数据

提高光学数据集利用率,天大团队提出增强光谱预测效果 AI 模型
编辑 | 枯叶蝶近日,天津大学激光与光电子研究所吴亮副教授、姚建铨院士团队联合自然语言处理实验室熊德意教授团队报道了一种使用多频率补充输入的深度学习模型来增强光谱预测效果的方案。该方案可有效地提高现有光学数据集的利用率,在不额外增加训练成本的基础上,增强了与超表面结构对应的光谱响应的预测效果。相关研究成果以「Enhanced spectrum prediction using deep learning models with multi-frequency supplementary inputs」为题,于 20
绕过直接数值模拟或实验,生成扩散模型用于湍流研究
编辑 | 绿罗了解湍流平流粒子的统计和几何特性是一个具有挑战性的问题,对于许多应用的建模、预测和控制至关重要。例如燃烧、工业混合、污染物扩散、量子流体、原行星盘吸积和云形成等。尽管过去 30 年在理论、数值和实验方面做出了很多努力,但现有模型还不能很好地再现湍流中粒子轨迹所表现出的统计和拓扑特性。近日,意大利罗马第二大学(University of Rome Tor Vergata)的研究人员,提出了一种基于最先进的扩散模型的机器学习方法,可以在高雷诺数的三维湍流中生成单粒子轨迹,从而绕过直接数值模拟或实验来获得可

数据更多更好还是质量更高更好?这项研究能帮你做出选择
当计算预算低时,重复使用高质量数据更好;当不差钱时,使用大量数据更有利。对基础模型进行 scaling 是指使用更多数据、计算和参数进行预训练,简单来说就是「规模扩展」。虽然直接扩展模型规模看起来简单粗暴,但也确实为机器学习社区带来了不少表现卓越的模型。之前不少研究都认可扩大神经模型规模的做法,所谓量变引起质变,这种观点也被称为神经扩展律(neural scaling laws)。近段时间,又有不少人认为「数据」才是那些当前最佳的闭源模型的关键,不管是 LLM、VLM 还是扩散模型。随着数据质量的重要性得到认可,已
ChatGPT 可以实时互动分析 Excel 数据了,网友挖出背后新模型
【新智元导读】GPT-4o 之后,ChatGPT 又迎来更新。这次,数据分析能力再上一个新台阶,将支持谷歌、微软在线文档上传,并实时交互,自定义图表。更重要的是,网友已经灰度测试到背后的新模型了。ChatGPT 更强了...刚刚,OpenAI 再次放出大招 ——ChatGPT 可以直接打开线上数据文件,完成实时数据分析。全新的增强功能,具体包括:- 直接从 Google Drive 和 Microsoft OneDrive 上传最新版本的文件- 在新的可扩展视图中与表格和图表进行交互- 自定义并下载图表,用于演示文

微软发布 MatterSim 模型:模拟材料、预测性能,AI 探索材料设计的无限可能
微软研究院科学智能中心(Microsoft Research AI for Science)近日推出 MatterSim 模型,能够在广泛的元素、温度和压力范围内,准确高效地模拟材料和预测性能,助力材料设计的数字化转型。新材料探索对纳米电子学、能量储存和医疗健康等多个领域的技术进步至关重要。材料设计中的一个核心难点是如何在不进行实际合成和测试的情况下预测材料属性。由于新材料可能涉及元素周期表中 118 种元素的任意组合,且其合成和工作温度、压力范围极广,这些因素极大地影响了材料内部原子的相互作用,使得准确预测材料属
Nature 子刊,纠缠数据有双重效应,武大、北大「量子纠缠」研究新进展
编辑 | X量子纠缠是量子计算的核心资源。将纠缠集成到量子机器学习(QML)模型的测量中,导致训练数据大小大幅减少,超过指定的预测误差阈值。然而,对数据纠缠度如何影响模型性能的分析理解仍然难以捉摸。在此,来自武汉大学、北京大学、南洋理工大学和悉尼大学的研究团队,通过建立量子「没有免费的午餐」 (no-free-lunch,NFL) 定理来解决这一知识差距。与之前的发现相反,研究证明纠缠数据对预测误差的影响表现出双重效应,具体取决于允许的测量数量。通过足够数量的测量,增加训练数据的纠缠可以一致地减少预测误差,或减小实
从基因组到蛋白质组连续翻译,南开大学开发通用跨模态数据分析方法
编辑 | 萝卜皮近期,科学家在单个细胞内同时分析多组学模态的进展,使得细胞异质性和分子层次结构的研究成为可能。然而,技术限制导致多模态数据的高噪声和高昂的成本。在这里,南开大学的研究团队提出了 scButterfly,一种基于双对齐变分自动编码器和数据增强方案的多功能单细胞跨模态翻译方法。通过对多个数据集的全面实验,研究人员证明 scButterfly 在保留细胞异质性、同时翻译各种背景的数据集和揭示细胞类型特异性生物学解释方面优于基线方法。同时,scButterfly 可应用于单模态数据的综合多组学分析、低质量单

美国酝酿 AI「登月计划」,陶哲轩领衔 62 页报告重磅发布
【新智元导读】就在刚刚,陶哲轩领衔的一份 62 页报告出炉了,总结和预测了 AI 对半导体、超导体、宇宙基础物理学、生命科学等领域带来的巨大改变。如果这些预测在几十年后能够实现,美国酝酿的 AI「登月计划」就将成真。就在刚刚,陶哲轩领衔的一份 AI 技术对全球研究潜在影响的技术报告发布了。这份报告长达 62 页,总结了 AI 对材料、半导体设计、气候、物理、生命科学等领域已经做出的改变,以及预测它们在未来可能由 AI 产生的改变。报告地址: AI 工具已经改变的科学领域的小插曲,陶哲轩等人还发出了三个呼吁 ——1.

平均准确率达96.4%,中山大学&重庆大学开发基于Transformer的单细胞注释方法
编辑 | 萝卜皮使用测序 (scATAC-seq) 技术对转座酶可及的染色质进行单细胞测定,可在单细胞分辨率下深入了解基因调控和表观遗传异质性,但由于数据的高维性和极度稀疏性,scATAC-seq 的细胞注释仍然具有挑战性。现有的细胞注释方法大多集中在细胞峰矩阵上,而没有充分利用底层的基因组序列。在这里,中山大学与重庆大学的研究人员提出了一种方法 SANGO,通过在 scATAC 数据中的可及性峰周围整合基因组序列来进行准确的单细胞注释。SANGO 在跨样本、平台和组织的 55 个配对 scATAC-seq 数据集
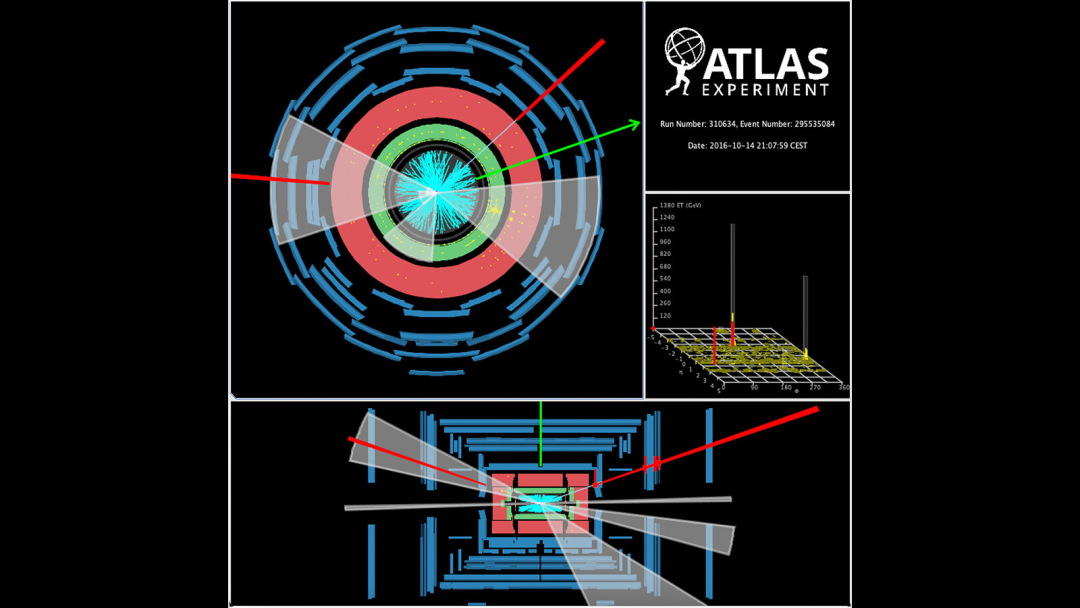
172个机构合作,发现奇异粒子,机器学习分析约1.6亿次粒子碰撞数据
ATLAS 事件显示了本研究中神经网络发现的与标准模型预测偏差最大的八个事件之一。(来源:欧洲核子研究中心)编辑 | X粒子物理学家的任务是挖掘大量不断增长的碰撞数据,寻找尚未发现的粒子证据。特别是,他们正在寻找未包含在粒子物理标准模型中的粒子,科学家怀疑我们目前对宇宙构成的理解是不完整的。近日,来自 ATLAS 合作组的 172 个研究机构的科学家,使用一种受大脑启发的机器学习算法——神经网络,来筛选大量粒子碰撞数据,搜索数据中的异常特征或异常现象。研究团队使用一种称为异常检测的机器学习方法来分析大量 ATLAS

中国电信开源 TeleChat-12B 星辰语义大模型,年内开源千亿级参数大模型
感谢中国电信已开源 120 亿参数 TeleChat-12B 星辰语义大模型,还表示将于年内开源千亿级参数大模型。相较 1 月开源的 7B 版本,12 版版本在内容、性能和应用等方面整体效果提升 30%,其中多轮推理、安全问题等领域提升超 40%。据介绍,TeleChat-12B 将 7B 版本 1.5T 训练数据提升至 3T,优化数据清洗、标注策略,持续构建专项任务 SFT (监督微调) 数据,优化数据构建规范,大大提升数据质量;同时,基于电信星辰大模型用户真实回流数据,优化奖励模型和强化学习模型,有效提升模型问

你的自拍和聊天记录,正被硅谷大厂砸数十亿美元疯抢
新智元报道 编辑:Aeneas 好困【新智元导读】2026 年的数据荒越来越近,硅谷大厂们已经为 AI 训练数据抢疯了!它们纷纷豪掷十数亿美元,希望把犄角旮旯里的照片、视频、聊天记录都给挖出来。不过,如果有一天 AI 忽然吐出了我们的自拍照或者隐私聊天,该怎么办?谁能想到,我们多年前的聊天记录、社交媒体上的陈年照片,忽然变得价值连城,被大科技公司争相疯抢。现在,硅谷大厂们已经纷纷出动,买下所有能购买版权的互联网数据,这架势简直要抢破头了!图像托管网站 Photobucket 的陈年旧数据,本来已经多年无人问津,但

报告称 OpenAI 采集了超一百万小时的 YouTube 视频来训练 GPT-4
本周早些时候,《华尔街日报》报道称 AI 公司在收集高质量训练数据方面遇到了困难。今天,《纽约时报》详细介绍了 AI 公司处理此问题的一些方法,其中涉及到属于 AI 版权法模糊灰色区域的内容。报道称,OpenAI 迫切需要训练数据,并开发了 Whisper 音频转录模型来克服困难,转录了超过 100 万小时的 YouTube 视频来训练其最先进的大型语言模型 GPT-4。报道提到,OpenAI 在 2021 年耗尽了有用的数据供应,并在耗尽其他资源后讨论了转录 YouTube 视频、播客和有声读物的可行性。此外,O

弱智吧竟成最佳中文 AI 训练数据?中科院等:8 项测试第一,远超知乎豆瓣小红书
离大谱了,弱智吧登上正经 AI 论文,还成了最好的中文训练数据??具体来说,使用弱智吧数据训练的大模型,跑分超过百科、知乎、豆瓣、小红书等平台,甚至是研究团队精心挑选的数据集。在问答、头脑风暴、分类、生成、总结、提取等 8 项测试中取得最高分。没错,论文中的 Ruozhiba 就是指百度贴吧弱智吧,一个充满荒谬、离奇、不合常理发言的中文社区,画风通常是这样的:最离谱的是,弱智吧 AI 代码能力也超过了使用专业技术问答社区思否数据训练的 AI,这下吧友自己都闹不明白了。其他平台围观网友也纷纷蚌埠住。这项研究来自中科院

联合国际顶尖高校 昆仑万维开源数字智能体研发工具包AgentStudio
AgentStudio旨在为研究人员和开发者提供一个覆盖智能体完整开发流程的综合性平台,让开发者们能够轻松、高效、灵活地构建专属数字智能体。

可用于训练“常见皮肤疾病”AI,谷歌推出 SCIN 数据集
谷歌官方新闻稿,谷歌近日与斯坦福大学医学院合作,收集了涵盖各种肤色、身体部位皮肤疾病照片,整合而成一款用于 AI 训练的“SCIN 数据集”,该数据集号称“完全使用志愿者利用网络提交的照片”,因此号称可以“反映出人们常见的皮肤问题”。▲ 图源 谷歌官方新闻稿(下同)谷歌提到,业界许多医疗专用的皮肤科影像数据集中通常为“重大疾病”,例如人们常见的皮疹、过敏、感染等照片通常不会在数据集中,因此对于应擅长判定人们日常疾病的 AI 模型使用业界常用的医疗专业数据集做训练反而有所缺憾。而谷歌目前推出的 SCIN 数据集收录了

腾讯AI Lab 3篇蛋白质组论文入选国际顶级期刊,为阐释生命提供重要技术参考
编辑 | ScienceAI只有蛋白质组才能从根本上阐释生命。3月20日,腾讯 AI Lab实验室3篇蛋白质组论文相继入选国际顶级学术期刊,论文分别在蛋白质组的检测、分析以及探索发现方面提出全新的研究方案,为人类从根本上阐释生命提供重要技术参考。科学界曾经认为,只要绘制出人类基因组序列图,就能了解疾病的根源,但事实并非如此。相同的基因往往有不同的表达,比如,人体不同组织器官的基因组是一样的,但是各个组织器官的蛋白质组不完全一样。人和鼠的基因组的差别仅为1%,但是其形态、性状差别非常大,这就是蛋白质组不一样的体现。中

大模型增速远超摩尔定律!MIT 最新研究:人类快要喂不饱 AI 了
【新智元导读】近日,来自 MIT (麻省理工学院)的研究人员发表了关于大模型能力增速的研究,结果表明,LLM 的能力大约每 8 个月就会翻一倍,速度远超摩尔定律!硬件马上就要跟不上啦!我们人类可能要养不起 AI 了!近日,来自 MIT FutureTech 的研究人员发表了一项关于大模型能力增长速度的研究,结果表明:LLM 的能力大约每 8 个月就会翻一倍,速度远超摩尔定律!论文地址: 的能力提升大部分来自于算力,而摩尔定律代表着硬件算力的发展,—— 也就是说,随着时间的推移,终有一天我们将无法满足 LLM 所需要
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉