在发布多款自研大模型之后,小米又交出了一份重要成果。
小米具身智能团队正式发布了首篇论文,提出统一具身智能与自动驾驶的新模型 MiMo-Embodied。模型在 17 项具身任务和 12 项自动驾驶任务中取得领先表现,更重要的是,它从工程层面展示了这两个长期分离的技术领域可以在同一框架下实现统一建模。
小米智驾团队的郝孝帅是论文的核心第一作者,小米智驾团队首席科学家陈龙博士担任 project leader。
该模型是陈龙团队的首个重大成果。由于以罗福莉团队之前发布的MiMo-VL作为基座进行了continue-train,这也是文章作者栏中有“罗福莉”的原因。此前有媒体曾误解为罗福莉首个小米成果,也引发了当事人发朋友圈澄清事实。

这篇论文关注的核心问题是:同一套视觉语言模型,能否在面对“抓取物体”与“驾驶车辆”这两类差异极大的任务时,仍保持一致的理解方式和决策逻辑。
这一问题长期困扰多场景智能体的研究,而 MiMo-Embodied 正是小米对这一方向给出的首次系统回应。

多任务统领式领先
这篇论文中主要围绕两个主要方向进行了系统实验:具身智能与自动驾驶。
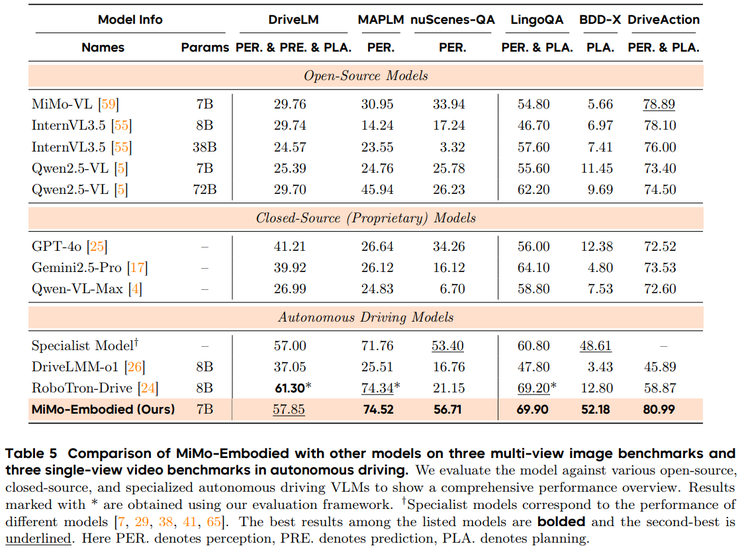
整体结果非常突出,可以用一句话概括:MiMo-Embodied 在 17 个具身智能任务和 12 个自动驾驶任务中,都取得了全面领先的表现,在多数关键基准上都处于第一。
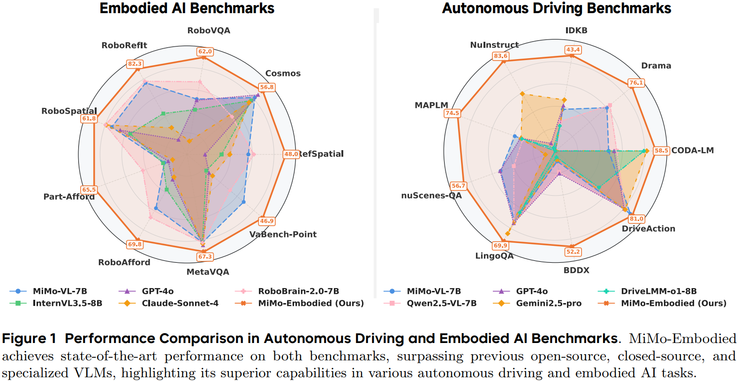
在具身智能方面,实验评测涵盖可供性推断、任务规划和空间理解三个能力。
其实可供性推断的测试主要评估模型是否能够正确理解物体的使用方式。例如识别物体上可操作的部位、精确指出指定位置、判断场景中哪些区域可以放置物品,或在多个相似物体中找到与描述相符的那一个。
在这类任务中,MiMo-Embodied 在五个主流基准上均表现突出。在 RoboRefIt 中,它可以从一组高度相似的物体中准确定位目标;在 Part-Afford 中,它能够识别物体的可操作部件;在 VABench-Point 中,它能根据文字描述精确给出坐标,整体表现达到当前最优水平。
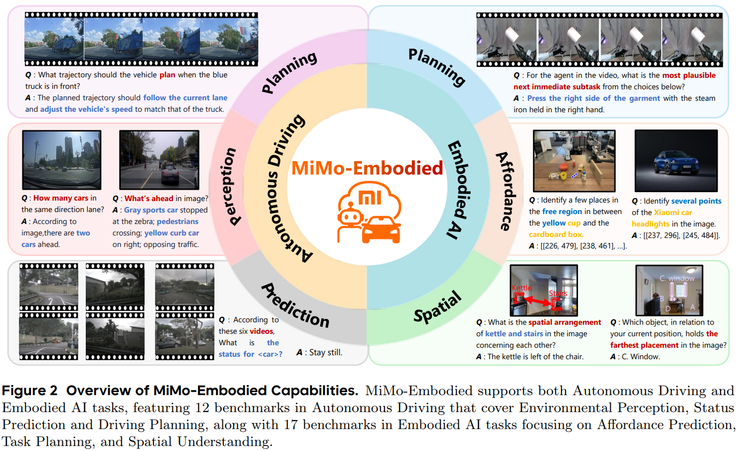
任务规划方面的测试关注模型根据情境推断下一步行动的能力。例如根据视频判断任务的后续步骤、依据目标从多个候选动作中选择正确的操作,或根据已有步骤推断接下来可能发生的事件。MiMo-Embodied 在 RoboVQA、Cosmos-Reason1 和 EgoPlan2 等基准中均处于领先位置,说明其在行动推理与任务结构理解方面具有较强的综合能力。

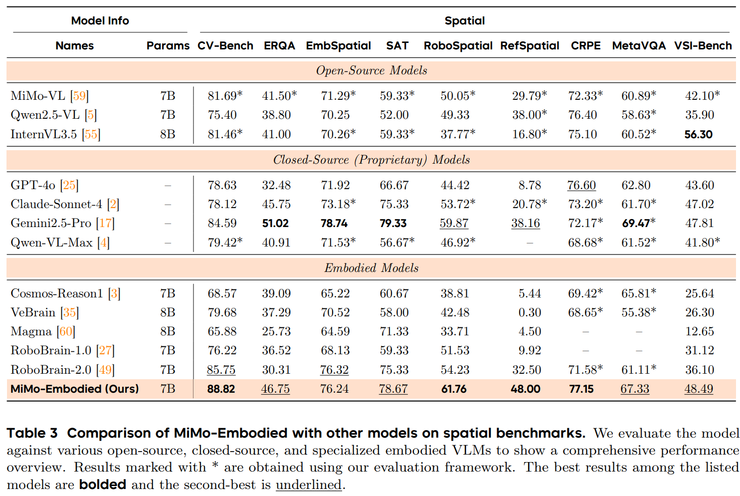
在九个代表性测试中,MiMo-Embodied 在 CV-Bench、RoboSpatial、RefSpatial 与 CRPE-relation 等核心基准上取得最高分,在 EmbSpatial 与 SAT 等任务中也保持在第一梯队,体现出扎实的空间推理能力。
在自动驾驶方面,实验同样覆盖三个核心模块:场景感知、行为预测和驾驶规划。
场景感知的测试要求模型看清路上的车辆、行人和交通标志,描述场景内容,识别潜在风险,并输出关键目标的位置。MiMo-Embodied 在 CODA-LM 等复杂场景理解任务中表现与专用模型相当甚至更好,在 DRAMA 中对关键物体的定位精度最高,在 OmniDrive 与 MME-RealWorld 中也保持领先。
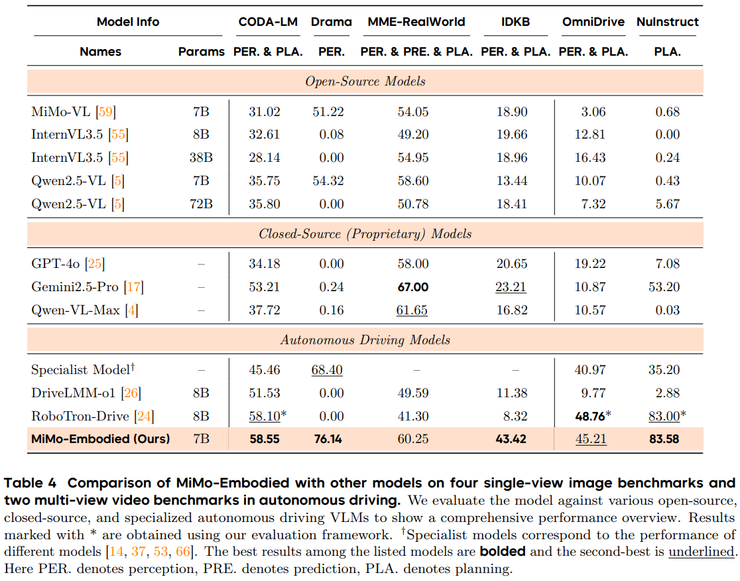
行为预测要求模型能够推测其他交通参与者可能采取的动作,例如车辆是否会变道、是否会让行,或从多视角画面中理解整体交通流动趋势。MiMo-Embodied 在 MME-RealWorld 与 DriveLM 等基准中表现稳定且领先,显示出对动态交通场景的良好理解能力。
而驾驶规划则要求模型给出车辆应当采取的动作,并解释其决策依据,同时保证遵守交通规则、避免风险。MiMo-Embodied 在多个核心基准上取得领先,包括在 LingoQA 中准确解释驾驶行为,在 DriveLM 中从多视角场景推导合理规划,在 MAPLM 中理解道路结构参与决策,在 BDD-X 中清晰说明驾驶理由,整体表现甚至超过一些专门为自动驾驶设计的模型。
从单域到跨域的四阶段训练框架
实验结果之外,团队还构建了一套由四个阶段组成的训练流程,使模型的能力从最初的具身理解,逐步拓展至自动驾驶决策,并进一步发展出可解释的推理能力与更高的输出精度。
值得注意的是,这四个阶段均以罗福莉所属的 Xiaomi LLM-Core(大语言核心团队)推出的 MiMo-VL 作为统一的基础模型展开。整个训练体系以能力逐级递进为结构,每个阶段都为下一阶段奠定能力基础,从而形成一套连续且可扩展的模型演进路径。

在第一阶段中,模型主要接受具身智能相关的监督训练,训练数据覆盖可供性推断、任务规划和空间理解等任务。
这些数据让模型能够先掌握如何看懂物体的结构、识别可操作部位、理解场景中的空间关系,并能对一段任务过程进行正确的下一步推断。经过这一阶段,模型具备了基本的空间推理能力、初步的任务规划能力,以及对可供性的感知与表达能力。
第二阶段专门引入自动驾驶领域的监督训练。模型开始学习处理复杂的交通场景,训练数据包括多视角相机画面、驾驶视频、自动驾驶问答、关键目标的坐标标注以及与道路结构相关的知识。
通过这些训练,模型能够理解道路环境、读取交通元素、预测其他交通参与者的行为,并给出符合规则的驾驶规划。此阶段使模型掌握动态场景分析、意图预测以及驾驶决策等关键自动驾驶能力。
第三阶段加入链式思维训练,也就是让模型学习“把推理过程说出来”。训练数据含有明确的推理步骤,模型在此阶段被引导按照“观察场景→分析要素→提出候选→给出理由→得出结论”的顺序组织回答。
结果是模型开始能够自洽地解释自己的判断逻辑,不论是在具身任务还是在驾驶任务中,都能给出清晰、可读的推理链条,显著提升输出的透明度与一致性。
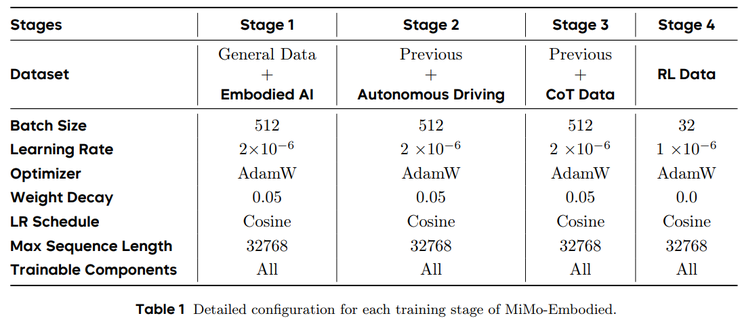
最后在第四阶段进行强化学习微调,目的在于进一步提升模型在细节层面的准确度。例如,多选题会根据是否答对给予奖励;定位类任务通过预测区域与真实区域的 IoU 分数提供更精细的反馈;推理回答的形式会通过格式模板进行严格约束。
通过这些规则化的奖励机制,模型在坐标定位精度、推理质量及细节判断能力上都有明显增强,最终成为一个在多任务场景中都能稳定发挥的统一具身模型。
打通两个世界的第一步
这项工作的价值不只在于模型性能领先,而在于它解决了长期困扰业界的一道核心难题:机器人和自动驾驶本应属于两个完全不同的世界,却第一次被放进了同一个大脑里。
过去的模型要么专门做室内具身任务,要么专门做自动驾驶,两个方向无论是场景、感知还是动作都完全割裂,彼此几乎没有可共享的能力。
这意味着“智能体”的边界第一次被打通。
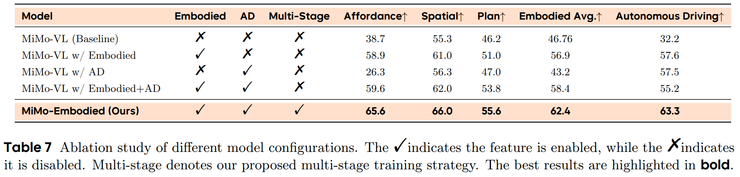
除此之外,为了验证这种跨场景融合是否真正可行,团队还专门构建了一个前所未有的大规模评测体系:17 个具身智能基准加上 12 个自动驾驶基准,覆盖可供性、规划、空间理解,以及感知、预测、驾驶决策等多维能力。
模型在如此复杂而全面的体系下依旧保持稳定领先,证明它不是“弱项补短”,而是实实在在具备跨领域的泛化智能。这不仅验证了模型本身,也相当于是替整个行业点亮了“跨域评测”的新标准。
更重要的是,MiMo-Embodied 提供了一种可复制的范式。论文提出的四阶段训练路线:先学具身,再学驾驶,再叠加链式推理,最后用强化学习抠细节,实际上就是一条通向“通用具身智能体”的训练路径。
它告诉行业:智能体能力并不必须分散在不同的模型中,而可以像课程一样逐层积累,让统一模型在多种复杂场景中都保持稳定表现。
而从产业角度看,这更像一次“开锁”的动作。小米把跨域智能的这把钥匙直接扔给了开源社区,意味着未来即便是小团队,也能在这套基础上做改造,做出既能开车又能操作机械臂的多场景智能体。
电动车越来越像“带轮子的智能体”,机器人越来越像“带四肢的智能体”,而 MiMo-Embodied 的出现,让这两条原本平行的技术路线第一次有机会汇流。
更难得的是,这不是一个性能堪堪够用的概念模型,而是在 17 个具身测试 + 12 个自动驾驶测试里都能打、还能赢的大模型,连不少闭源私有模型都被它压了一头。
这一工作所展示的,早已不只是一种新的模型形态,而是向行业明确证明:自动驾驶与具身智能的能力可以在同一个体系中进行训练、评测和集成部署。这种统一方式为未来智能体的发展打开了新的方向,可能会重新塑造多场景智能系统的整体格局。
首篇论文背后的团队阵容
这是小米具身智能团队发布的首篇论文,由小米智驾团队的郝孝帅担任第一作者,项目负责人则是小米智驾团队首席科学家陈龙。

郝孝帅今年 8 月加入小米智驾团队。博士毕业于中国科学院大学信息工程研究所,现任小米汽车自动驾驶与具身智能算法专家,研究方向为自动驾驶感知和具身智能基座大模型。
在博士期间,他曾在亚马逊实习,师从李沐老师。在北京人工智能研究院担任研究员期间,深度参与了 Robobrain 1.0 和 Robobrain 2.0 等重大项目。结合github等公开信息,自从今年8月加入小米以来,MiMo-Embodied是郝孝帅首次以第一核心成员身份做出的重要贡献,也是首个自动驾驶与具身智能统一基座大模型 。
除此之外,郝孝帅还曾在 Information Fusion、NeurIPS、ICLR、CVPR、ECCV、AAAI、ICRA 等顶级会议与期刊上发表论文五十余篇,并在 CVPR、ICCV 等国际竞赛中取得了多次前三的成绩,科研背景十分扎实。

项目负责人陈龙博士同样在今年加入小米,担任小米汽车 Principal Scientist,自动驾驶与机器人部 VLA 负责人,他曾任职于端到端自动驾驶独角兽公司 Wayve,担任 Staff Scientist,带领团队成功研发并部署了全球首个上车的视觉语言自动驾驶系统 Lingo,被 Fortune,Financial Times,MIT Technology Review 等国际媒体报导。
此前在 Lyft 自动驾驶部门负责基于众包数据的深度学习规划模型研发工作陈龙博士凭借在辅助驾驶领域引入视觉-语言-行为(VLA)模型的卓越工作,成功入选《麻省理工科技评论》2025 年度亚太区“ 35 岁以下科技创新 35 人”。
加入小米后,陈龙开始带领 VLA 团队 推进端到端自动驾驶大模型的技术路线,进一步提升模型在复杂交通场景中的泛化、推理和解释能力。他与叶航军、陈光、王乃岩共同构成小米智驾团队的核心技术力量,组成了当前小米智驾体系的关键架构班底。
作者主页:
https://haoxiaoshuai.github.io/homepage/
https://www.linkedin.com/in/long-chen-in/
论文链接:
https://arxiv.org/abs/2511.16518