数据

OpenAI 首席技术官:不确定 Sora 的训练数据来自哪里
感谢OpenAI 近期推出了炙手可热的文本转视频生成模型 Sora,然而该公司首席技术官 (CTO) Mira Murati 在接受华尔街日报采访时却语焉不详,无法明确说明 Sora 的训练数据来源。在采访中,记者直接询问 Murati 关于 Sora 训练数据来源时,她仅以含糊的官方话术搪塞:“我们使用的是公开可用数据和许可数据。”当记者追问具体来源是否包含 YouTube 视频时,Murati 竟然表示“我实际上并不确定(I'm actually not sure about that)”,并拒绝回答有关 In

LLaMA-2-7B数学能力上限已达97.7%?Xwin-Math利用合成数据解锁潜力
合成数据持续解锁大模型的数学推理潜力!数学问题解决能力一直被视为衡量语言模型智能水平的重要指标。通常只有规模极大的模型或经过大量数学相关预训练的模型才能有机会在数学问题上表现出色。近日,一项由 Swin-Transformer 团队打造,来自西安交通大学、中国科学技术大学、清华大学和微软亚洲研究院的学者共同完成的研究工作 Xwin 颠覆了这一认知,揭示了通用预训练下 7B(即 70 亿参数)规模的语言模型(LLaMA-2-7B)在数学问题解决方面已经展现出较强的潜力,并可使用基于合成数据的有监督微调方法促使模型愈发

星尘数据MorningStar正式发布!狙击“数据债”成最大看点
3月11日,AI数据技术公司星尘数据(Stardust AI)正式发布MorningStar——一款面向AI的数据闭环产品。 MorningStar是目前首个专注数据价值发现的AI数据平台,基于DataOps的理念打造,全面覆盖AI算法从训练到生产全链路中的数据发现、管理、协作、迭代等各个环节。 ▲MorningStar正式发布数据技术已经推动了人工智能的三次变革。

更全面、更准确的方法,佐治亚理工学院团队用DL对scRNA-seq数据进行批次效应和条件效应建模
编辑 | 萝卜皮单细胞 RNA 测序 (scRNA-seq) 已广泛用于疾病研究,其中在不同条件下(包括人口群体、疾病阶段和药物治疗)从捐赠者中收集样本批次。值得注意的是,此类研究中样本批次之间的差异是批次效应引起的技术混杂因素和条件效应引起的生物变异的混合体。但是,当前的去除批次效应方法往往同时消除技术批次效应和有意义的条件效应,而扰动预测方法仅关注条件效应,导致由于未考虑批次效应而导致基因表达预测不准确。在最新的研究中,佐治亚理工学院(Georgia Institute of Technology,GT)的研究

OpenAI 视频生成服务 Sora 引发隐私担忧,意大利数据监管机构展开调查
感谢意大利数据保护机构 (Garante) 周五宣布,已对微软支持的 OpenAI 公司开发的一项服务展开调查,这个名为 Sora 的服务可以根据文本提示生成视频。监管机构要求 OpenAI 澄清其向用户和非用户告知其产品 Sora 使用的数据的方式是否符合欧盟法规。OpenAI 公司暂未对此事发表评论。意大利数据监管机构是欧盟国家中最为积极的监管机构之一,一直致力于评估人工智能平台是否符合欧盟的数据隐私法规。IT之家注意到,去年该机构就以涉嫌违规使用用户数据为由,禁止了聊天机器人 ChatGPT 在意大利的使用。

想搞AI,高中别学数据科学:奥特曼、马斯克此刻终于一致了
高中阶段学习数据科学能不能代替数学,这个话题的讨论已经延伸到了 AI 圈。为了 AI 的发展,再不加强基础教育就晚了。在大模型技术高速发展,各家公司激烈竞争的同时,有人站出来对于未来的人才表示了担忧,焦点在于数学。近日,加州大学(UC)系统对于入学新生设立数学基础标准的消息掀起了轩然大波。随着全国范围内数学成绩的下降,一些教育工作者认为,标准的代数密集型数学教育需要改革,既可以吸引更多的学生,也可以帮助他们在日益依赖数据的未来培养相关技能。有组织称,目前至少有 17 个州已把「数据科学」作为高中数学教育的可选项,俄

可多模态数据集成、插补和跨模态生成,中科院&树兰医院&北师大团队开发带有掩码模块的深度生成框架
编辑 | 红菜苔随着单细胞技术的发展,许多细胞特性可以被测量。此外,多组学分析技术可以同时联合测量单个细胞中的两个或多个特征。为了快速处理积累的各种数据,需要多模态数据集成的计算方法。树兰医院、中国科学院和北京师范大学的合作团队提出了 inClust ,一个用于多组学分析的深度生成框架。它建立在之前针对转录组数据所开发的 inClust 的基础上,并增加了两个专为多模式数据处理设计的掩码模块:编码器前面的输入掩码模块和解码器后面的输出掩码模块。InClust 可用于整合来自相似细胞群的 scRNA-seq 和 M

ICLR2024 | Harvard FairSeg: 第一个研究分割算法公平性的大型医疗分割数据集
作者 | 田宇编辑 | 白菜叶近年来,人工智能模型的公平性问题受到了越来越多的关注,尤其是在医学领域,因为医学模型的公平性对人们的健康和生命至关重要。高质量的医学公平性数据集对促进公平学习研究非常必要。现有的医学公平性数据集都是针对分类任务的,而没有可用于医学分割的公平性数据集,但是医学分割与分类一样都是非常重要的医学 AI 任务,在某些场景分割甚至优于分类,因为它能够提供待临床医生评估的器官异常的详细空间信息。在最新的研究中,哈佛大学(Harvard University)的Harvard-Ophthalmolo

2023京东零售技术年度盘点
过去一年,围绕开放生态建设、低价心智等主要方向,京东零售技术团队持续攻坚。从百亿补贴、调整流量分配机制为用户提供低价品质好货,到简化商家进驻流程、优化商家体验,带动商家数量增长和平台生态活跃,再到将大模型结合到内部大量业务场景,探索效率提升……快速响应、助力业务的同时,京东零售技术团队继续夯实增强自身能力、探索创新。我们选取了11项有代表性的技术成果,与大家分享。供应链创新技术入围行业最高奖项 京东长期致力于通过前沿的数智化技术和算法,提高供应链效率。2023年,智能供应链团队提出并应用了端到端库存管理技术和可解释

OpenLAM | 深度势能预训练大模型DPA-2发布
在迈向通用大原子模型(Large Atomic Model,LAM)的征途上,深度势能核心开发者团队面向社区,发起 OpenLAM 大原子模型计划。OpenLAM 的口号是“征服元素周期表!”,希望通过建立开源开放的围绕微尺度大模型的生态,为微观科学研究提供新的基础设施,并推动材料、能源、生物制药等领域微尺度工业设计的变革。经过北京科学智能研究院、深势科技、北京应用物理与计算数学研究所等 29 家单位的 42 位合作者的通力协作,深度势能团队近日面向社区发布了深度势能预训练大模型 DPA-2,将成为 OpenLAM

华东政法数据法律研究中心、蚂蚁集团等发布《数据跨域管控白皮书》
12月27日,在“第六届中国数据法律高峰论坛”上,《数据跨域管控白皮书》(以下简称“白皮书”)正式发布。该白皮书由华东政法大学数据法律研究中心、蚂蚁集团牵头,华控清交、华为云、中电数创、广州数据交易所等单位联合参与。白皮书首次系统化给出了数据跨域管控的实操指引,是行业积极响应国家数据流通政策,共同应对数据滥用、数据泄露、责任不清等数据流通风险挑战,助力数据价值释放的重要成果。 (《数据跨域管控白皮书》发布,参编单位代表及嘉宾共同见证)我国已将数据列为重要生产要素,并且鼓励数据要素流通。12月8日,国家数据局局长刘烈

第四范式、南洋理工联合研究成果入围国际顶会 SIGMOD 2024
近日,第四范式与新加坡南洋理工大学教授Shuhao Zhang的最新联合研究成果(乱序数据流中实现主动误差补偿的流式窗口连接,论文标题 PECJ: Stream Window Join on Disorder Data Streams with Proactive Error Compensation),被国际顶级数据库学术会议 SIGMOD 2024 (ACM SIGMOD/PODS International Conference on Management of Data 2024)作为常规研究论文录取。SI

腾讯科技Hi Tech Day暨2023数字开物大会:智能涌现将通往无数的未来
腾讯科技讯 12月14日,以“智能涌现 数开万物”为主题的腾讯科技Hi Tech Day暨2023数字开物大会在北京国家会议中心召开,腾讯科技邀请知名院士、知名经济学家、知名大学教授、研究院院长、产业大咖、互联网大厂高管、知名科技领域头部企业高管、产业数字化转型企业高管等共话AI趋势。大会开场,腾讯新闻运营总经理黄晨霞发表主办方致辞。她回顾了2023年新技术的涌现发展,并提出如何让这些新技术打开真正的产业变革之门,为人类社会创造更多的福祉的思考。黄晨霞表示,在应用落地的路上,我们要厘清大模型的基础还有哪些卡点、AI
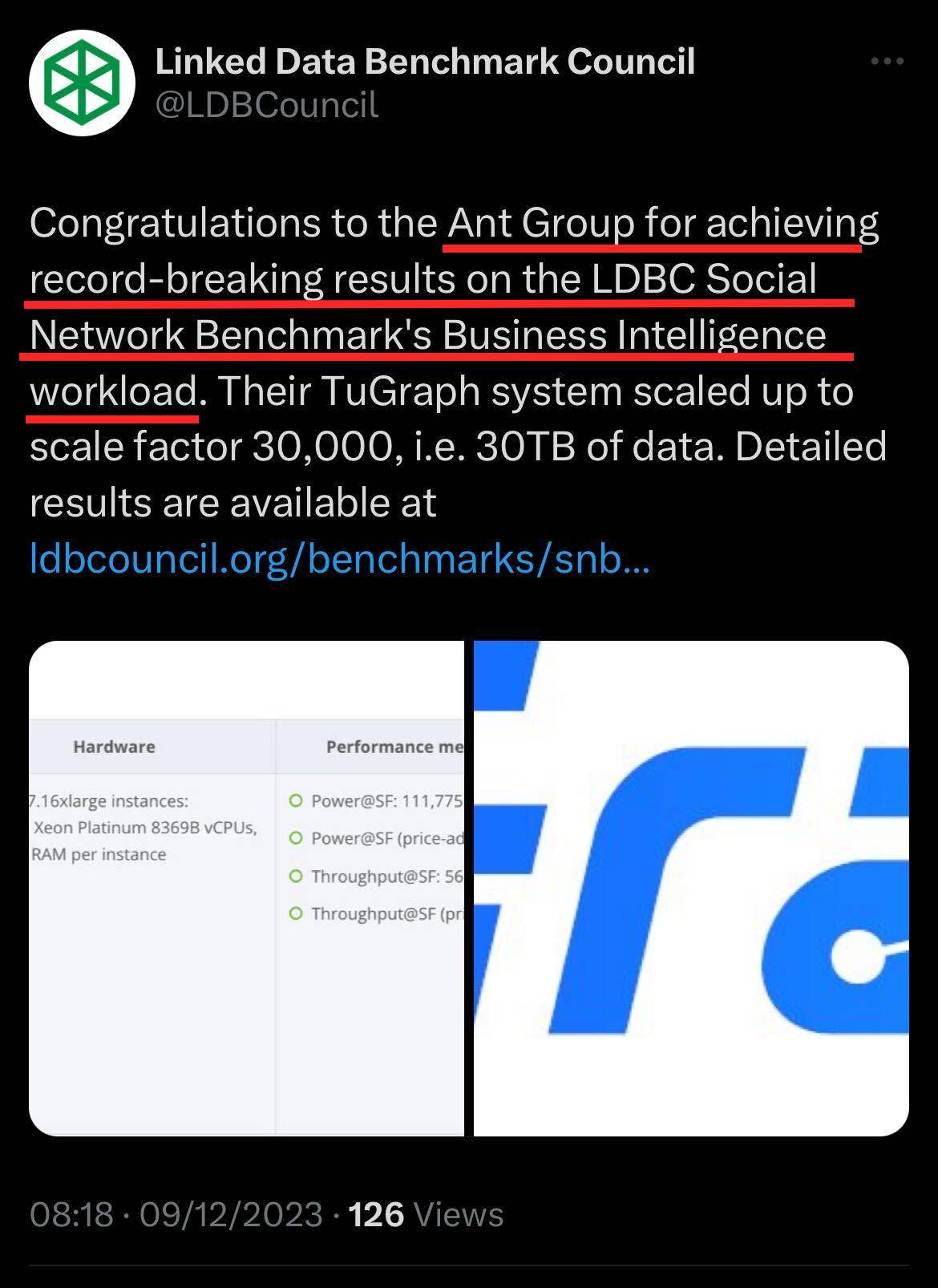
为通用人工智能提速,蚂蚁图计算连续四次打破权威测评世界纪录
近日,国际关联数据基准委员会(Linked Data Benchmark Council,以下简称LDBC)发布了图数据基准测评“LDBC SNB-BI”最新结果。由蚂蚁集团自研的流式图计算引擎TuGraph Analytics在30TB规模的数据集上成功完成了基准测试,数据规模和性能打破了此前美国某图数据库厂商的公开纪录,关键指标中的并发吞吐量提升至2.84倍,查询能力提升至1.86倍。 LDBC官方公布蚂蚁LDBC SNB-BI测评新纪录在本次测评中,测试产品需要快速导入和分析30TB 规模的数据,处理多达72
哈工大与腾讯开发:一种专门针对蛋白质组数据设计的反卷积方法
编辑 | 萝卜皮细胞类型反卷积是一种用于从大量测序数据中确定/解析细胞类型比例的计算方法,并且经常用于分析肿瘤组织样本中的不同细胞类型。然而,由于重复性/再现性、参考标准可变以及缺乏单细胞蛋白质组参考数据的挑战,使用蛋白质组数据分析细胞类型的反卷积技术仍处于起步阶段。哈尔滨工业大学、腾讯 AI lab 以及苏黎世联邦理工学院的研究团队合作开发了一种专门针对蛋白质组数据设计的基于深度学习的反卷积方法(scpDeconv)。scpDeconv 使用自动编码器利用来自批量蛋白质组数据的信息来提高单细胞蛋白质组数据的质量,

哈工大与腾讯团队合作开发:一种专门针对蛋白质组数据设计的深度学习反卷积方法
编辑 | 萝卜皮细胞类型反卷积是一种用于从大量测序数据中确定/解析细胞类型比例的计算方法,并且经常用于分析肿瘤组织样本中的不同细胞类型。然而,由于重复性/再现性、参考标准可变以及缺乏单细胞蛋白质组参考数据的挑战,使用蛋白质组数据分析细胞类型的反卷积技术仍处于起步阶段。哈尔滨工业大学、腾讯 AI lab 以及苏黎世联邦理工学院的研究团队合作开发了一种专门针对蛋白质组数据设计的基于深度学习的反卷积方法(scpDeconv)。scpDeconv 使用自动编码器利用来自批量蛋白质组数据的信息来提高单细胞蛋白质组数据的质量,

1句指令+5美元+20分钟,就能训练出小型专业模型,Prompt2Model了解一下
大规模语言模型(LLM)使用户可以借助提示和上下文学习来构建强大的自然语言处理系统。然而,从另一角度来看,LLM 在特定自然语言处理任务上表现存在一定退步:这些模型的部署需要大量计算资源,并且通过 API 与模型进行交互可能引发潜在的隐私问题。为了应对这些问题,来自卡内基梅隆大学(CMU)和清华大学的研究人员,共同推出了 Prompt2Model 框架。该框架的目标是将基于 LLM 的数据生成和检索方法相结合,以克服上述挑战。使用 Prompt2Model 框架,用户只需提供与 LLM 相同的提示,即可自动收集数据

3000多条数据里选出200条效果反而更好,MiniGPT-4被配置相同的模型超越了
今年四月诞生的多模态大型语言模型 MiniGPT-4 不仅能看图聊天,还能利用手绘草图建网站,可以说是功能强大。而在预训练之后的微调阶段,该模型使用了 3000 多个数据。确实很少,但上海交通大学清源研究院和里海大学的一个联合研究团队认为还可以更少,因为这些数据中大部分质量都不高。他们设计了一个数据选择器,从中选出了 200 个数据,然后训练得到了 InstructionGPT-4 模型,其表现竟优于微调数据更多的 MiniGPT-4!这究竟是如何做到的?
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉