在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。
来自清华大学、中国科学院大学、华南理工大学、东北大学、九星(AI9Stars)的联合研究团队提出了一项全新的适应式RAG方法——DeepNote。
它首次引入“笔记(Note)”作为知识载体,实现更深入、更稳定的知识探索与整合,在所有任务上均优于主流RAG方法,相较于基础RAG性能提升高达+20.1%。即使在使用中小参数量模型时,依然展现出强大的能力与泛化性。

研究动机:RAG 为何仍力不从心?
RAG技术通过引入外部知识(如 Wikipedia)来缓解大模型的幻觉与事实错误问题。然而,Vanilla RAG方法只支持一次性检索。
想象一个问题需要跨越多个实体或事实推理,显然“一问一检索一答”的 Vanilla RAG 已远远不够。这种知识不足现象特别是在具有复杂的知识需求的multi-hop QA、long-form QA 等任务中尤为严重。
为了应对这些复杂问答场景,一些研究提出多轮检索RAG。然而,多轮检索RAG往往不假思索地执行多次检索,易引入大量无关或噪声段落,导致检索结果冗杂,从而降低最终回答的质量。
为了进一步构建有效且灵活的RAG系统,一些近期的工作提出自适应RAG,它引入动态决策机制,允许模型根据反馈判断是否继续检索。但自适应RAG方法仍存在以下两个核心问题:
- 检索-生成耦合过紧:每次检索后立即生成答案,导致模型只能依据“当前轮”的知识作答,无法真正整合前后信息;
- 检索策略决策不足:大模型自行判断“是否继续检索”容易偏离真正的知识需求,漏掉关键信息。
这些问题最终都导致一个核心困境:缺乏“信息生长”的能力——模型既无法感知自己是否“学到了新东西”,也无法真正“记住”与“利用”之前获取的信息。
解决方案:DeepNote
为解决上述难题,团队提出了DeepNote,一种以“笔记”为中心、以“知识生长”为目标的深度检索增强生成框架。其关键特性是:用“记下的知识”引导检索,用“最优笔记”生成答案。
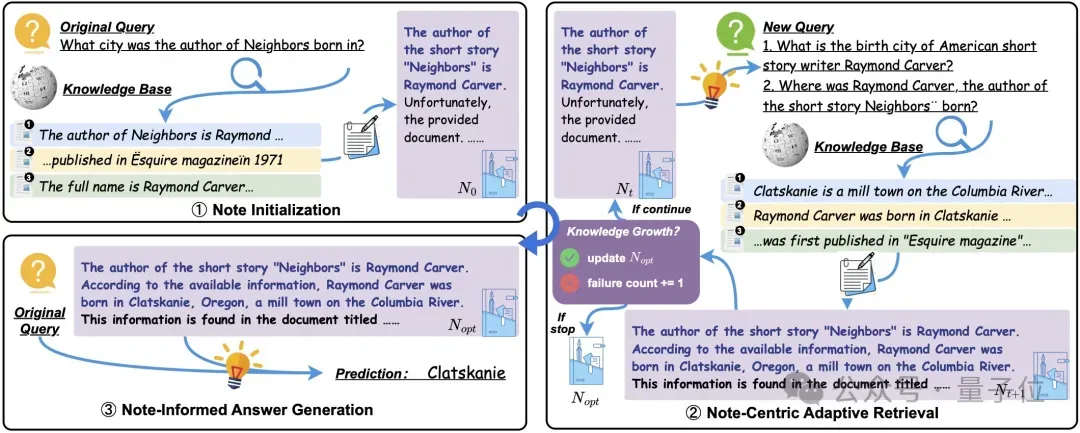
DeepNote主要包含三个阶段:
笔记初始化(Note Initialization)
系统基于初始问题和初次检索内容构建出一份笔记,用于启动整个知识积累过程。该笔记是 LLM 自主整理的结构化知识表示,作为后续所有检索与判断的依据。
基于笔记的适应式检索(Note-Centric Adaptive Retrieval)
系统使用当前“最佳笔记”生成下一轮检索查询,并评估新获取内容是否带来了真正的知识增益。只有当模型判断新知识“有价值”时,才会更新笔记并继续下一轮;否则终止检索。这一机制确保每一轮检索都有明确目标、每一份信息都在“生长”。
基于最佳笔记的答案生成(Note-Informed Answer Generation)
最终,系统使用已积累的“最佳笔记”生成回答,确保答案来源清晰、内容完整、逻辑连贯。这一设计模拟了人类解决复杂问题时的策略:边查边记、反复比对、直至知识充分。
DeepNote与主流方法对比
为了更直观地展现DeepNote的特点,团队整理了与现有代表性方法的能力对比表:
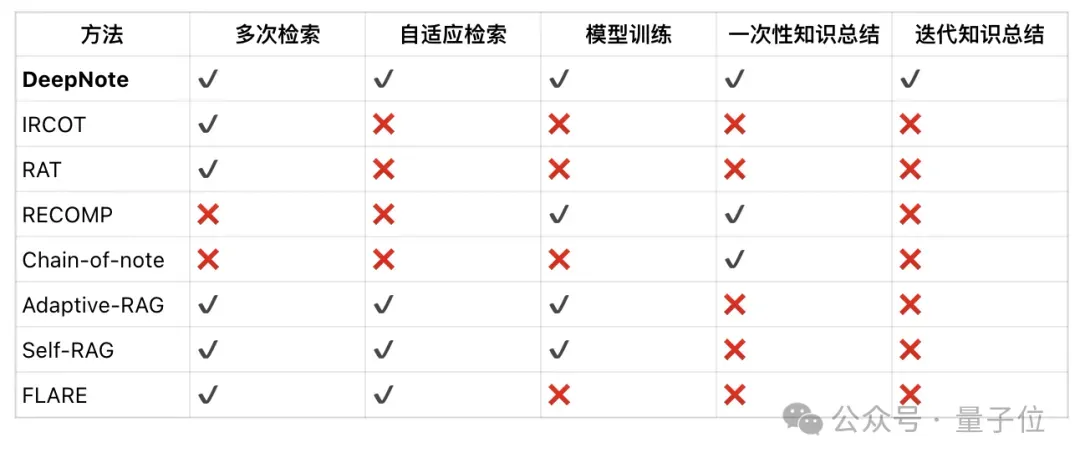
- 多次检索:是否支持多次检索。
- 自适应检索:是否能根据当前信息动态地决定是否需要执行进一步的检索动作以及检索什么。
- 模型训练:是否对不同阶段进行了针对性训练或偏好优化。
- 一次性知识总结:是否在检索后执行一次性检索知识总结。
- 迭代知识总结:是否支持在多轮检索中多次更新、积累、总结知识。
可以看到,DeepNote是目前唯一在自适应检索控制、自适应知识积累与更新、模型优化三大核心维度上同时实现系统性突破的方法。这一框架不仅填补了自适应检索与知识积累之间的空白,更在具有复杂知识需求的任务中展现出前所未有的探索深度和广度,标志着自适应RAG技术迈入了一个新的阶段
实验结果:显著超越现有方法
在五个具有代表性的QA数据集上进行实证评估,涵盖:
- 多跳问答(复杂):HotpotQA, 2WikiMQA, MusiQue
- 长形式问答 (复杂):ASQA
- 短形式问答 (简单):StrategyQA
结果显示,DeepNote在所有任务上均优于主流RAG方法,相较于基础 RAG,性能提升高达+20.1%。即使在使用中小参数量模型时,依然展现出强大的能力与泛化性。

同时团队还构建了一个高质量训练数据集DNAlign,并结合DPO(Direct Preference Optimization)对模型进行精细优化,进一步提升了DeepNote在多任务流程下的指令遵循能力与表现。
核心结论与意义
DeepNote核心优势分析如下
真正实现“信息生长”:
每轮检索不是独立的“抽样”,而是建立在已有知识基础上的持续拓展;
信息密度显著提升:
相比传统RAG,DeepNote的参考内容更紧凑、相关性更高;
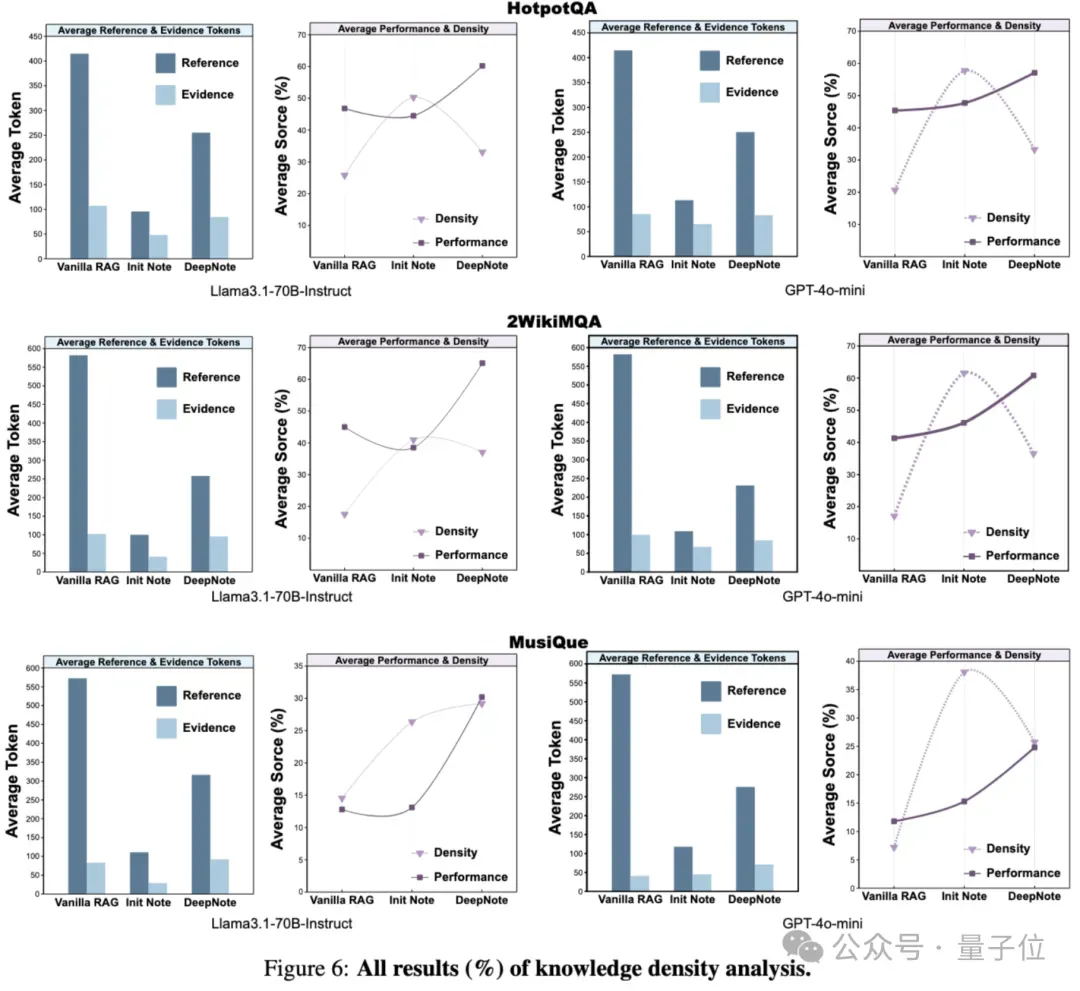
Reference”指最终用于生成回答的检索内容或笔记;其中,与回答问题直接相关的片段被标注为“Evidence”;而“Knowledge Density”则衡量Evidence在Reference中所占比例,用以评估知识的精炼程度。
在知识密度与性能分析中,团队系统考察了不同RAG方法对知识密度和质量的影响。实验结果表明,Vanilla RAG检索文档篇幅冗长但其知识密度较低,存在大量噪声信息;而初始笔记虽然能够通过单次总结有效提升知识密度,但其性能提升主要来自于检索内容总体长度的缩减,且由于知识总量下降,可能会出现性能下降现象。相比之下,DeepNote在保持高知识密度的同时,显著提升了整体性能,表明基于笔记的自适应检索机制能够在降低噪声干扰的同时,持续积累更加丰富、精炼且高相关度的知识,为最终生成提供了更坚实的信息支撑。
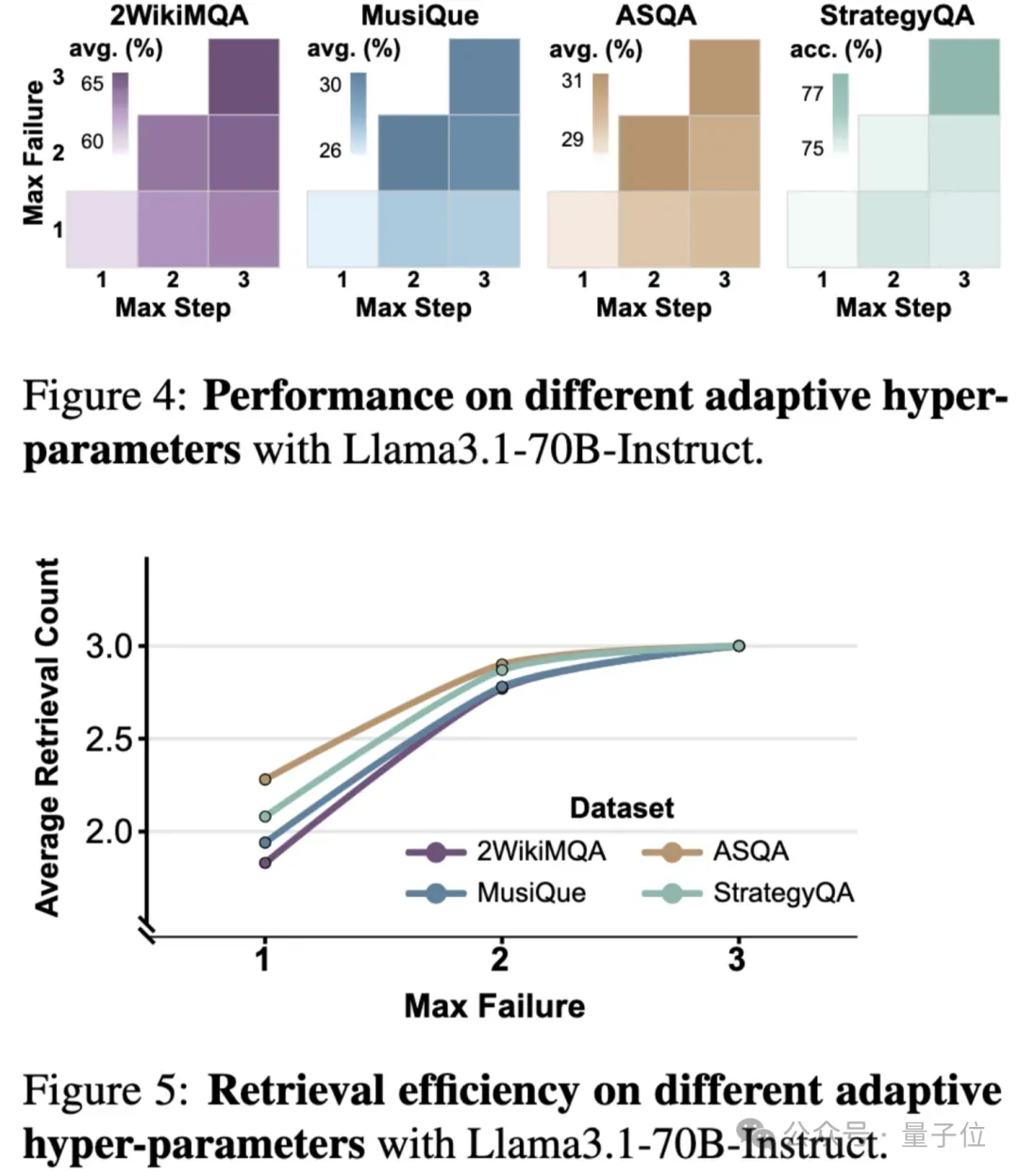
支持自适应停止与深度控制:
用户可设定失败阈值和最大步数,自由权衡探索深度与成本;
高通用性:
可搭配多种开源或闭源模型及检索器,适用于多种实际任务场景。
DeepNote将“记忆式推理”机制引入RAG系统,打破了传统RAG“检索-生成”一步到位的瓶颈,使模型在复杂任务中具备了更接近人类的信息整合与推理能力。
该方法不仅适用于学术研究中对复杂信息的深入问答,还可用于法律、医学、教育等对准确性与知识整合要求极高的真实场景,具备广泛的落地潜力。
本项目由清华大学自然语言处理实验室(THUNLP)、中国科学院大学信息工程研究所、华南理工大学、东北大学等单位共同完成,欢迎感兴趣的研究者和开发者前来交流!
论文地址:https://arxiv.org/abs/2410.08821开源项目: https://github.com/thunlp/DeepNote


