1. 一眼概览
MaskUNet 提出了一种基于可学习掩码的参数筛选机制,在不更新预训练U-Net参数的前提下,有效提升了扩散模型的图像生成质量和下游泛化能力。
2. 核心问题
当前扩散模型在不同时间步使用相同U-Net参数生成结构和纹理信息,限制了模型的表达灵活性。该研究聚焦于:如何在不更改预训练U-Net的参数下,提升其对不同时间步和样本的适应性,以生成更高质量的图像?
3. 技术亮点
- 参数掩码机制:提出可学习的二值掩码,对预训练U-Net的参数进行筛选,使其在不同时间步与样本中发挥最大效能;
- 双重优化策略:设计基于训练(使用扩散损失)与免训练(使用奖励模型)的两种掩码优化方法,适应不同场景需求;
- 广泛验证:在COCO及多个下游任务(图像定制、关系反转、文本转视频)中验证,展示优越性能和强泛化能力。
4. 方法框架
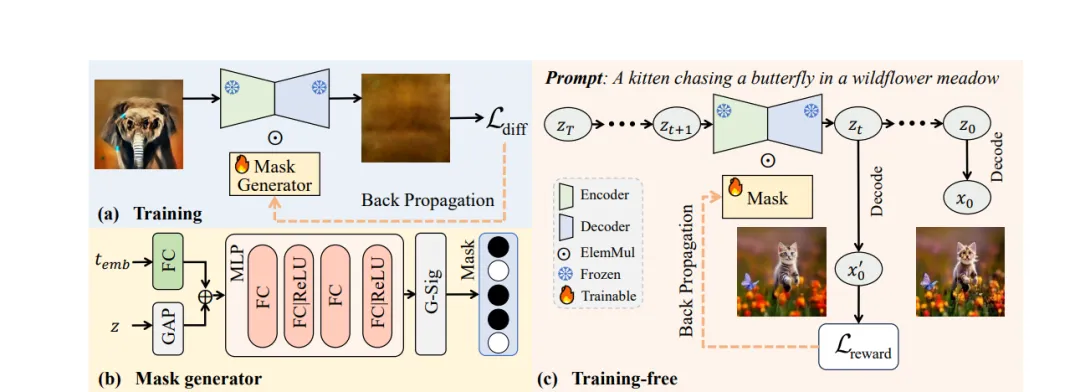 图片
图片
MaskUNet方法如下图流程所示:
- 引入掩码机制:对预训练U-Net参数施加时间步和样本相关的二值掩码,实现参数选择性激活;
- 训练方式一:带监督学习:通过MLP生成掩码,联合时间嵌入与样本特征进行训练,目标函数为扩散损失;
- 训练方式二:免训练优化:借助奖励模型(如ImageReward与HPSv2)指导掩码更新,无需额外训练掩码生成器。
该机制不修改原U-Net参数结构,而是通过灵活的掩码动态激活权重,从而提升模型表达能力。
5. 实验结果速览
 图片
图片
在COCO 2014和COCO 2017两个文本到图像的零样本生成任务中,MaskUNet相较于原始的Stable Diffusion 1.5与LoRA方法,在图像质量指标(FID)上均有显著提升。例如,在COCO 2014数据集上,MaskUNet将FID分数从12.85降低至11.72,COCO 2017上则从23.39降至21.88,表现出更强的生成能力。同时,在图文一致性方面(CLIP分数)与其他方法持平,说明MaskUNet在不影响语义对齐的前提下,显著增强了图像质量。
在多个下游任务如DreamBooth图像定制、Textual Inversion新概念学习、ReVersion关系图像生成以及Text2Video-Zero文本转视频中,MaskUNet均展现出更强的个性化表达能力与细节还原能力,进一步验证了其作为通用增强组件的实用价值。
6. 实用价值与应用
MaskUNet方法适用于文本生成图像、视频生成、图像定制、关系表达等任务,尤其在无需大规模参数更新的资源受限场景下表现出色,适合作为轻量级增强模块嵌入现有扩散框架中。
7. 开放问题
• 掩码机制在跨模态生成(如音频到图像)任务中是否同样有效?
• MaskUNet是否可以与LoRA等参数高效微调方法协同工作以实现更强性能?
• 如何进一步压缩掩码生成模块的计算量,使其适用于移动端或边缘设备?


