训练

AI训练的反直觉发现:添加"有毒"数据反而能造就更好的语言模型?
"当坏数据能够创造出好模型,AI训练领域又一个传统观念被颠覆"你有没有听说过这样一个说法:垃圾进,垃圾出? 在AI大语言模型的训练中,这一直是个不言自明的准则。 工程师们花费大量时间和资源过滤训练数据,移除那些含有有毒、有害或不适当内容的文本,以防止模型学习和生成这些内容。

苹果放大招!FastVLM 让视觉语言模型在 iPhone 上飞速 “狂飙”
苹果最近又搞了个大新闻,偷偷摸摸地发布了一个叫 FastVLM 的模型。 听名字可能有点懵,但简单来说,这玩意儿就是让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊!视觉语言模型的 “成长烦恼”现在的视觉语言模型,就像个不断进化的小天才,能同时理解图像和文本信息。 它的应用可广了,从帮咱们理解图片里的内容,到辅助创作图文并茂的作品,都不在话下。

RL训练总崩溃?R1-Reward稳定解锁奖励模型Long-Cot推理能力
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。 尽管近期强化学习(RL)在传统视觉任务和多模态推理任务中取得了显著进展,但其在奖励建模中的应用仍然受到挑战,尤其是如何通过强化学习对奖励模型引入长期推理能力。 来自快手、中科院、清华、南大的研究团队发现,直接把现有的 RL 算法(比如 Reinforce )用到训练 MRM 上,会遇到很多问题,比如训练过程很不稳定,甚至直接崩掉。

ICLR2025 | 同济提出无需训练的肖像动画框架FaceShot,让表情包、动漫人物、玩具等“开口说话”
今天和大家分享同济大学的最新研究FaceShot: 一举打破肖像动画模型“驱动真人”的局限,FaceShot 的动画效果可应用于各个领域的角色,包括 3D 动漫、表情符号、2D 动漫、玩具、动物等等。 每个角色都能流畅地跟随行车视频的面部动作,同时保留其原始身份,从而产生出色的动画效果。 FaceShot 的可视化结果。

开源全能图像模型媲美GPT-4o!理解生成编辑同时搞定,解决扩散模型误差累计问题
OpenAI GPT-4o发布强大图片生成能力后,业界对大模型生图能力的探索向全模态方向倾斜,训练全模态模型成研发重点。 开源的MLLMs和扩散模型已经过大规模预训练,其从零开始训练统一任务,不如取长补短,将MLLMs的语言建模能力,与扩散模型的像素级图像建模能力,进行有机的结合。 基于这个思路,ModelScope团队提出可同时完成图像理解、生成和编辑的统一模型Nexus-Gen,在图像质量和编辑能力上达GPT-4o同等水平,并将成果全方位开源,望引发开发者讨论,促进All-to-All模型领域发展。

AI学会“自我谷歌”!!阿里ZeroSearch技术不靠搜索引擎照样学得飞起,成本还降了88%?
想象一下,如果AI不再依赖谷歌搜索、Bing搜索这些“外包助手”,而是自带“搜索引擎大脑”自我检索、自我学习,结果表现还更优秀——你是不是觉得这听起来像是《黑客帝国》第二集?但阿里真的做到了!这不只是一次技术突破,更像是一次“AI自给自足革命”的打响第一枪。 ZeroSearch 的出现,可能正悄悄改变我们构建智能系统的底层逻辑。 01|告别谷歌,AI开始“自我检索”“用强化学习训练一个AI助手,光是搜索费用就能掏空初创公司的预算。

成本降低88%:阿里巴巴ZeroSearch技术颠覆AI训练模式
阿里巴巴集团研究人员近日推出一项名为"ZeroSearch"的突破性技术,彻底改变了训练人工智能系统搜索信息的方式。 这项创新技术通过模拟方法让大型语言模型(LLM)开发高级搜索功能,无需在训练过程中与真实搜索引擎交互,从而消除了对昂贵商业搜索引擎API的依赖。 解决成本与复杂性难题ZeroSearch解决了AI行业面临的两大关键挑战:搜索引擎返回文档质量的不可预测性,以及向谷歌等商业搜索引擎进行数十万次API调用所产生的高昂成本。

阿里巴巴开源 ZeroSearch 搜索引擎:训练成本大幅降低 80%
近日,阿里巴巴推出了一款名为 ZeroSearch 的开源创新大模型搜索引擎,这一新工具通过强化学习框架,极大地提高了搜索能力,并且在训练过程中不需要与真实搜索引擎互动。 ZeroSearch 的核心优势在于它能够利用大型预训练模型的知识,快速生成相关内容,并且可以动态控制生成内容的质量。 与传统的搜索引擎相比,ZeroSearch 的训练成本显著降低。

仅看视频就能copy人类动作,宇树G1分分钟掌握100+,UC伯克利提出机器人训练新方式
不用动作捕捉,只用一段视频就能教会机器人学会人类动作,效果be like:UC伯克利团队研发出了一套新的机器人训练系统,可将视频动作迁移到真实机器人。 这个名为VideoMimic的新系统,已经让宇树G1机器人成功模仿了100多段人类动作。 VideoMimic的核心原理是从视频当中提取姿态和点云数据,然后在模拟环境中训练并最终迁移到实体机器人。

腾讯助力DeepSeek:网络通信性能大幅提升,AI训练更高效
近日,腾讯技术团队对 DeepSeek 开源的 DeepEP 通信框架进行了深度优化,显著提升了其在多种网络环境下的性能。 经过测试,优化后的通信框架在 RoCE 网络环境下的性能提升达到了惊人的100%,而在 IB 网络环境中则提升了30%。 这一成果不仅为企业的 AI 大模型训练提供了更高效的解决方案,还为相关技术的进一步发展奠定了基础。

Fastino 融资 1750 万美元,利用廉价游戏 GPU 训练 AI 模型
在当今科技行业,AI(人工智能)正迅速崛起,许多巨头公司都在大谈特谈拥有万亿参数的 AI 模型,这些模型通常需要耗费巨资搭建庞大的 GPU 集群。 然而,Fastino 却走了一条不同的道路,利用成本低廉的游戏 GPU 进行 AI 模型训练,并成功获得了由 Khosla Ventures 领投的1750万美元融资。 这一创新的方式使得 Fastino 能够在资源有限的情况下,实现高效的 AI 模型开发。

开源即屠榜!UniME多模态框架登顶MMEB全球训练榜,刷新多项SOTA纪录
告别CLIP痛点,更懂语义关联的跨模态理解新SOTA来了! 格灵深瞳、阿里ModelScope团队,以及通义实验室机器智能团队联合发布通用多模态嵌入新框架UniME,一经推出就刷新MMEB训练榜纪录。 △图片于2025年5月6日08:00 UTC 8截取UniME作为一个创新性的两阶段框架,所展现的卓越的组合理解力,帮助MLLMs具备学习适用于各种下游任务的判别性表征的能力,并在多个任务中达到了新的SOTA。

万字长文带你读懂强化学习,去中心化强化学习又能否实现?
强化学习(RL)是当今 AI 领域最热门的词汇之一。 近日,一篇长文梳理了新时代的强化学习范式对于模型提升的作用,同时还探索了强化学习对去中心化的意义。 原文地址:「有时候几十年什么也不会发生;有时候几周时间仿佛过了几十年。

360开源升级自研7B参数模型360Zhinao3-7B 各项能力全面提升
360集团宣布开源升级了自研的7B参数模型360Zhinao3-7B,并已上线Github开源社区,可供免费商用。 这一模型不仅在数学和科学领域表现出色,更在通用能力上展现了强大的潜力,尤其在端侧应用上具有显著优势。 在本次升级中,360Zhinao3-7B模型仅通过增量训练700B的高质量token,就取得了显著的效果提升,这相比前代模型360Zhinao2-7B的10.1T token成本大幅降低,且不会增加模型的推理成本。

实时口语聊天大模型 LLaMA-Omni 2 来了,能让你的 AI 聊天体验起飞!
最近 AI 圈可是热闹非凡,今天咱们就来聊聊其中的 “狠角色”——LLaMA-Omni2。 这是一系列超厉害的语音语言模型(SpeechLMs),参数规模从0.5B 到14B 不等,专门为实现高质量实时语音交互而生,在 Hugging Face 上一经发布,就引起了广泛关注。 语音交互发展历程回顾:从 “卡顿” 到 “丝滑”语音交互在人机交互领域的地位愈发重要,它就像是为我们打开了一扇便捷的大门,极大地提升了交互效率和用户体验。

Freepik 发布“F Lite”:一个为版权安全而构建的开放 AI 图像模型
西班牙数字图形巨头 Freepik 近日推出了其最新的文本到图像生成模型“F Lite”,旨在成为 Midjourney 等因版权问题而备受争议的生成器的合法且安全的替代品。 F Lite 拥有约100亿个参数,其独特之处在于完全基于 Freepik 自身商业授权的图像库进行训练。 Freepik 声称,这使其成为首个完全依赖“工作安全”内容进行训练的如此规模的公开模型。

谷歌承认:即使网站选择退出,仍用搜索数据训练 AI
科技巨头谷歌在近日的一场联邦反垄断审判中承认,即使网站出版商明确选择不让其内容用于人工智能模型训练,谷歌仍会利用其搜索引擎收集的数据进行 AI 训练,包括备受争议的 AI Overviews 功能。 这一承认由谷歌旗下人工智能实验室 DeepMind 的副总裁伊莱·柯林斯在作证时做出。 司法部律师戴安娜·阿吉拉尔在质询中指出,即使出版商选择不让 DeepMind 使用其数据进行大型语言模型训练,这些相同的数据仍然会被谷歌搜索部门用于其自身的人工智能项目。
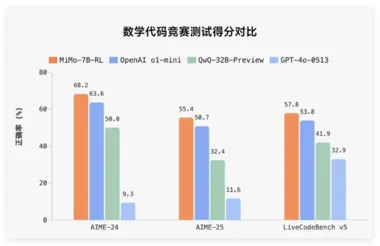
小米首个推理大模型开源Xiaomi MiMo,70 亿参数
全球知名科技公司小米正式发布其首个针对推理(Reasoning)而生的大型开源模型 ——Xiaomi MiMo。 该模型旨在解决当前预训练模型在推理能力上的瓶颈,探索如何更有效地激发模型的推理潜能。 MiMo 的推出标志着小米在人工智能领域的一次重要尝试,尤其是在数学推理和代码竞赛方面,表现出色。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉