扩散模型

数字化头像新秀 Lemon Slice 获得 1050 万美元融资,推动 AI 聊天机器人的视频化
数字头像生成公司 Lemon Slice 近日宣布,已获得1050万美元的种子融资,投资方包括 Matrix Partners、Y Combinator,以及知名企业高管和音乐组合 The Chainsmokers。 该公司旨在为 AI 聊天机器人增加视频层,通过其最新的扩散模型 Lemon Slice-2,能够仅通过一张图片生成动态数字头像。 Lemon Slice-2是一款拥有200亿参数的模型,可以在单个 GPU 上以每秒20帧的速度直播视频。

后生可畏!何恺明团队新成果发布,共一清华姚班大二在读
henry 发自 凹非寺. 量子位 | 公众号继今年5月提出MeanFlow (MF) 之后,何恺明团队于近日推出了最新的改进版本——. Improved MeanFlow (iMF),iMF成功解决了原始MF在训练稳定性、指导灵活性和架构效率上的三大核心问题。
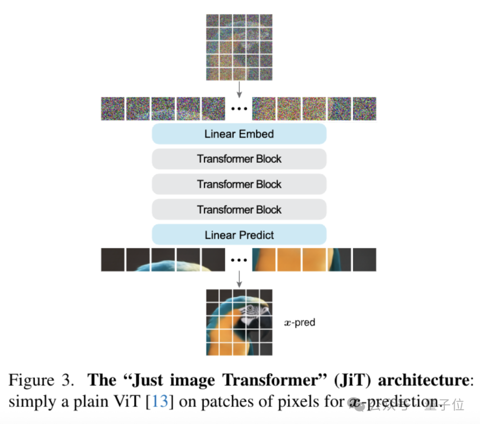
何恺明团队新作:扩散模型可能被用错了
闻乐 发自 凹非寺. 量子位 | 公众号 QbitAI何恺明又一次返璞归真。 最新论文直接推翻扩散模型的主流玩法——不让模型预测噪声,而是直接画干净图。

5000万美元种子轮融资!斯坦福教授创立Inception,用“扩散式大模型”挑战GPT-5,代码生成速度超1000 token/秒
当全球AI竞赛仍围绕自回归大模型(如GPT-5、Gemini)激烈缠斗时,一家新锐初创公司正以颠覆性架构悄然突围。 由斯坦福大学教授Stefano Ermon领衔的AI公司Inception近日宣布完成5000万美元种子轮融资,由Menlo Ventures领投,微软M12、英伟达NVentures、Snowflake Ventures、Databricks Investment及Mayfield跟投,吴恩达(Andrew Ng)与Andrej Karpathy亦以天使投资人身份加入,阵容堪称豪华。 Inception的核心押注,是将原本用于图像生成的扩散模型(Diffusion Models)全面引入文本与代码领域,挑战当前主流的自回归范式。

变分掩码扩散模型:解决并发标记预测中的依赖关系问题
研究背景与问题定义基于扩散的大型语言模型(DLLMs)作为自回归模型(ARMs)的重要扩展,正在成为生成式AI领域的重要创新方向。 与传统ARMs按预定义顺序顺序生成标记的方式不同,DLLMs提供了并发标记生成、更高输出多样性、增强全局一致性以及更好的生成文本可控性等优势。 近期的突破性模型如LLaDA、Mercury和Gemini Diffusion都凸显了DLLMs的潜力。

近500页史上最全扩散模型修炼宝典,宋飏等人一书覆盖三大主流视角
关于扩散模型的一切,宋飏等人写成了 460 多页的书。 扩散模型(Diffusion Models) ,几乎重塑了整个生成式 AI 的版图。 从图像到音频,从视频到 3D 世界。

ICCV 2025 | 扩散模型生成手写体文本行的首次实战,效果惊艳还开源
本文中,来自华南理工大学、MiroMind AI、新加坡国立大学以及琶洲实验室的研究者们提出一种新的生成模型 Diffusion Brush,首次将扩散模型用于文本行级的手写体生成,在英文、中文等多语言场景下实现了风格逼真、内容准确、排版自然的文本行生成。 研究背景AI 会写字吗? 在写字机器人衍生换代的今天,你或许并不觉得 AI 写字有多么困难。

清华、NVIDIA、斯坦福提出DiffusionNFT:基于前向过程的扩散强化学习新范式,训练效率提升25倍
清华大学朱军教授团队, NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。 该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化,在彻底摆脱似然估计与特定采样器依赖的同时,显著提升了训练效率与生成质量。 文章共同一作郑凯文和陈华玉为清华大学计算机系博士生。

兼得快与好!训练新范式TiM,原生支持FSDP+Flash Attention
TiM团队 投稿. 量子位 | 公众号 QbitAI生成式AI的快与好,终于能兼得了? 从Stable Diffusion到DiT、FLUX系列,社区探索了很多技术方法用于加速生成速度和提高生成质量,但是始终围绕扩散模型和Few-step模型两条路线进行开发,不得不向一些固有的缺陷妥协。

ACM MM 2025 | 小红书AIGC团队提出风格迁移加速新算法STD
基于一致性模型(Consistency Models, CMs)的轨迹蒸馏(Trajectory Distillation)为加速扩散模型提供了一个有效框架,通过减少推理步骤来提升效率。 然而,现有的一致性模型在风格化任务中会削弱风格相似性,并损害美学质量 —— 尤其是在处理从部分加噪输入开始去噪的图像到图像(image-to-image)或视频到视频(video-to-video)变换任务时问题尤为明显。 这一核心问题源于当前方法要求学生模型的概率流常微分方程(PF-ODE)轨迹在初始步骤与其不完美的教师模型对齐。

揭秘扩散模型:深入了解DALL-E和Midjourney背后的技术
译者 | 布加迪审校 | 重楼本文介绍了最流行的图像生成模型架构之一的技术层面。 近年来,生成式AI模型已成为一颗冉冉升起的新星,尤其是随着ChatGPT等大语言模型(LLM)产品闪亮登场。 这类模型使用人类能够理解的自然语言,可以处理输入,并提供合适的输出。

华人团队终结Token危机:扩散模型数据潜力超自回归三倍
Token危机真的要解除了吗? 最新研究发现,在token数量受限的情况下,扩散语言模型的数据潜力可达自回归模型的三倍多。 不仅如此,一个参数规模为1B的扩散模型,用1B tokens进行480个周期的训练,就在HellaSwag和MMLU基准上分别取得56%和33%的准确率,且未使用任何技巧或数据筛选。
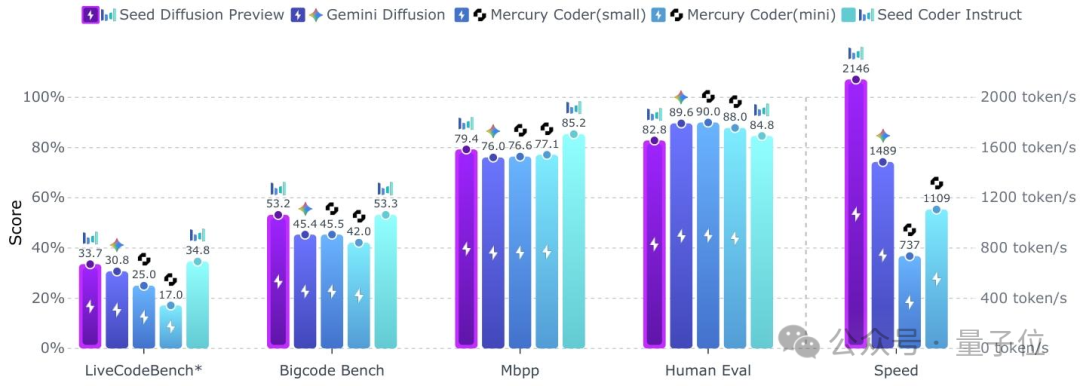
字节Seed发布扩散语言模型,推理速度达2146 tokens/s,比同规模自回归快5.4倍
用扩散模型写代码,不仅像开了倍速,改起来还特别灵活! 字节Seed最新发布扩散语言模型Seed Diffusion Preview,这款模型主要聚焦于代码生成领域,它的特别之处在于采用了离散状态扩散技术,在推理速度上表现出色。 在H20上,它的代码推理速度能达到2146tokens/s,比同类的Mercury和Gemini Diffusion等模型快不少,同时比同等规模的自回归模型快5.4倍,并且在代码编辑任务中更具优势。
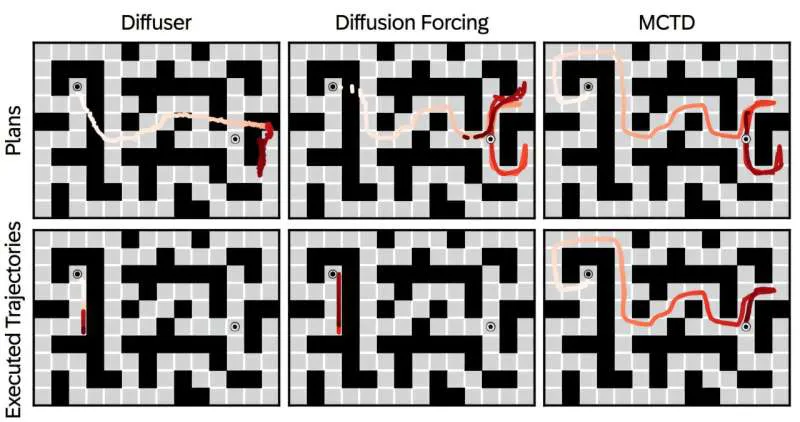
图灵奖得主加持,蒙特卡洛树搜索×扩散模型杀回规划赛道|ICML 2025 Spotlight
henry 发自 凹非寺量子位 | 公众号 QbitAI一个不起眼的迷宫导航任务,却能让一众模型“原形毕露”。 Diffuser和Diffusion Forcing双双翻车,通关率低得可怜。 唯独有一个模型,通关率高达 100%。

物理学家靠生物揭开AI创造力来源:起因竟是“技术缺陷”
不圆 发自 凹非寺. 量子位 | 公众号 QbitAIAI的“创造力”居然是一种技术缺陷? ?

谢赛宁团队新作:不用提示词精准实现3D画面控制
henry 发自 凹非寺量子位 | 公众号 QbitAI曾几何时,用文字生成图像已经变得像用笔作画一样稀松平常。 但你有没有想过拖动方向键来控制画面? 像这样,拖动方向键(或用鼠标拖动滑块)让画面里的物体左右移动:还能旋转角度:缩放大小:这一神奇操作就来自于谢赛宁团队新发布的 Blender Fusion框架,通过结合图形工具 (Blender) 与扩散模型,让视觉合成不再仅仅依赖文本提示,实现了精准的画面控制与灵活操作。

苹果在AI领域取得重大进展,图像生成技术可与DALL-E和Midjourney相媲美
苹果公司的机器学习研究团队开发出了一种突破性的AI系统,该系统能够生成高分辨率图像,可能对以DALL-E和Midjourney等流行图像生成器所依赖的扩散模型的主导地位构成挑战。 这项在上周发表的研究论文中详细介绍的技术名为“STARFlow”,是由苹果研究人员与学术合作伙伴共同开发的,该系统结合了标准化流(normalizing flows)与自回归Transformer,实现了研究团队所称的“与最先进的扩散模型相比具有竞争力”的性能。 这一突破发生在苹果面临AI领域批评声浪日益高涨的关键时刻。

CVPR2025|不改U-Net也能提升生成力!MaskUNet用掩码玩转扩散模型
一眼概览MaskUNet 提出了一种基于可学习掩码的参数筛选机制,在不更新预训练U-Net参数的前提下,有效提升了扩散模型的图像生成质量和下游泛化能力。 核心问题当前扩散模型在不同时间步使用相同U-Net参数生成结构和纹理信息,限制了模型的表达灵活性。 该研究聚焦于:如何在不更改预训练U-Net的参数下,提升其对不同时间步和样本的适应性,以生成更高质量的图像?
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉