用扩散模型写代码,不仅像开了倍速,改起来还特别灵活!
字节Seed最新发布扩散语言模型Seed Diffusion Preview,这款模型主要聚焦于代码生成领域,它的特别之处在于采用了离散状态扩散技术,在推理速度上表现出色。

在H20上,它的代码推理速度能达到2146tokens/s,比同类的Mercury和Gemini Diffusion等模型快不少,同时比同等规模的自回归模型快5.4倍,并且在代码编辑任务中更具优势。
Seed Diffusion Preview以结构化的代码生成为实验领域,系统性地验证离散扩散技术路线作为下一代语言模型基础框架的可行性。

下面介绍它的具体技术细节。
自回归模型存在串行解码延迟瓶颈,理论上,扩散模型的并行生成潜力和整体性生成的优势可以解决自回归模型推理速度局限这一痛点。
但理论优势与实际效果还是有差距,离散扩散模型在语言任务中的大规模部署仍面临两大核心瓶颈:归纳偏置冲突和推理效率瓶颈。
为解决上述问题,Seed Diffusion Preview采用了四项关键的技术创新。
两阶段训练是模型的核心训练策略。
这是针对离散扩散过程设计的渐进式训练方案,两个阶段分别采用不同的corruption过程(即对原始数据的扰动方式)。通过分阶段优化模型对token的理解与生成能力,平衡训练效率与生成质量。
第一个阶段是基于掩码的扩散训练,学习上下文补全,占整个训练步骤的80%。
目标是将原始序列中的token替换为特殊的[MASK]标记,让模型学习从部分被掩盖的序列中恢复原始token,以此奠定基础的语言建模能力。
第二个阶段是基于编辑的扩散训练,增强全局的合理性。
掩码训练可能带来“捷径依赖”的问题——优先利用未掩码token的局部关联性进行恢复,而非理解整个序列的全局逻辑。
此阶段的目标就是通过插入、删除、替换等编辑操作对原始序列进行扰动,并用编辑距离衡量扰动程度,编辑次数由特定函数控制在合理范围内,打破模型对未掩码token的错误认知,迫使模型重新评估所有token。
实证表明,引入编辑阶段后,模型在代码修复基准CanItEdit上的pass@1对比自回归模型(AR模型)提升了4.8%(54.3vs.50.5),明显增强了模型的代码逻辑理解与修复能力。
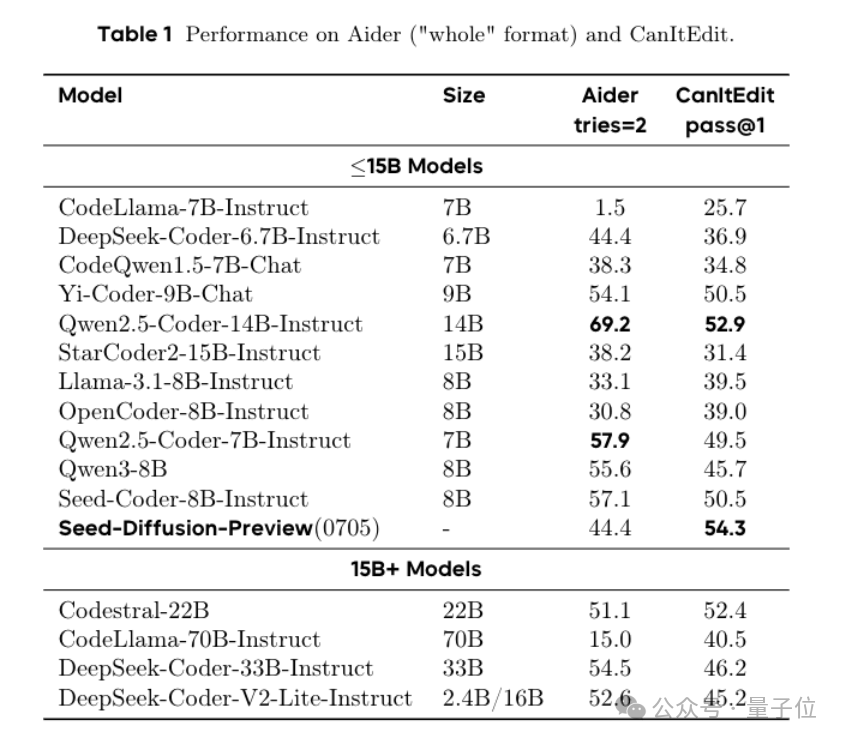
为解决离散扩散模型在代码生成中“逻辑混乱”的问题,团队设计引入代码的结构化先验,核心是让模型遵循代码固有的“规矩”。
虽然代码这类语言不像说话那样又严格的从左到右逻辑,但它有很强的因果关系——比如变量要先声明才能用等。
为了让模型懂这些规矩,团队提出约束顺序训练:先让模型通过内部的预训练模型,大量模拟正确的代码生成过程,然后像提炼公式一样,把这些正确的生成顺序浓缩成模型能够学会的规律。
这样模型在生成代码时就能自觉遵循这些结构化的逻辑,不再乱序生成。
在Seed Diffusion模型中,生成速度的优化通过多重策略协同实现。
首先,采用同策略学习范式(on-policy),让模型在训练时直接使用当前策略生成的采样轨迹进行参数更新,确保训练数据与模型当前能力高度匹配,减少策略偏差带来的效率损耗,加速采样策略的迭代优化,从算法层面提升生成效率。
简单说就是模型边生成代码边学习。模型用现在的本事生成一段代码过程,然后就用这个过程的数据来改进自己,这样学的东西就和自己当前的能力很匹配,不会因为用老数据而走弯路,能更快地把生成代码的策略优化好。
为平衡计算资源与生成延迟,模型采用块级并行扩散采样方案。该方案将生成序列划分为多个块,在扩散采样过程中对这些块进行并行处理,而非逐token串行生成。
这样既能把电脑的计算能力充分用起来,又不会因为一次处理太长的内容而耽误时间,能在计算量和生成速度之间找到合适的平衡,比如调整块的大小,就能灵活控制速度和效率。
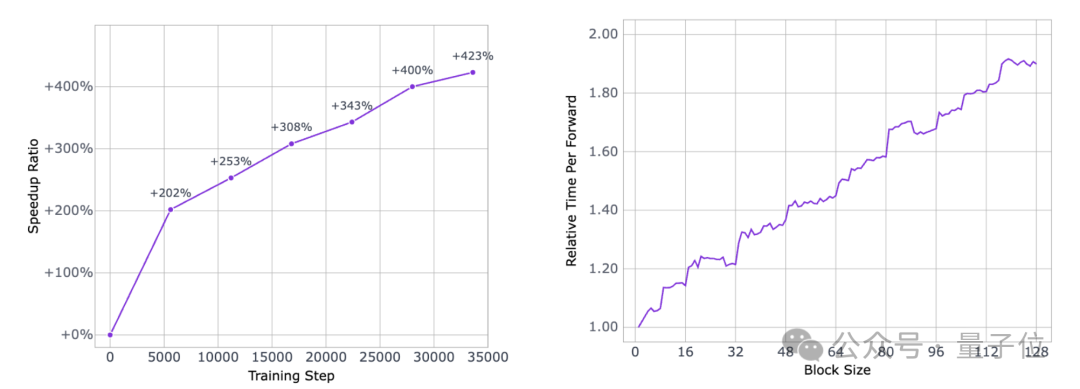
此外,模型还依托内部基础设施框架进行系统级优化,包括硬件资源调度、计算流程精简等,进一步降低采样过程中的冗余开销,最终实现了推理速度的显著提升。
团队通过一系列实验验证了模型在代码生成领域的优势,核心成果体现在推理速度的大幅提升、生成质量的竞争力以及关键技术的有效性三个方面:
在H20上可达每秒2146个token,同时保持了代码生成质量的竞争力,性能与优秀模型相当,尤其是在代码编辑任务中优势更明显。
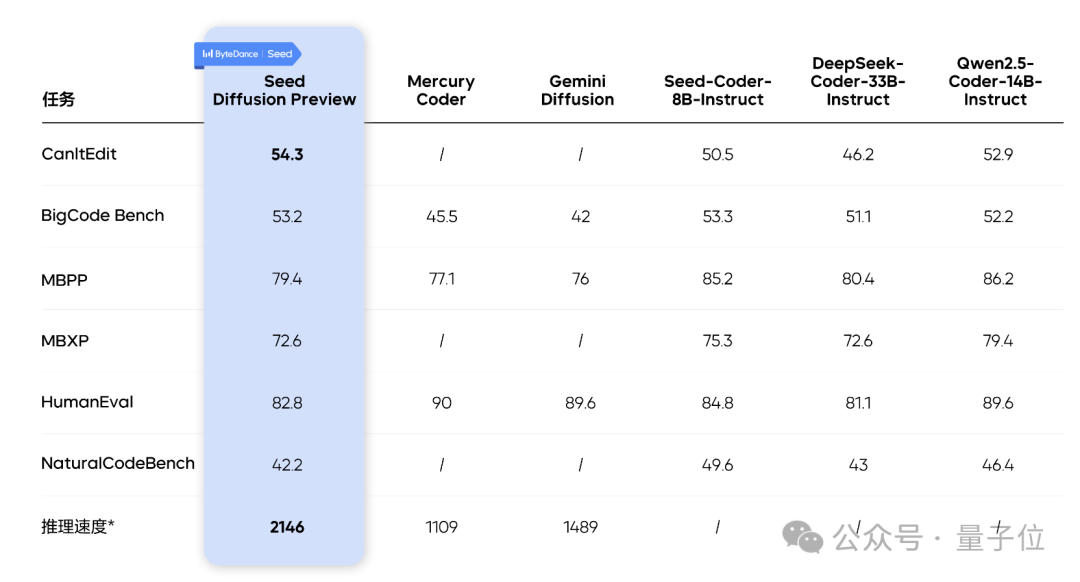
Seed Diffusion Preview的测试结果验证了了离散扩散路线在大语言模型推理上的潜力。
一个小tip:Seed Diffusion项目组正在招募研究型实习生,如果你基础能力过关、代码能力优秀,并且对探索下一代大模型范式感兴趣,可以一试~
技术报告:https://lf3-static.bytednsdoc.com/obj/eden-cn/hyvsmeh7uhobf/sdiff_updated.pdf 项目地址:https://seed.bytedance.com/seed_diffusion 体验链接:https://studio.seed.ai/exp/seed_diffusion
— 完 —
量子位 QbitAI
关注我们,第一时间获知前沿科技动态