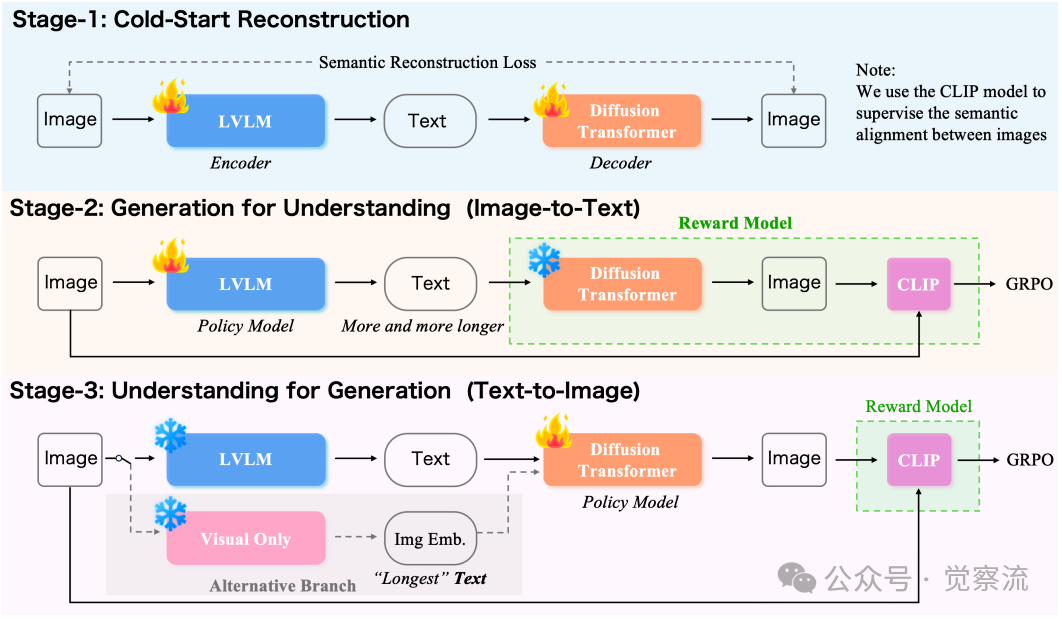
Unified-GRPO三阶段工作流程
上图:Unified-GRPO三阶段工作流程。 系统首先通过冷启动重建建立基础协作能力;然后进入"生成驱动理解"阶段,让编码器学习生成能最大化重建质量的描述;最后进入"理解驱动生成"阶段,微调解码器以更好地利用这些详细描述。
这三个阶段的设计理念类似于教孩子画画:先让他能简单临摹(冷启动重建),再逐步提高要求,让他学会准确描述所见(生成驱动理解),最后让他能根据详细描述精确绘制(理解驱动生成)。这种渐进式训练方法避免了传统联合训练的脆弱性,确保理解与生成能力的稳定协同进化。
本节小结:自编码器视角为多模态统一提供了理论基础,将理解与生成视为编码-解码过程的两个互补环节。重建保真度作为统一目标,使理解与生成能够相互促进,形成正向循环。
UAE框架:从冷启动到协同进化
基于上述洞见,研究者提出了UAE(Unified Auto-Encoder)框架,一个极简而高效的"编码器-连接器-解码器"设计。该框架的核心在于通过重建目标将理解与生成紧密耦合,而非简单堆叠两个独立模块。
架构设计:极简而高效
UAE采用三段式架构:基于Qwen-2.5-VL 3B的大型视觉-语言模型(Large Vision-Language Model, LVLM)作为理解编码器,轻量级MLP投影器作为连接器,以及SD3.5-large扩散变换器(Diffusion Transformer, DiT)作为生成解码器。
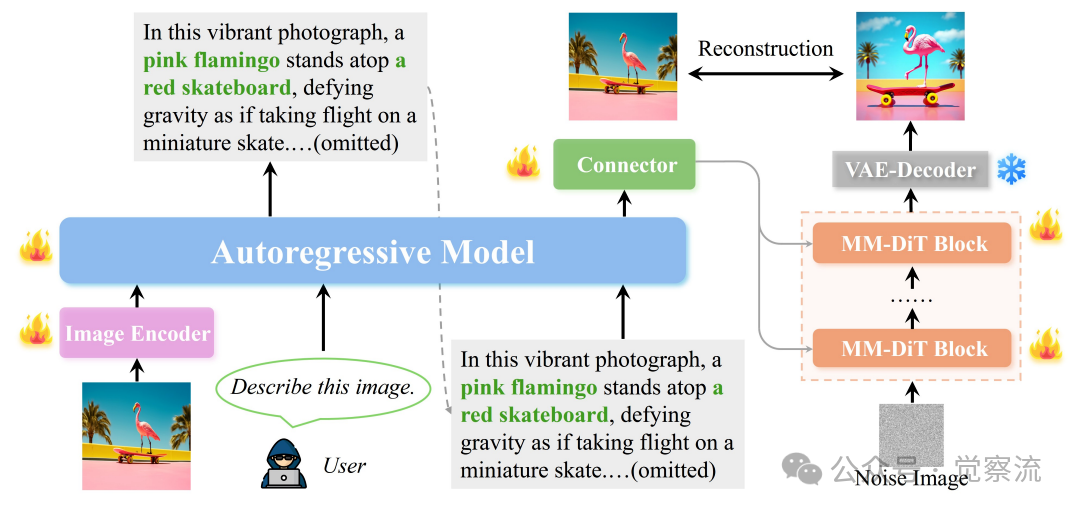
UAE框架设计
上图:UAE框架详细设计。 系统使用自回归LVLM处理来自原始图像的输入图像嵌入,生成文本描述,然后输入自回归LLM。从中提取最终隐藏状态,通过连接器投影到解码器特征空间,作为图像生成的条件。
LVLM作为编码器,将输入图像转换为高维语义表示;投影器则将这一表示映射到解码器的条件空间;最后,扩散模型将条件扩展为像素。这种分离设计既保持了接口最小化,又保留了各组件的优势,使系统模块化且可扩展。
值得注意的是,研究者采用LoRA(Low-Rank Adaptation)适配技术进行强化学习后训练,这有助于"保留预训练中学习的丰富语义知识,同时高效有效地学习新任务知识"。LoRA通过低秩分解实现高效参数微调,在保留预训练知识的同时高效学习新任务。
数据基石:长上下文的威力
UAE的成功离不开其精心构建的700K长上下文文本-图像数据集。每对样本包含一张1024分辨率的图像和一段超过250个英文单词的详细描述。这些描述由InternVL-78B模型对私有图像集合生成,特别强调"对象、属性、空间关系和场景构成"。
研究者还通过GPT-4o蒸馏额外50K高分辨率样本(约300词),进一步"加强描述质量和风格一致性"。这些数据在预训练中用于"热身"解码器,使其能够捕捉"细粒度语义和复杂空间关系"。


700K长上下文数据集示例1
上图:700K长上下文图文对数据集示例。 数据集包含1024分辨率图像和超过250词的详细描述,特别强调对象、属性、空间关系和场景构成。


700K长上下文数据集示例2
上图:700K长上下文图文对数据集另一示例。 数据集通过InternVL-78B生成,确保描述覆盖对象、属性、空间关系和场景构成等关键元素。
长文本的战略意义不容小觑。论文指出,长文本提供"更高带宽的视觉-语言对齐信号",能编码"更完整的语义(实体、属性、关系、计数、遮挡、背景、光照、风格)",减少条件中的歧义并加强I↔T映射。这一观点在后续实验中得到了充分验证。
Unified-GRPO算法三部曲
UAE的核心创新在于Unified-GRPO(Unified Group Relative Policy Optimization)算法,一个三阶段强化学习流程,旨在实现理解与生成的双向增强:
阶段一:冷启动重建
摒弃传统的I2T和T2I损失,仅使用语义重建损失:
这一阶段的目标是"确保编码器和解码器能有效协作进行图像重建",为后续阶段奠定基础。通过仅关注重建相似度,避免了传统训练中理解与生成目标的冲突。
阶段二:生成驱动理解(Generation for Understanding)
冻结解码器,将其作为奖励评估环境的一部分。编码器(LVLM)被训练为"产生能最大化解码器重建质量的表示"。
这一过程的核心是Group Relative Policy Optimization (GRPO)算法,其工作原理可分为三步:
1. 多轨迹采样:对于每张输入图像,从旧策略中采样多组描述(形成G个轨迹)
2. 奖励计算:计算每组描述对应的重建质量,使用CLIP图像编码器的余弦相似度作为奖励信号:
3. 相对优势估计:通过组内标准化确定相对优势:
GRPO的目标函数为:
这种设计使模型能够专注于生成比组内其他描述更好的描述,而非追求绝对分数,从而更稳定地优化理解能力。关键在于:重建相似度作为奖励信号,直接将理解质量与生成效果关联起来。
阶段三:理解驱动生成(Understanding for Generation)
冻结编码器,将其输出的文本嵌入作为条件,微调解码器。目标是"让解码器学会从这些描述中重建,迫使它利用每一个细节,提高长上下文指令遵循和生成保真度"。
有趣的是,研究者探索了"使用视觉编码器的图像嵌入替代理解模型的输出描述"的替代路径。实验表明,"在Stage-3长文本RL后,后续I2I RL仅带来边际收益"。论文进一步解释,长文本和图像嵌入"都在Qwen的条件嵌入空间中产生",携带"用于重建的可比语义信息"。这一观点挑战了传统认知,表明在足够详细的文本描述下,文本条件可以达到与图像嵌入相似的重建效果。
关键洞见:UAE框架通过将理解与生成统一在一个重建目标下,解决了传统方法中的割裂问题。700K长上下文数据集为训练提供必要带宽,而Unified-GRPO算法则实现了理解与生成的双向增强。这种设计不仅解决了理解与生成的割裂问题,还催生了"啊哈时刻"这一协同进化现象。
本节小结:UAE框架通过自编码器视角,将理解与生成统一在一个重建目标下。700K长上下文数据集为训练提供必要带宽,而Unified-GRPO算法则实现了理解与生成的双向增强。这种设计不仅解决了传统方法中理解与生成的割裂问题,还催生了"啊哈时刻"这一协同进化现象。
数据不会说谎——"啊哈时刻"的降临
为了验证UAE的有效性,研究者提出了Unified-Bench,首个专门用于评估多模态模型统一程度的基准。这一评测协议从100张多样化的源图像开始,模型首先生成详细描述,然后基于该描述重建图像,最后计算重建图像与原图的相似度。
Unified-Bench:统一性的度量尺
不同于传统仅评估生成或理解能力的基准,Unified-Bench通过"caption→generate→compare"协议直接测试"理解中提取的语义是否足以进行忠实再生,以及再生是否验证了理解的完整性"。
评测使用四种广泛采用的视觉编码器计算统一分数:CLIP、LongCLIP、DINO-v2和DINO-v3。这种多角度评估确保了"对比学习(CLIP家族)和自监督(DINO家族)特征的全面评估",能够反映布局和纹理级语义的保留情况。

Unified-Bench案例研究
上图:Unified-Bench案例研究。 评测使用四种视觉编码器(CLIP、LongCLIP、DINO-v2、DINO-v3)计算统一分数,确保对比学习和自监督特征的全面评估。案例显示,UAE能避免三类典型错误:(i)类别漂移(将狗误识别为猴子);(ii)属性遗漏或错配;(iii)场景描述不足,从而实现高保真重建。
上图的案例研究特别展示了UAE如何避免三类典型错误:
- 类别漂移:一些基线模型将小黑狗误识别为猴子,导致生成错误物种
- 属性遗漏或错配:描述遗漏关键物品(豆豆帽、眼镜)或将服装颜色错配,导致重建结果扭曲
- 场景描述不足:模糊的背景和缺失的光照线索,无法在推理时保持一致的摄影风格
UAE的描述则系统性地列举了全部语义——物种、服装类型和颜色、眼镜、姿势、遮挡("耳朵不可见")、背景风格("模糊,公园风格")和光照——产生保留身份、服饰和整体美学的重建。
量化结果:统一性的胜利
表1显示,UAE在Unified-Bench上取得了最佳总体分数(86.09),首次超越GPT-4o-Image(85.95)。具体而言,UAE在CLIP(90.50)、DINO-v2(81.98)和DINO-v3(77.54)上领先,并在LongCLIP(94.35 vs. 94.37)上达到统计平局。
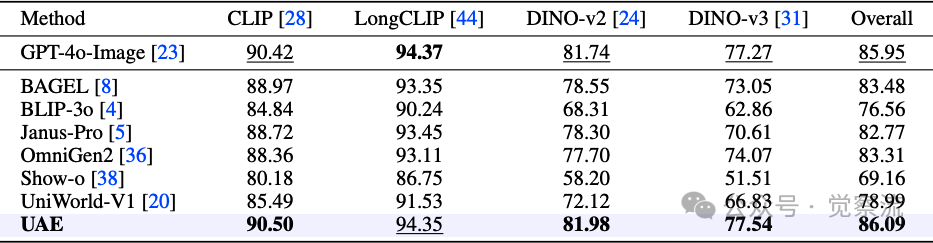
UnifiedBench评测结果
上表:Unified-Bench上的统一分数比较。 UAE在总体分数上以86.09领先,首次超越GPT-4o-Image(85.95),表明其能更好地保留布局和纹理级语义。特别值得注意的是,UAE在CLIP(90.50)和DINO系列指标上大幅领先,证明其在对象结构和细粒度语义上的优势。
这些一致提升表明UAE"能保留布局和纹理级语义,转化为更忠实的重建"。相比之下,其他模型如BAGEL(83.48)、OmniGen2(83.31)和Janus-Pro(82.77)表现次之,而BLIP-3o(76.56)和Show-o(69.16)明显落后——这凸显了"在单独的理解或生成任务上的强性能并不一定产生更高的统一分数(理解与生成之间的强相互增强)"。
关键解读:UAE在DINO-v2上81.98分 vs. Bagel的78.55分,意味着UAE能更准确地重建物体的结构和空间关系——比如不会把"左侧的橙色笔记本电脑和右侧的紫色刀"错配成"左侧的紫色笔记本电脑和右侧的橙色刀"。
Caption质量评估:细节决定成败
UAE生成的描述在Unified-Bench上获得86.09分,显著优于Qwen-2.5-VL-7B(81.92)和3B(80.85)。特别是在DINO系列指标上的大幅领先,表明其在"对象结构和细粒度、布局感知语义"上的优势。

Caption质量评估
上表:理解模型生成的描述在文本到图像生成中的质量比较。 UAE在所有指标上均领先,表明其生成的描述更适合用于图像生成。
研究者还使用Claude-4.1、GPT-4o、Grok-4和o4-mini四个商业LLM进行成对比较,评估描述质量。结果显示,UAE(基于Qwen-2.5-VL-3B)在多个维度上取得显著优势:平均胜率94.7% vs Show-o,71.4% vs OmniGen2,64.3% vs Bagel,76.3%/71.5% vs Qwen-2.5-VL(3B/7B)。特别值得注意的是,在Claude-4.1评判中,UAE对Show-o的胜率高达97.8%,这表明UAE生成的描述在"完整性、属性绑定、关系和空间保真度"等维度上具有压倒性优势。
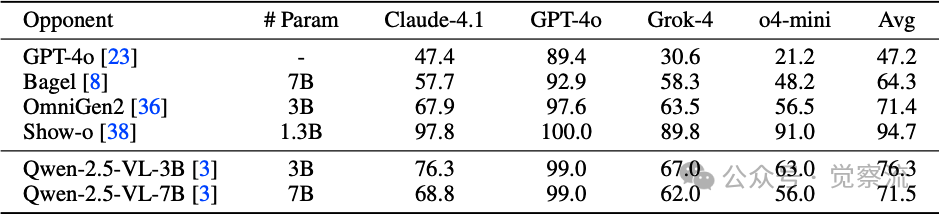
商业LLM评判结果
上表:商业LLM评判结果。 UAE在多个维度上取得显著优势,尤其在Claude-4.1评判中对Show-o的胜率高达97.8%,表明其在完整性、属性绑定、关系和空间保真度等维度上的压倒性优势。平均胜率是评估理解模型生成描述质量的关键指标。
"啊哈时刻"的实证:协同进化的奇迹
随着强化学习训练的进行,研究者观察到了一个令人振奋的现象:理解模型输出的描述变得越来越详细,同时重建质量同步提高。这一"啊哈时刻"是真正统一的实证标志。

理解与生成的协同进化
上图:理解与生成的协同进化过程。 随着强化学习步数增加,理解模型(编码器)输出的描述从简短概括(仅包含主要对象)逐步发展为详尽描述(包含材质、遮挡、背景、光照等细节);同时,生成模型(解码器)能够精确解读这些细节,实现从模糊到高保真的重建。底部趋势线显示,描述长度增加(语义覆盖的代理)与统一奖励上升呈现强相关性,每当描述器捕获先前遗漏的约束(如添加左右关系或精确基数)时,会出现明显跳跃。
具体而言,随着训练进行,"描述长度增加(语义覆盖的代理)且统一奖励上升,每当描述器开始捕获先前遗漏的约束时,会出现明显跳跃"。早期的描述倾向于陈述类别和一些显著属性;中期描述开始列举数量、颜色和空间关系;后期描述则系统地涵盖配饰、材质、遮挡、背景和光照等细节(如"黄色针织无檐便帽"、"海军蓝针织高领毛衣"、"黑色框架眼镜"、"耳朵不可见"、"模糊背景,公园风格")。
下图的趋势线显示了两个关键信号的强相关性:caption长度增加(语义覆盖的代理)与统一奖励上升。每当描述器开始捕获先前遗漏的约束(如添加左右关系或精确基数)时,会出现明显的跳跃。这种正相关性证实了理解与生成之间的正向循环——更好的理解(更密集、更精确的描述)导致更好的生成,而更好的生成能力又鼓励理解模型提供更详细的信息。

关键发现:以上图中的小黑狗示例为例,早期描述可能仅提及"一只戴着帽子的狗";随着训练深入,描述发展为"一只小黑狗戴着黄色针织无檐便帽,佩戴黑色框架眼镜,耳朵不可见,站在模糊的公园背景中"。这种描述的精细化直接导致重建质量的显著提升,证明了理解与生成之间的正向循环。
生成能力验证:全面领先
在GenEval基准测试中,UAE在Counting(0.84)和Color attribution(0.79)上领先(比Bagel的0.63高出16分,比OmniGen2的0.76高出3分),在Colors上并列领先(0.90),在Position上排名第二(0.71),在Two object上达到0.89。
当考虑LLM重写时,例如使用与Bagel相同的重写提示,UAE在图像生成任务上的总体得分为0.89,展示了SOTA性能。这表明UAE不仅在原始提示下表现优异,在标准化条件下依然保持领先,证明了其真正的技术优势。
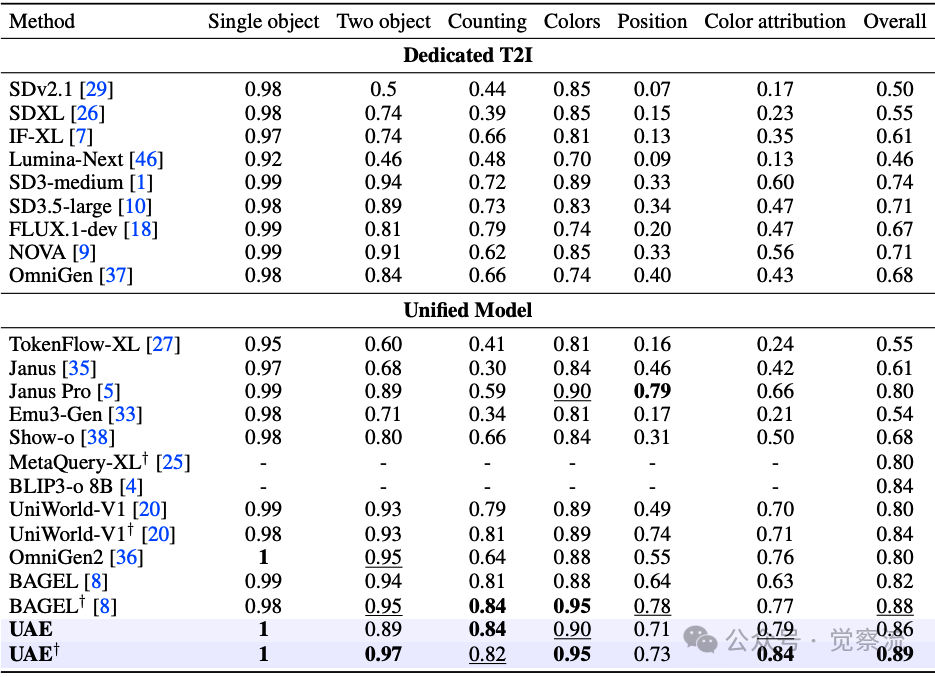
GenEval评测结果
上表:GenEval基准测试结果。 UAE在总体分数(0.86)上领先,特别在计数和颜色属性绑定方面表现突出,表明其在处理基本视觉元素方面的优势。
在更难的GenEval++基准(要求处理三个或更多对象,每个对象具有不同属性和空间关系)上,UAE在Overall(0.475)上领先,在Color/Count(0.550)和Pos/Count(0.450)上领先,在Color/Pos(0.550)和Multi-Count(0.400)上排名第二。
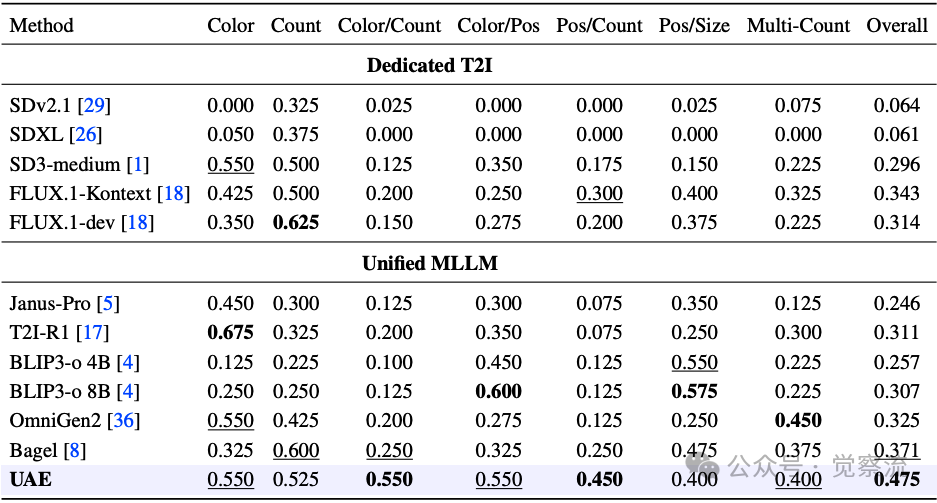
GenEval++结果
上表:在GenEval++上的指令遵循生成能力比较。 UAE在总体分数上领先,显示其在处理复杂组合约束方面的优势。
在DPG-Bench上,UAE在Entity(91.43)、Attribute(91.49)和Relation(92.07)上领先,Overall(84.74)排名第二,紧随Bagel(85.07)。这一子分数模式表明UAE的优势源于"在长提示下对实体定位和关系处理的忠实度"。
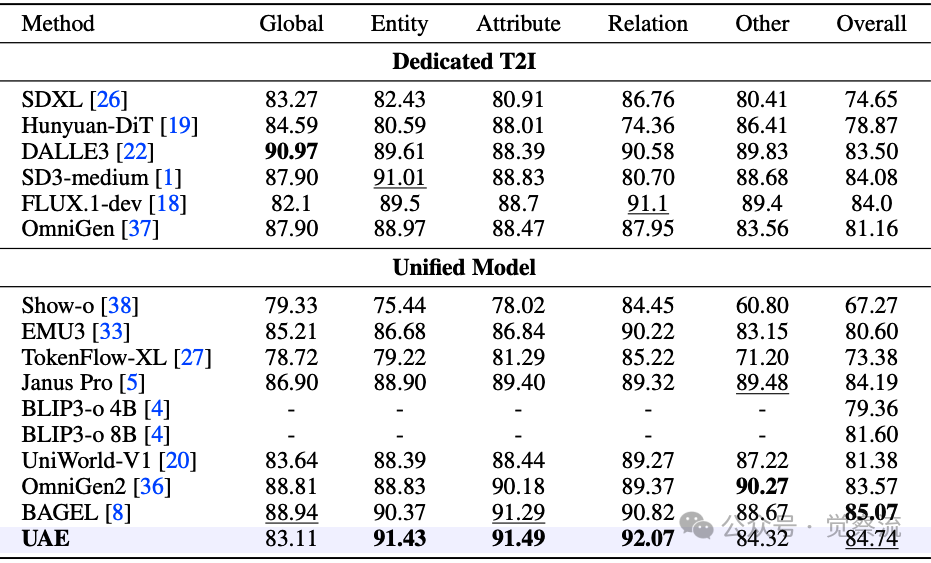
DPG-Bench评测结果
上表:DPG-Bench基准测试结果。 UAE在实体识别、属性理解和关系建模方面均取得最佳成绩,表明其在复杂场景理解上的卓越能力。
通过GenEval++案例分析,UAE展示了三大优势:
1. 在多实体场景中保持属性绑定:对于"三个紫色吹风机和一个粉色冲浪板"的提示,UAE将颜色准确绑定到正确类别,而基线模型往往将冲浪板染成紫色或将粉色/紫色混合。
2. 在尊重共现约束的同时可靠处理离散计数:对于"上方三张床和下方三个停车计时器"的提示,UAE保持了3+3的基数和垂直排列;竞争模型往往计数错误或满足布局但遗漏物品。
3. 更忠实地处理左右/分组关系:对于"左侧的橙色笔记本电脑和右侧的紫色刀"的提示,UAE保持了极性并避免了常见的颜色-对象交换错误。
这些案例证明了UAE在"多实体场景中的属性绑定"、"离散计数的可靠性"和"左右/分组的忠实处理"三大关键能力上的优势。类似的优势也体现在"两头牛、两本书和一个甜甜圈"以及"六个花瓶"的提示中:UAE在保持计数的同时平衡了全局构图与局部细节,渲染出合理的对象几何形状和材质。这些观察与表3的数据一致:UAE在Color/Count和Pos/Count上领先,在Color/Pos和Multi-Count上具有竞争力,反映了对联合约束的稳健满足,而非仅在单一维度上表现出色。

GenEval++案例分析
上图:GenEval++案例分析。 当要求生成"三个紫色吹风机和一个粉色冲浪板"时,UAE准确地将紫色分配给吹风机、粉色分配给冲浪板,而其他模型要么将冲浪板染成紫色,要么混合两种颜色。这种精确的属性绑定能力,正是UAE理解与生成真正统一的体现。

UAE在1024×1024分辨率下的生成结果
上图:UAE在1024×1024分辨率下的可视化结果。 模型在高分辨率下展现出卓越的细节还原能力,特别是在材质、光照和复杂空间关系的准确表达方面。
上图展示了UAE在1024×1024分辨率下的生成结果,突显了模型在高分辨率下的细节还原能力。无论是材质的质感(如毛衣的针织纹理、眼镜的反光)、光照效果(如柔和的自然光、阴影的过渡),还是复杂的空间关系(如人物与背景的层次感、物体间的遮挡关系),UAE都实现了高度精确的重建。这种高保真度正是自编码器框架成功的关键证据。
本节小结:Unified-Bench作为首个评估多模态统一程度的基准,证实了UAE在理解与生成协同方面的领先地位。"啊哈时刻"的观察提供了理解与生成相互促进的直接证据,而多维度评测结果则全面验证了UAE在生成能力上的优势。
统一之后,路在何方?
UAE取得的成果不仅验证了自编码器视角的有效性,也为未来多模态研究指明了方向。
图像嵌入 vs. 长文本:功能等价性
在Stage-3中,研究者探索了使用视觉编码器的图像嵌入替代文本作为条件的替代路径。实验发现,"在Stage-3长文本RL后,后续I2I RL仅带来边际收益"。这一发现具有深远意义:一旦模型被训练为产生足够详细的长文本,"切换到I2I重建可能带来的额外收益有限",暗示两种路径在实践中的"功能等价性"。
论文进一步解释,长文本和图像嵌入"都在Qwen的条件嵌入空间中产生",携带"用于重建的可比语义信息"。这一观点挑战了传统认知,表明在足够详细的文本描述下,文本条件可以达到与图像嵌入相似的重建效果。研究者指出:"The same logic extends to I2I: a dense visual embedding can be viewed as an extreme case of a 'very long' textual embedding that covers the entire scene"。这表明图像嵌入可以被视为"覆盖整个场景的'极端长'文本嵌入",对理解两种条件方式的本质联系至关重要。
向图像编辑与文本渲染扩展
尽管UAE在重建任务上表现出色,但在图像编辑和文本渲染方面仍有局限。研究者指出,编辑需要"像素级保留",而当前系统主要依赖语义条件。他们提出自然扩展路径:"通过添加VAE图像嵌入增强条件,并训练具有联合优化语义合规性和像素保留的重建目标"。
对于文本渲染,论文承认这是当前限制:"我们的训练数据包含少量高分辨率、文本丰富的图像-描述对,且未进行针对性文本特定RL"。借鉴X-Omni等先前工作,他们建议引入OCR(Optical Character Recognition)奖励,开发"Unified-GRPO for text",让理解模块必须捕获字形内容和布局。具体而言,"A natural next step is Unified-GRPO for text, where the understanding module must capture glyph content and layout, and the generator is rewarded for reconstructing the original text"。这一更精细的目标有望增强包含标志、文档和UI元素场景中的理解和生成能力。

商业LLM评判原始提示
上图:商业LLM评判原始提示。 该提示模板确保了评判过程的一致性和客观性,为caption质量评估提供了标准化框架。
架构进化方向:回归自编码器本质
研究者讨论了当前极简设计的初衷:"以最小的编码器-连接器-解码器设计呈现自编码器视角,尽可能透明"。展望未来,他们计划进行两项升级:(1)优化连接器以更好地对齐LVLM输出空间和扩散解码器条件空间;(2)将扩散组件推向"纯解码器",进一步解耦理解与生成。
这一更紧密遵循自编码器原则的设计应产生"更干净的接口、更稳定的RL,以及插入特定能力的更清晰路径"。例如,编辑功能可以通过VAE潜变量实现,而文本渲染则通过OCR感知目标强化。
长文本的战略意义再思考
论文深入探讨了长文本如何成为"所有任务的基础":理解、生成、I2I和编辑。研究者强调700K长文本数据集(>250词,1024px)的战略价值:"为训练覆盖所有显著细节的描述器和能对其条件的生成器提供缺失的带宽"。
值得注意的是,研究者观察到GPT-4o-Image能够接受非常长的输入并以高保真度重现其语义,这表明它很可能经过了长文本监督的微调,以内部化这些细粒度约束。然而,尽管其重要性,社区仍然缺乏真正大规模、高分辨率的长文本语料库。这促使研究者构建了700K长文本图像-描述集(超过250个英文单词,1024像素图像):"它为训练覆盖所有显著细节的描述器和能对其条件的生成器提供了缺失的带宽。"
尽管长文本训练引入了计算和建模挑战(上下文长度、位置外推、冗余控制),UAE通过"轻量级投影器/连接器、有利于显著细节而非冗长的重建奖励、惩罚遗漏和矛盾的RL信号",将长文本从负担转变为"精确、高信息接口"。
本节小结:UAE框架揭示了理解与生成之间的功能等价性,为多模态研究开辟了新方向。长文本作为统一接口的战略价值已得到充分验证,而架构的进一步优化将使系统更加贴近自编码器本质。
迈向真正的多模态智能
UAE不仅是一个技术突破,更是对多模态统一本质的深刻诠释。它证明了理解与生成可以且必须相互成就,而非简单共存。如论文所述,真正的统一"应提供明确的双向收益——利用每个任务来加强另一个,而不仅仅是将它们作为独立部分连接起来"。
"啊哈时刻"的观察尤为珍贵:当编码器自发产生更详尽描述,解码器同步提高解读能力时,我们看到了"迈向真正多模态统一和智能的突破性证据"。这一现象不仅验证了自编码器视角的有效性,更揭示了多模态智能的内在规律——理解与生成是同一枚硬币的两面,彼此依存、相互强化。
UAE框架提供了一个"可验证、可操作的统一范式",其核心思想——以重建保真度作为统一目标——有望成为未来多模态研究的基石。随着长文本监督和更精细的架构设计,我们有望看到更多真正统一的多模态系统,不仅在技术指标上领先,更能实现理解与生成的内在和谐共生。
当多模态模型不再只是"多才多艺",而是其各项能力在底层逻辑上深度交织、相互滋养的"有机生命体"时,人工智能将真正迈向下一个纪元。UAE的探索告诉我们,统一不是终点,而是通向真正多模态智能的起点。正如论文所言,成功的重建信号表明"连贯的双向信息流和改进的视觉-语言对齐",这正是通向更高级智能的关键一步。
回顾全文,UAE的突破性在于:
- 通过自编码器视角,将理解与生成统一在一个重建目标下
- 通过Unified-GRPO算法,实现理解与生成的双向增强
- 通过700K长上下文数据集,提供必要的训练带宽
- 通过Unified-Bench,首次量化评估多模态统一程度
特别是"啊哈时刻"的观察,为多模态统一提供了实证支持:理解与生成不是简单的任务堆砌,而是可以通过一个精巧的架构和重建目标,实现内在的、相互强化的共生关系。这一发现不仅解决了当前多模态领域的核心痛点,更为未来多模态智能体的发展指明了方向——真正的统一不是将理解与生成并排放置,而是让它们在同一个闭环中相互成就,共同进化。


