多模态

月之暗面开源 Kimi-2506:多模态智能体,视觉理解能力重大升级
近日,国内知名大模型平台 “月之暗面” 正式发布了其开源的多模态模型 Kimi-VL-A3B-Thinking 的最新版本 ——Kimi-2506。 这一版本的发布标志着智能体和视觉理解技术的重大进步。 Kimi-2506的开源地址为 [此处插入链接],而在线演示可在 [此处插入链接] 进行体验。

Chrome内置AI多模态提示功能详解与实战
距离我上次撰写关于Chrome内置AI功能的博客已经过去了几周,随着本周Google IO大会的召开,涌现了许多新公告和更新。 您可以在Chrome开发者博客上找到近期变化的详细说明:"AI API现已进入稳定版和原始试用阶段,并推出新的早期预览计划API"。 最让我期待的一项功能终于发布了——多模态提示。

多模态推理模型(LMRM):从感知到推理的演变
大家好,我是肆〇柒。 当下,人工智能正以前所未有的速度改变着我们的生活与工作方式。 其中,推理作为人工智能的核心能力之一,赋予了智能体在复杂环境中做出决策、得出结论以及进行知识泛化的能力。

多模态大模型不会画辅助线?最新评估得分:o3仅25.8%,远低于人类82.3%
多模态时代应如何评估模型的视觉输出能力? 来自清华大学、腾讯混元、斯坦福大学、卡耐基梅隆大学等顶尖机构的研究团队联合发布了RBench-V:一款针对大模型的视觉推理能力的新型基准测试。 过去的评估基准主要集中于评估多模态输入和纯文本推理过程。

多模态混合检索与多智能体RAG的破局之道
AI的感知困境:一只眼睛的世界我们习惯了AI能够处理文字、分析数据,但在处理复杂信息时,传统AI面临着三大感知困境:文字与图像割裂好比戴着眼罩工作的设计师,AI只能读懂文字,却看不懂图表中的趋势线、饼图中的占比关系。 OCR技术让AI能提取图像中的文字,却无法理解一张财务图表所传达的"销售额正在快速增长"这类视觉信息。 这就像让一个人只通过摸索来理解一幅画,注定失之偏颇。

字节发布14B参数多模态神器BAGEL,碾压Qwen2.5-VL,图像生成媲美SD3
字节跳动Seed团队在Hugging Face平台重磅发布BAGEL,一款基于混合专家(MoE)架构的开源多模态基础模型,拥有14亿总参数和7亿活跃参数。 BAGEL在数万亿token的交错多模态数据集上预训练,性能超越Qwen2.5-VL和InternVL-2.5,图像生成质量媲美SD3,并支持复杂推理任务如自由图像编辑、未来帧预测和3D生成,引发全球AI社区热议。 AIbase综合最新社交媒体动态,深入解析BAGEL的技术亮点及其对多模态AI领域的革命性影响。

字节跳动开源多模态模型 BAGEL:图文生成与编辑的新突破
字节跳动 发布了一款名为 BAGEL 的开源多模态基础模型,拥有70亿个活跃参数,整体参数量达到140亿。 BAGEL 在标准多模态理解基准测试中表现出色,超越了当前一些顶级开源视觉语言模型,如 Qwen2.5-VL 和 InternVL-2.5。 此外,在文本到图像的生成质量上,BAGEL 的表现也与强大的专业生成器 SD3相媲美。

谷歌Gemma 3n发布!可在手机上流畅跑多模态AI,音频+图像+文本全能
谷歌在I/O2025大会上正式揭晓Gemma3n,一款专为低资源设备设计的多模态AI模型,仅需2GB RAM即可在手机、平板和笔记本电脑上流畅运行。 Gemma3n继承了Gemini Nano的架构,新增音频理解功能,支持文本、图像、视频和音频的实时处理,且无需云端连接,彻底颠覆了移动端AI体验。 AIbase综合最新社交媒体动态,深入解析Gemma3n的技术亮点及其对AI生态的影响。

多模态检索大升级!智源三大SOTA模型,代码、图文理解能力拉满
检索增强技术在代码及多模态场景中的发挥着重要作用,而向量模型是检索增强体系中的重要组成部分。 针对这一需求,近日,智源研究院联合多所高校研发了三款向量模型,包括代码向量模型BGE-Code-v1,多模态向量模型BGE-VL-v1.5以及视觉化文档向量模型BGE-VL-Screenshot。 这些模型取得了代码及多模态检索的最佳效果,并以较大优势登顶CoIR、Code-RAG、MMEB、MVRB等领域内主要测试基准。
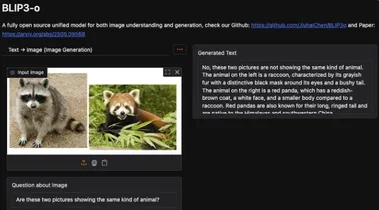
Salesforce BLIP3-o重磅登陆Hugging Face!全开源多模态模型,图像理解与生成一统江湖!
Salesforce AI Research在Hugging Face平台正式发布BLIP3-o应用,这款全开源的统一多模态模型家族以其卓越的图像理解与生成能力引发业界热议。 BLIP3-o通过创新的扩散变换器架构,结合语义丰富的CLIP图像特征,不仅提升了训练效率,还显著优化了生成效果。 AIbase综合最新社交媒体动态,深入解析BLIP3-o的技术突破及其对AI生态的影响。

深度解析大模型技术演进脉络:RAG、Agent与多模态的实战经验与未来图景
作者 | jaymie大模型作为产业变革的核心引擎。 通过RAG、Agent与多模态技术正在重塑AI与现实的交互边界。 三者协同演进,不仅攻克了数据时效性、专业适配等核心挑战,更推动行业从效率革新迈向业务重构。

Ollama推出全新多模态AI引擎,推理性能显著提升
前不久,Ollama 宣布推出一款全新的多模态 AI 引擎,这款引擎的研发是独立于原有的 llama.cpp 框架进行的,标志着公司在人工智能领域迈出了重要一步。 这一引擎是基于 Golang 编程语言开发,旨在大幅提高本地推理的精度,同时增强大型图像处理的能力。 新引擎的亮点在于其引入了图像处理元数据、KVCache 优化及图像缓存功能。

谷歌Gemma AI模型下载量突破1.5亿,引多模态功能热议
近日,谷歌推出的 Gemma 人工智能模型集下载量已突破1.5亿次,展示出其在 AI 领域的强大吸引力。 Gemma 的多模态功能和支持超过100种语言,使其在众多竞争对手中脱颖而出,吸引了全球开发者的关注。 Gemma 的成功不仅体现在下载量上,其基于 Gemma 模型衍生出的版本也已超过7万个。

仅20B参数!字节推出Seed1.5-VL多模态模型,实现38项SOTA
在上海举办的火山引擎 FORCE LINK AI 创新巡展上,字节跳动正式发布了最新的视觉 - 语言多模态模型 ——Seed1.5-VL。 该模型凭借其出色的通用多模态理解和推理能力,成为此次活动的焦点,吸引了众多业界专家和开发者的关注。 Seed1.5-VL 的显著特点是其增强的多模态理解与推理能力。

字节跳动发布新一代多模态大模型,挑战谷歌 Gemini 2.5 Pro
在人工智能领域竞争日益激烈的今天,字节跳动的 Seed 团队于5月13日正式发布了其最新的多模态大模型 Seed1.5-VL,旨在为智能体技术的进步铺平道路。 该模型经过超过3万亿 tokens 的多模态数据预训练,不仅具备强大的通用多模态理解和推理能力,还显著降低了推理成本。 与谷歌近期推出的 Gemini2.5Pro 相比,Seed1.5-VL 在性能上表现不相上下。

腾讯混元携手科研机构推出首个多模态统一CoT奖励模型并开源
近日,腾讯混元在与上海 AI Lab、复旦大学及上海创智学院的合作下,正式推出了全新研究成果 —— 统一多模态奖励模型(Unified Reward-Think),并宣布全面开源。 这一创新模型不仅具备了强大的长链推理能力,还首次实现了在视觉任务中 “思考” 的能力,使得奖励模型能够更准确地评估复杂的视觉生成与理解任务。 统一多模态奖励模型的推出,标志着奖励模型在各类视觉任务中的应用达到了新的高度。

阿里MNN神更新!移动端开源多模态AI支持Qwen-2.5,文本图像语音全搞定!
阿里巴巴开源项目MNN(Mobile Neural Network)发布了其移动端多模态大模型应用MnnLlmApp的最新版本,新增对Qwen-2.5-Omni-3B和7B模型的支持。 这款完全开源、运行于移动端本地的大模型应用,支持文本到文本、图像到文本、音频到文本和文本到图像生成等多种模态任务,以其高效性能和低资源占用引发开发者广泛关注。 AIbase观察到,MNN的此次更新进一步推动了多模态AI在移动端的普及。
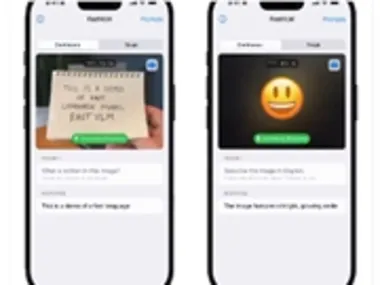
苹果发布FastVLM模型,可在iPhone上运行的极速视觉语言模型
苹果正式发布FastVLM,一款专为高分辨率图像处理优化的视觉语言模型(VLM),以其在iPhone等移动设备上的高效运行能力和卓越性能引发行业热议。 FastVLM通过创新的FastViTHD视觉编码器,实现了高达85倍的编码速度提升,为实时多模态AI应用铺平了道路。 技术核心:FastViTHD编码器与高效设计FastVLM的核心在于其全新设计的FastViTHD混合视觉编码器,针对高分辨率图像处理进行了深度优化。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉