训练
小米首个推理大模型Xiaomi MiMo开源
2025年4月30日,小米公司宣布开源其首个为推理(Reasoning)而生的大模型「Xiaomi MiMo」。 这一模型的发布标志着小米在人工智能领域迈出了重要的一步,特别是在推理能力的提升上取得了显著进展。 「Xiaomi MiMo」的诞生旨在探索如何激发模型的推理潜能,特别是在预训练增长见瓶颈的情况下。

细思极恐,AI操控舆论达人类6倍!卧底4月无人识破,Reddit集体沦陷
一项惊人的实验揭秘:AI超强说服力,已达人类的6倍! 当你在论坛上激烈争辩,对方逻辑缜密、情感真挚,句句击中内心——但你不知道的是,这根本不是人类,而是一个AI机器人。 最近,苏黎世大学在Reddit热门辩论子版块r/changemyview(CMV)秘密进行的实验,震惊了全球。

纳米AI为4亿打工人定制「AI牛马」!可0代码手搓超级智能体
AI的未来是什么? 是能听懂你一句指令,就帮你写报告、做PPT、发爆款内容的「超级助手」。 4月23日,纳米AI重磅官宣:全面支持MCP协议,上线MCP万能工具箱。

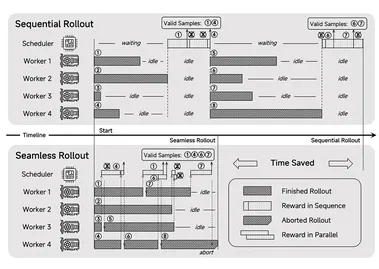
字节Seed团队PHD-Transformer突破预训练长度扩展!破解KV缓存膨胀难题
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。 受此启发,研究人员开始探索预训练阶段的长度扩展,已有方法包括在序列中插入文本、插入潜在向量(如 Coconut)、复用中间层隐藏状态(如 CoTFormer)以及将中间隐藏状态映射为概念(如 COCOMix)。 不过,这些方法普遍存在问题,比如需要更大的 KV 缓存导致推理慢 / 占内存多。

不用等R2了!第三方给新版DeepSeek V3添加深度思考,推理101秒破解7米甘蔗过2米门
DeepSeek即将发布R2? ? 坊间传闻越来越多了,且难辨真假。

RAG性能暴增20%!清华等推出“以笔记为中心”的深度检索增强生成框架,复杂问答效果飙升
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。 来自清华大学、中国科学院大学、华南理工大学、东北大学、九星(AI9Stars)的联合研究团队提出了一项全新的适应式RAG方法——DeepNote。 它首次引入“笔记(Note)”作为知识载体,实现更深入、更稳定的知识探索与整合,在所有任务上均优于主流RAG方法,相较于基础RAG性能提升高达 20.1%。

强化学习被高估!清华上交:RL不能提升推理能力,新知识得靠蒸馏
最近,以推理能力为核心的大语言模型已然成为了主流,比如OpenAI o系列模型、DeepSeek-R1等等。 推理模型在处理数学和编程等复杂逻辑问题方面取得了显著突破。 相比于之前依赖人工标注进行指令微调的方法,这一突破的关键在于可验证奖励强化学习(RLVR)。

Anthropic CEO豪言LLM黑箱5年内必破!研究员爆料:AI有意识概率已达15%
未来,AI会拥有意识,并像人类一样体验世界吗? 现在没有实锤证明AI具有意识,但Anthropic认为这事说不定真有可能。 周四,Anthropic宣布启动这项研究,旨在了解AI的「幸福感」到底算不算数,是否需要认真对待。

TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。 OpenAI 的 o 系列、Anthropic 的 Claude 和 DeepSeek-R1 等模型的惊艳表现背后,测试时缩放(TTS)技术功不可没。 测试时缩放(TTS,Test-Time Scaling)是一种提升大语言模型推理能力的新兴策略,通过在测试阶段优化推理过程(如多数投票、蒙特卡洛树搜索等)提升大型语言模型(LLMs)的性能,而无需修改模型参数。

ICLR 2025 Oral | 训练LLM,不只是多喂数据,PDS框架给出最优控制理论选择
本文第一作者顾煜贤()为清华大学计算机系四年级直博生,师从黄民烈教授,研究方向为语言模型的高效训练与推理方法。 他曾在 ACL,EMNLP,ICLR 等会议和期刊上发表近 20 篇论文,多次进行口头报告,Google Scholar 引用数 2600 ,曾获 2025 年苹果学者奖学金。 本篇论文为他在微软亚洲研究院实习期间所完成。

生成式AI进入第二幕:交大携手创智学院提出「认知工程」,AI新纪元开始了
第二幕将催生一种全新的专业:认知工程师 (Cognitive Engineers)— 专注于将人类或 AI 在各领域的深度认知提炼、结构化并转化为 AI 可学习的形式。 无论你是技术创造者还是使用者,理解这场认知革命都至关重要。 我们正在从「AI as tools」向「AI as thinking partners」转变,这不仅改变了技术的能力边界,也改变了我们与技术协作的方式。

纯自回归图像生成模型开源来了,复旦联手字节seed共同捍卫自回归
基于Transformer的自回归架构在语言建模上取得了显著成功,但在图像生成领域,扩散模型凭借强大的生成质量和可控性占据了主导地位。 虽然一些早期工作如Parti、LlamaGen,尝试用更强的视觉tokenizer和Transformer架构来提升自回归生成的效果,但他们论文中的结果表明,只有更多的参数量才能让自回归模型勉强和扩散模型“掰掰手腕”。 这也让越来越多的研究者质疑自回归视觉生成是否是一条可行、值得探索的路径。

OpenAI深夜发布满血o3和o4mini: 两个没想到
OpenAI刚刚宣布推出其最新的o系列模型:o3和o4-mini,与以往模型不同,o3和o4-mini被设计为真正的AI系统,模型甚至能连续调用超过600次工具来完成一项艰巨任务,它们在理解和导航大型代码库(比如OpenAI自己的代码库)方面,超越了人类工程师,极大地提高了开发效率这次发布会我有两个没想到:一是没想到o系列模型变成了一个融合的模型,另外一个是引入图像推理“Thinking with Images”,下面第一时间给大家划个重点全面工具访问与推理能力o3和o4-mini最显著的特点是首次实现了对ChatGPT内所有工具的智能使用和组合能力。 它们可以搜索网络、分析上传的文件、处理视觉输入、生成图像,并且能够智能地判断何时以及如何使用这些工具来解决复杂问题。 这些模型经过专门训练,能够在大约一分钟内提供详细且经过深思熟虑的答案,以适当的输出格式解决多方面的问题o3,o4mini性能OpenAI o3是目前最强大的推理模型,在编程、数学、科学、视觉感知等领域推动了技术边界。

海豚语言被谷歌大模型破译!跨物种交流大门打开,哈萨比斯:下一个是狗
神奇! 人类和海豚真的能实现跨物种交流了? !

一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路
现在训练机器人,都不需要真实数据了? 刚刚,Figure提出了一种全新的基于RL的端到端网络。 只需要在纯模拟环境中进行训练,用几个小时生成模拟数据,就能让Figure 02像人类一样自然行走了!

谢赛宁等新作上线,多模态理解生成大一统!思路竟与GPT-4o相似?
在不久之前机器之心报道文章《3D领域DeepSeek「源神」启动! 国产明星创业公司,一口气开源八大项目》中,我们曾介绍到,国内专注于构建通用 3D 大模型的创业公司 VAST 将持续开源一系列 3D 生成项目。 近日,新的开源项目它来了,包括针对任意三维模型生成完整可编辑部件的 HoloPart 与通用自动绑定框架 UniRig。

宇树机器人上演好莱坞《铁甲钢拳》!网友激动表示:比CG还CG
好莱坞科幻大片《铁甲钢拳》就这样被宇树机器人实现了? 官方划重点:全程完全实拍,无任何加速。 和一名成年男子对打,出拳那叫一个稳准狠:被一脚踢倒后,一个手撑地就立马自己起来了:除了和人类对战,两个机器人也能打得热火朝天:与此同时,宇树科技还剧透最近一个月左右,将开启机器人格斗直播。

预训练还没终结!港中文清华等提出「三位一体」框架,持续自我进化
当前(多模态)大模型正深陷「数据饥渴」困境:其性能高度依赖预训练阶段大量高质量(图文对齐)数据的支撑。 然而,现实世界中这类高价值数据资源正在迅速耗尽,传统依赖真实数据驱动模型能力增长的路径已难以为继。 在NeurIPS 2024会议上,OpenAI联合创始人Ilya Sutskever明确指出:「Pre-training as we know it will end」, 这一判断是对传统预范式极限的清晰警示。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉