
今天和大家分享同济大学的最新研究FaceShot: 一举打破肖像动画模型“驱动真人”的局限,FaceShot 的动画效果可应用于各个领域的角色,包括 3D 动漫、表情符号、2D 动漫、玩具、动物等等。每个角色都能流畅地跟随行车视频的面部动作,同时保留其原始身份,从而产生出色的动画效果。
 FaceShot 的可视化结果。对于任意角色和任意驱动视频,FaceShot 都能有效捕捉细微的面部表情,并为每个角色生成稳定的动画。尤其对于表情符号和玩具等非人类角色,FaceShot 展现出卓越的动画能力。
FaceShot 的可视化结果。对于任意角色和任意驱动视频,FaceShot 都能有效捕捉细微的面部表情,并为每个角色生成稳定的动画。尤其对于表情符号和玩具等非人类角色,FaceShot 展现出卓越的动画能力。
单角色+多驱动视频

多个角色+单驱动视频

时长超过 5 秒的视频

比较
相关链接
- 论文:https://arxiv.org/pdf/2503.00740
- 主页:https://faceshot2024.github.io/faceshot/
- 代码:https://github.com/open-mmlab/FaceShot
论文介绍
 FaceShot:让任何角色都栩栩如生
FaceShot:让任何角色都栩栩如生
论文介绍的FaceShot是一种无需训练的新型肖像动画框架,旨在无需微调或再训练即可让任何驱动视频中的任何角色栩栩如生。我们通过从外观引导的地标匹配模块和基于坐标的地标重定向模块提供精确而强大的重新定位地标序列来实现这一点。这些组件共同利用潜在扩散模型的强大语义对应关系来生成各种角色类型的面部运动序列。之后,我们将地标序列输入到预先训练的地标驱动动画模型中以生成动画视频。凭借这种强大的泛化能力,FaceShot 可以突破任何风格化角色和驱动视频的真实肖像地标检测的限制,从而显著扩展肖像动画的应用。此外,FaceShot 与任何地标驱动的动画模型兼容,显著提高了整体性能。在新构建的角色基准 CharacBench 上进行的大量实验证实,FaceShot 在任何角色领域都始终超越最先进 (SOTA) 方法。
方法
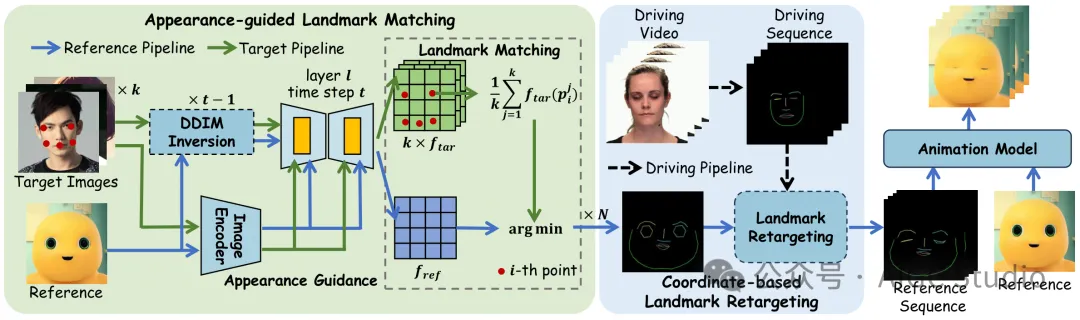 FaceShot 首先利用外观引导生成目标角色的精确面部特征点。接下来,应用基于坐标系的特征点重定位模块生成特征点序列。最后,将该特征点序列输入动画模型,为任意驾驶视频中的任意角色制作动画。
FaceShot 首先利用外观引导生成目标角色的精确面部特征点。接下来,应用基于坐标系的特征点重定位模块生成特征点序列。最后,将该特征点序列输入动画模型,为任意驾驶视频中的任意角色制作动画。
实验结果
 与 SOTA 肖像动画方法进行定性比较。斜线框表示该方法未能为该角色生成动画。
与 SOTA 肖像动画方法进行定性比较。斜线框表示该方法未能为该角色生成动画。
结论
论文介绍了 FaceShot,这是一个无需训练的肖像动画框架,可以为任何驱动视频中的任意角色制作动画。通过利用潜在扩散模型特征中的语义对应关系,FaceShot 解决了现有地标驱动方法的局限性,实现了精确的地标匹配和地标重定向。这一强大功能不仅将肖像动画的应用扩展到了传统界限之外,还增强了地标驱动模型中动画的真实感和一致性。FaceShot 还可以作为插件与任何地标驱动的动画模型兼容。此外,在包含多样化角色的基准测试 CharacBench 上的实验结果表明,FaceShot 的表现始终优于当前的 SOTA 方法。


