在人工智能的不断发展中,扩散模型在推理能力上逐渐崭露头角,现如今,它们不再是自回归模型的 “跟随者”。近日,来自加州大学洛杉矶分校(UCLA)和 Meta 的研究者们联合推出了一种名为 d1的新框架,该框架结合了监督微调(SFT)和强化学习(RL),使扩散模型具备更强的推理能力,包括数学理解、逻辑推理等。

这一创新的 d1框架通过两阶段的后训练策略来提升掩码大语言模型(dLLM)的性能。在第一阶段,模型通过高质量的推理轨迹进行监督微调,从而掌握基础知识和逻辑推理能力。接着,在第二阶段,研究者们引入了一种名为 diffu-GRPO 的新型策略梯度方法,这一方法专门针对掩码 dLLM 进行了优化,大幅提高了推理效率。
与以往的研究相比,d1的提出旨在解决扩散模型在强化学习后训练中的挑战。传统的自回归模型通过对生成序列的对数概率进行计算,从而优化模型的输出,而 dLLM 则因其迭代生成的特性,面临计算上的困难。为此,研究团队开发了一种高效的对数概率估计器,通过独立计算每个 token 的概率,极大地减少了计算时间并提高了训练效率。
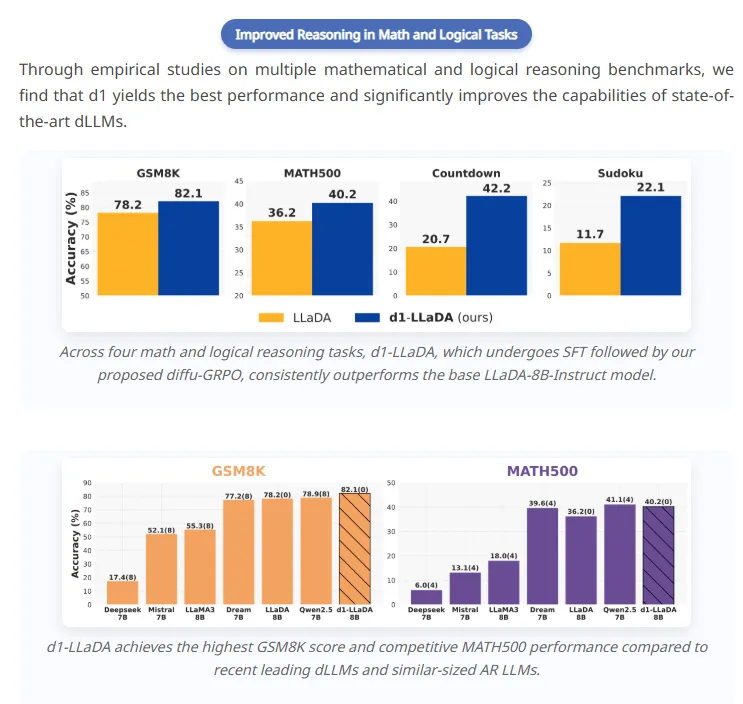
在实验中,研究者使用 LLaDA-8B-Instruct 作为基础模型,比较了 d1-LLaDA 与仅使用 SFT 或 diffu-GRPO 训练的模型。结果显示,d1-LLaDA 在多个数学和逻辑推理测试中表现优异,远超基础模型和单一方法。这一组合式的方法不仅增强了模型的推理能力,还展示了良好的协同效应。
随着 d1框架的推出,扩散模型在推理任务中的表现将迎来新的提升,也为后续的研究提供了广阔的空间。研究者们相信,这一创新的框架将推动语言模型的进一步发展,助力更复杂的推理和逻辑任务的实现。
项目地址:https://top.aibase.com/tool/d1


