henry 发自 凹非寺
量子位 | 公众号 QbitAI
曾几何时,用文字生成图像已经变得像用笔作画一样稀松平常。
但你有没有想过拖动方向键来控制画面?
像这样,拖动方向键(或用鼠标拖动滑块)让画面里的物体左右移动:

还能旋转角度:
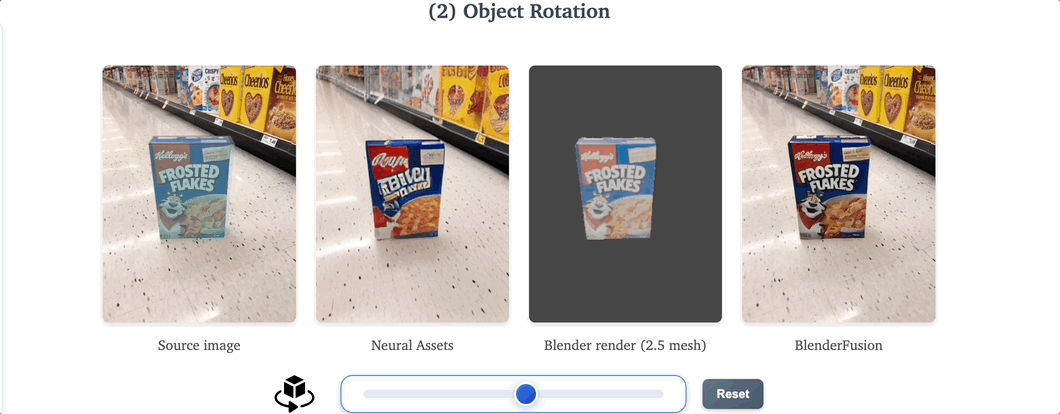
缩放大小:
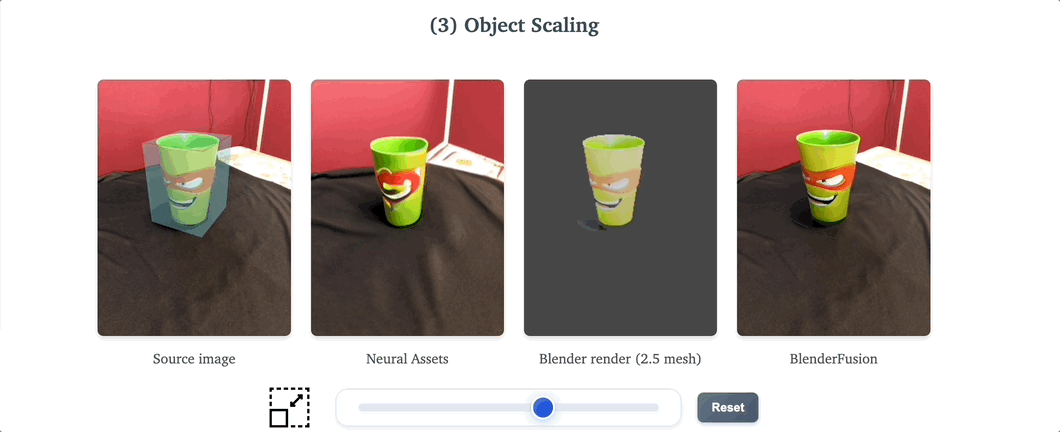
这一神奇操作就来自于谢赛宁团队新发布的 Blender Fusion框架,通过结合图形工具 (Blender) 与扩散模型,让视觉合成不再仅仅依赖文本提示,实现了精准的画面控制与灵活操作。

图像合成三步走
BlenderFusion “按键生图” 的核心并不在于模型自身的创新,而在于其对现有技术(分割、深度估计、Blender渲染、扩散模型)的高效组合,打通了一套新的Pipeline 。
这套Pipeline包含三个步骤:先将物体和场景分离 → 再用Blender做3D编辑 → 最后用扩散模型生成高质量合成图像。
接下来看看每一步都是怎么做的吧!
第一步:以物体为中心的分层。(Object-centric Layering)
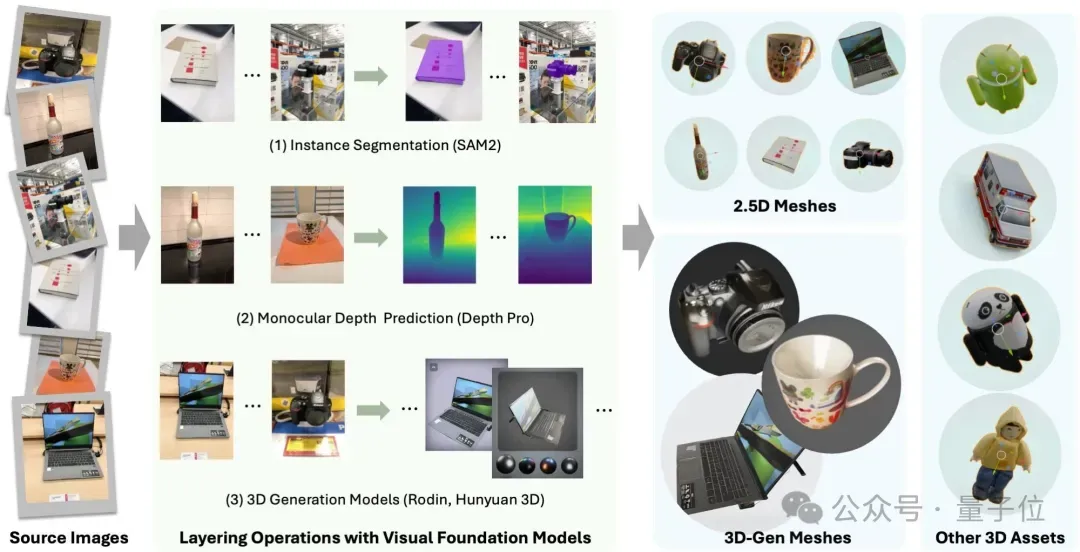
第一步是将输入的图像或视频中的各个物体从原有的场景中分离,并推断出它们的三维信息。
具体来说,BlenderFusion利用现有强大的视觉基础模型进行分割和深度估计:用Segment Anything Model(SAM)分割画面中的物体,用Depth Pro模型进行深度推断赋予物体深度。
通过对每一个被分割出的物体进行深度估计,将来自图像或视频的2D输入投影到3D空间,从而为后续的3D编辑奠定基础。
这种做法避免了从头训练3D重建模型,充分利用了现成的大规模预训练能力。
第二步:基于Blender的编辑(Blender-grounded Editing)

第二步是将分离出的物体导入Blender进行各种精细化编辑。在Blender中,既可以对物体进行多种操作(颜色、纹理、局部编辑、加入新物体等),也可以对相机进行控制(如相机视点和背景变化)。
第三步:生成式合成(Generative Compositing)
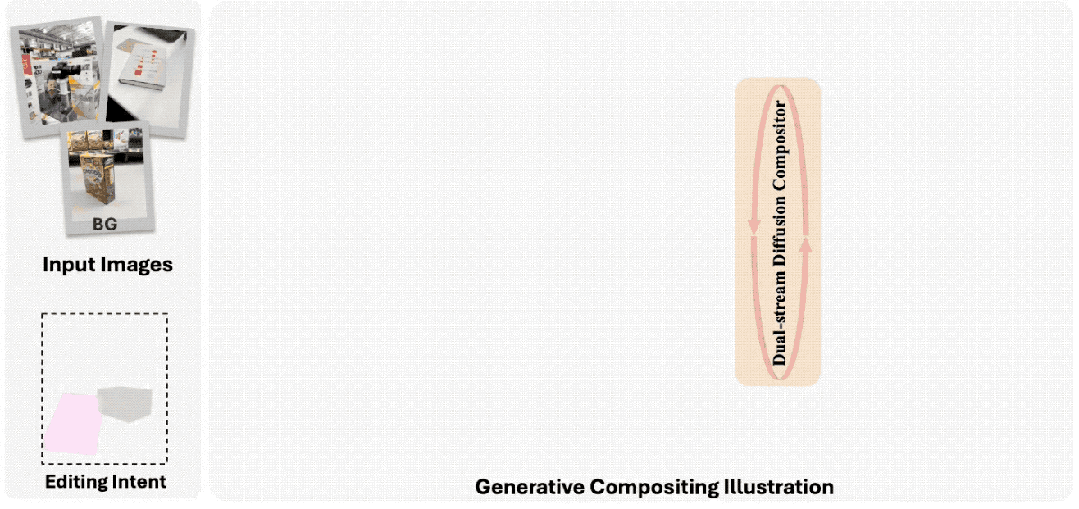
虽然通过Blender渲染后的场景在空间结构上高度准确,但外观、纹理和光照仍然相对粗糙。
因此,在流程的最后一步,Blender Fusion引入了扩散模型(SD v2.1)对结果进行视觉增强。
为此,Blender Fusion提出了双流扩散合成器(dual-stream diffusion compositor)。
该模型同时接收:原始输入场景(未编辑)和编辑后的粗渲染图像。通过对比两者,模型学习在保持全局外观一致性的同时,仅在需要编辑的区域进行高保真改动。这样可以避免传统扩散模型“重绘全图”导致的失真,也防止未修改部分的退化。
一些trick
此外,为了提高Blender Fusion的泛化性,论文中还透露了两项重要的训练技巧:
源遮挡(Source Masking):在训练时随机遮蔽源图部分,迫使模型学会基于条件信息恢复完整图像。
模拟物体抖动(Simulated Object Jittering):模拟物体的随机偏移和扰动,提高对相机和物体的解耦能力。这一组合显著提升了生成结果的真实感和一致性。
结果演示
Blender Fusion在针对物体和相机操控的视觉生成中取得了不错的效果。
正如我们在文章开头的demo中所演示的,通过任意控制方向键来控制物体在图像中的位置,画面保持了较强的一致性与连贯性。
此外,Blender Fusion还能够在各种复杂的场景编辑中保持空间关系和视觉连贯性,主要包括:
单幅图像处理:灵活地重新排列、复制和变换物体,以及改变相机视角。

多图像场景重组:组合任何图像中的物体以创建全新的场景。

泛化:这些编辑功能成功地推广到训练期间未见过的物体和场景。

在AI视觉合成越来越卷的当下,Blender Fusion就像给创作者多了一只“第三只手”。
用户不再被提示词困住,也不需要反复试错就能拼出理想画面。
从物体分层到三维编辑,再到高保真生成,这套流程不仅让AI图像合成更“听话”,也让玩法更自由。
或许,你的下一次生图将不再是“遣词造句”,而是能像搭积木一样,把每个细节都亲手摆到位。
论文地址: https://arxiv.org/abs/2506.17450 项目页面: https://blenderfusion.github.io/#compositing 一键三连「点赞」「转发」「小心心」欢迎在评论区留下你的想法!— 完 —
专属AI产品从业者的实名社群,只聊AI产品最落地的真问题 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
进群后,你将直接获得:
👉 最新最专业的AI产品信息及分析 🔍
👉 不定期发放的热门产品内测码 🔥
👉 内部专属内容与专业讨论 👂
🌟 点亮星标 🌟 科技前沿进展每日见

