数据

ChatGPT用于科学,如何与你的数据对话?LLM帮你做科研
编辑 | 白菜叶「计算机,分析。」在科幻小说中,人物不需要编程技能来从数据中提取有意义的信息,他们只是简单地提出要求而已。现在,越来越多的公司正尝试利用大型语言模型 (LLM) 将这一幻想变成现实。这些功能强大的人工智能(AI)工具让研究人员能够用自然语言询问数据问题,例如「对照组和实验组有什么区别?」。但与科幻小说中的人工智能不同,这些人工智能给出的答案仍然需要谨慎对待,并经过仔细检查才能安全使用。想想 ChatGPT 的数据。使用这些工具的原因很简单:筛选和确定生物数据的优先顺序是一项费力且具有挑战性的工作,需

基于Transformer的新方法,可从纳米孔测序中准确预测DNA甲基化
编辑 | 萝卜皮DNA 甲基化在各种生物过程中起着重要作用,包括细胞分化、衰老和癌症发展。哺乳动物中最重要的甲基化是5-甲基胞嘧啶,主要发生在 CpG 二核苷酸的背景下。全基因组亚硫酸盐测序等测序方法可以成功检测 5-甲基胞嘧啶 DNA 修饰。然而,它们存在读取长度短的严重缺陷,可能会引入扩增偏差。新加坡 A*STAR 的研究人员开发了一种深度学习算法 Rockfish,该算法通过使用纳米孔测序(Oxford Nanopore Sequencing,ONT)显著提高了读取级 5-甲基胞嘧啶检测能力。该研究以「Roc

苹果、英伟达等公司被曝使用争议 YouTube 资源训练 AI 模型:5.7GB,涉及 4.8 万个频道 17.4 万个视频字幕
非营利性新闻工作室 ProofNews 昨日(7 月 16 日)发布博文,表示包括苹果、英伟达、Salesforce 和 Anthrophic 在内的大型科技公司,在训练其 AI 模型时均使用了来自 YouTube 的视频资源。 报道称这些科技公司在训练其 AI 模型过程中,使用了名为 YouTube Subtitles 的数据集,大小为 5.7GB(4.89 亿个单词)。该数据集由 EleutherAI 创建,最早发布于 2020 年,涉及超过 48000 个频道的 173536 个 YouTube 视频字幕内容
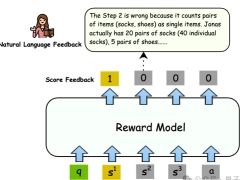
北大千问团队推出数学专用版 CriticGPT,“找茬”让大模型进步更快
批评不仅能让人进步,也能让大模型的能力提升。OpenAI 就用这个思路造了个“找茬模型”CriticGPT。非常巧合的是,就在 CriticGPT 放出的前几天,北大联合千问等团队以类似的思路设计出了“数学专用版”CriticGPT。在无需训练的设置下,验证器能够在推理时辅助模型在 GSM8K 上的准确率从 86.6% 提升到 88.2%。在 GSM8K 数据集上,它可以让模型的准确率从 86.6% 提升到 88.2%。CriticGPT 的核心思路是在代码中故意设置 bug 并进行详细标注,然后用得到的数据训练出

百度智能云(乌镇)AI 数据产业基地启动,将实现当地 AI 原生应用全面落地
感谢“百度智能云”官方公众号发文宣布,由百度智能云与桐乡市乌镇大数据高新技术产业园区合作共建的百度智能云(乌镇)AI 数据产业基地今日正式启动。该基地位于桐乡市乌镇镇“直通乌镇”产业园,双方将携手打造 AI 基础数据要素流通交易集聚地,为乌镇发展大数据与人工智能产业注入新动能,目标是“全国领先”。AI在线从百度智能云方面获悉,乌镇具备健全的数据要素产业,将结合百度智能云千帆大模型、自动驾驶等技术,在当地实现 AI 原生应用的全面落地,百度也将联合生态伙伴培养当地的大模型技术人才。当地将建立“一基地两中心”:人工智能

蚂蚁集团WAIC发布大模型密算平台,助力大模型破解数据供给挑战
大模型向下扎根深入行业,必须要破解高质量数据供给的挑战。7月5日,2024年世界人工智能大会进入第二天,作为数据要素领域的主要技术服务商,蚂蚁集团发布“隐语Cloud”大模型密算平台,通过软硬件结合的可信隐私计算技术,在大模型托管和大模型推理等环节实现数据密态流转,保护模型资产、数据安全和用户隐私。当下,高质量数据供给和安全流通,成为大模型进入垂直产业应用的首要挑战。其一,行业大模型要获得解决专业问题的能力,首先要经过数量充足、质量高的专业数据训练。然而,专业数据往往分散在不同的机构、企业中,并且由于价值大、保密要

腾讯云发布自研大数据高性能计算引擎Meson,性能最高提升6倍
7月4日消息,腾讯云发布全新自研大数据高性能计算引擎Meson。通过软硬一体加速和智能技术的综合应用,该引擎能显著为AI等场景下的大数据任务提供更优的计算性能,并节省更多计算资源。比如,在数据湖场景下,Meson能够助力单个数据查询分析提速6倍,在微信读书“AI问书”项目中,Meson助力大数据任务节省了9成的资源消耗。目前,Meson 已登陆腾讯云数据湖、搜索分析服务、云数据仓库三大业务线,作为统一的计算加速底座,为企业大数据业务提供加速服务。在大数据领域,数据存储和计算是至关重要的核心环节,针对计算和存储的性能

整合多组学数据,华大基因团队图神经网络模型SpatialGlue登Nature子刊
编辑 | KX空间转录组学是继单细胞转录组学出现以来,在生物样本分析领域的又一重大进展。多组学数据的整合至关重要。近日,新加坡科技研究局(A*STAR)、华大基因和上海交通大学医学院附属仁济医院等组成的研究团队,提出了一种具有双注意力机制的图神经网络模型 SpatialGlue,能够以空间感知的方式整合多组学数据。SpatialGlue 能够有效地将多种数据模态与其各自的空间背景相结合,以揭示组织样本的组织学相关结构。研究证明,与其他方法相比,SpatialGlue 可以捕获更多的解剖细节,更准确地解析空间域,例如

有望发力搜索领域,OpenAI 收购数据库分析公司 Rockset
当地时间 6 月 21 日,OpenAI 宣布完成了对数据库检索和分析公司 Rockset 的收购。公司将整合 Rockset 的技术和人员,强化各项产品的检索基础设施。OpenAI 在新闻稿中强调,AI 将有机会改变人们组织、利用自身数据的方式,这便是公司收购 Rockset 的原因。后者是一个提供“世界级”的数据索引、查询功能的实时分析数据库。据悉,Rockset 将使用户、开发人员和企业能够更好地利用自己的数据,并在使用 AI 产品和构建更智能的应用程序时访问实时信息。OpenAI 首席运营官 Brad Li

微软正努力治疗 AI 幻觉,以技术手段实时屏蔽和重写毫无根据的信息
就在 GPT-4 因征服标准化测试而登上头条时,微软研究人员正在对其他 AI 模型进行一种非常另类的测试 —— 一种旨在让模型捏造信息的测试。为了治好这种被称为“AI 幻觉”的症状,他们设定了一个会让大多数人头疼的文本检索任务,然后跟踪并改进模型响应,这也是微软在测定、检测和缓解 AI 幻觉方面的一个例子。微软 AI 负责项目的首席产品官 Sarah Bird 表示,“微软希望其所有 AI 系统都是值得信赖且可以有效使用的”。我们可以向这个领域投入许多专家和资源,因此我们认为自己可以帮助阐明“应该如何负责任地使用新

英伟达开源 3400 亿巨兽:98% 合成数据训出最强开源通用模型,性能对标 GPT-4o
【新智元导读】刚刚,英伟达全新发布的开源模型 Nemotron-4 340B,有可能彻底改变训练 LLM 的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B 直接超越了 Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和 GPT-4 掰手腕!就在刚刚,英伟达再一次证明了自己的 AI 创新领域的领导地位。它全新发布的 Nemotron-4 340B,是一系列具有开创意义的开源模型,有可能彻底改变训练 LLM 的合成数据生

揭秘100年全球海洋脱氧,上交大通过人工智能重建「窒息的海洋」,ICML已收录
作者 | 卢彬,韩璐羽海洋溶解氧是维持海洋生态系统功能的关键因子。然而,随着全球变暖和人类活动影响加剧,近年来海洋呈现脱氧趋势,日渐窒息的海洋对渔业发展、气候调节等多方面造成严重后果。近期,上海交通大学电子信息与电气工程学院王新兵、甘小莺教授团队联合上海交通大学海洋学院张经院士、周磊教授、周韫韬副教授,共同提出了一种稀疏海洋观测数据驱动的深度图学习模型 OxyGenerator,首次对 1920 年至 2023 年全球百年海域溶解氧数据进行重建,重建性能显著超越了专家经验主导的 CMIP6 系列数值模式结果。研究成

消息称苹果 AI 服务器将使用“机密计算”技术来处理数据,保护用户隐私
苹果即将在 WWDC 大会上公布其人工智能战略,该战略将作为 iOS 18 及其他操作系统更新的一部分发布。IT之家注意到,此前彭博社报道,苹果计划采用一种结合设备端处理和服务器端处理的混合方式来实现人工智能功能。然而,将用户数据处理转移至苹果的服务器也引发了隐私方面的担忧,尤其是在苹果多年来一直大力推广设备端处理的情况下。据《The Information》报道,苹果似乎找到了一个解决方案,既可以在其云端提供强大的 AI 处理能力,又能保持严格的隐私标准。《The Information》的报道称,苹果计划采用“
全国数据标准化技术委员会正式批复筹建
2024年5月24日下午,第七届数字中国建设峰会主论坛在福州召开。国家数据局党组书记、局长刘烈宏,国家市场监管总局党组成员、副局长,国家标准委主任田世宏等出席会议。会上,田世宏宣读了“关于筹建全国数据标准化技术委员会的通知”。全国数据标准化技术委员会将负责数据资源、数据技术、数据流通、智慧城市、数字化转型等基础通用标准,以及支撑数据流通利用的数据基础设施标准和保障数据流通利用的安全标准制修订工作。筹建单位和业务指导单位为国家数据局,秘书处承担单位为中国电子技术标准化研究院。全国数据标准化技术委员会将在国家数据局指导

估值飙至 138 亿美元,27 岁天才少年再获融资:数据标注会是下一个风口?
【新智元导读】Alexandr Wang 创办的 Scale AI 是一个为 AI 模型提供训练数据的数据标注平台,近期完成新一轮 10 亿美元融资,估值飙升至 138 亿美元。该公司表示将利用新资金生产丰富的前沿数据,为通向 AGI 铺平道路。Scale AI 为想要训练机器学习模型的公司提供数据标注服务,已从亚马逊和 Meta 等众多知名机构和企业投资者那里筹集了 10 亿美元的 F 轮融资。本轮融资由 Accel 领投,它之前还领投了 Scale AI 的 A 轮融资,并参与了后续的风险投资。这轮融资让 Sc

欧盟数据保护委员会:ChatGPT 的“数据准确性”仍未达标
据路透社报道,欧盟数据保护委员会的一个特别工作组近期表示,尽管 OpenAI 在减少 ChatGPT 输出信息的错误率上做出了一定努力,但它仍然不足以确保“完全符合”欧盟的数据规则。当地时间周五,该工作组发布了一份报告并指出,“为了遵守透明度的原则,OpenAI 采取了一些措施,也有利于避免 ChatGPT 输出错误信息,但这些措施仍然不足以遵守数据准确性的原则。”图源 PexelsIT之家注:以意大利政府为首的国家监管机构此前对广泛使用的 AI 服务提出了担忧,欧盟数据保护委员会随后成立了“ChatGPT 特别工
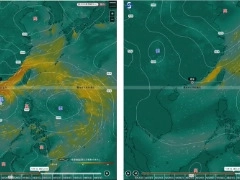
用 AI 预报未来 0-15 日天气状况,中国气象局发布气象预报大模型示范计划
据《中国气象报》消息,在日前的第七届数字中国建设峰会・数字气象分论坛期间,中国气象局发布了人工智能气象预报大模型示范计划。该计划旨在推进大模型标准规范和有序发展,引导解决预报业务实际难题,促进人工智能气象预报大模型业务的应用转化、准入,打造人工智能技术研发应用的创新生态。示范计划对象为人工智能气象预报大模型,将使用中国气象局提供的实时实况分析数据作为输入场,制作未来 0 至 15 天的气象预报。据悉,示范内容包含高空气象要素、地面气象要素、定量降水预报、台风路径及强度预报、灾害性天气过程预报等 5 类预报产品。上述
北京:推进数字疗法、AI 辅助治疗等产品研发应用,支持医疗大模型开发、落地
北京市人民政府办公厅今日印发《北京市加快医药健康协同创新行动计划(2024-2026 年)》,提到人工智能技术、大模型、算力等一系列内容。IT之家汇总部分重点任务:实施医疗大数据共享与应用。建设全市共享的门急诊、住院、体检、科研等电子病历体系。推动标准化、信息化临床研究数据共享,明确数据脱敏标准,打通医院之间数据链接。推动检验结果、医疗影像在全市三级医院实现互联互通互认。推动医院开展医疗大数据的登记、评估、流通,拓展在创新研发端应用。推动临床样本数字化管理使用。建立面向全市开放、充分保护隐私的临床样本共享信息系统和
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉