多模态
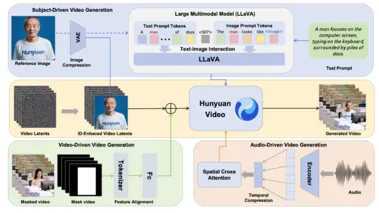
高一致性、强控制力,腾讯发布多模态视频生成利器 HunyuanCustom
腾讯近日正式开源其全新多模态定制视频生成框架——HunyuanCustom,标志着AI视频创作进入更高自由度与精准控制的全新阶段。 该框架基于腾讯自研的 HunyuanVideo 打造,主打**“主体一致性”与“多模态灵活输入”**,致力于实现视频内容与输入素材高度匹配的个性化生成。 HunyuanCustom 的核心优势在于其强大的多模态输入能力:支持用户通过文本描述、单图或多图图像、参考音频甚至已有的视频片段作为输入,系统可综合这些信息生成定制化视频。

商汤科技迈向多模态大模型的新纪元
在过去的两年里,人工智能领域的关注点逐渐转向了大模型的技术发展,而商汤科技作为一家成立不到十年的公司,凭借其在计算机视觉领域的技术积累,正迅速转型,迎接这一浪潮。 尽管在2023年之前,商汤主要聚焦于视觉模型,但随着 DeepSeek R1的发布,市场的重心开始向自然语言处理和大规模参数模型倾斜,商汤的策略也随之调整。 商汤于4月10日推出的全新6000亿参数多模态大模型 “日日新 Sense Nova V6”,展现了强大的综合能力,与国际领先的 GPT-4.5和 Gemini2.0Pro 不相上下。

国内大模型人才大战打响!大厂各出奇招,薪资不设上限、CTO亲自参与指导、无需实习经验
眼花缭乱了。 为争夺AI人才,大厂们齐齐放大招! 各种天才、顶尖人才计划简直看不过来。

一年狂发22个模型!阶跃星辰CEO姜大昕:AGI的秘密武器不是算力,而是让AI学会“自己教自己”!
在近期的媒体沟通会上,阶跃星辰的创始人兼 CEO 姜大昕分享了公司在多模态人工智能领域的最新进展以及未来的发展规划。 阶跃星辰成立于2023年,致力于开发通用人工智能(AGI),目前已发布22款自研模型,其中16款为多模态模型,这一成就使其在行业内被称为 “多模态卷王”。 姜大昕表示,公司将在未来几个月内推出一款新型推理模型 Step R1,并计划发布更先进的 Step 图片编辑模型。

消息称通义视觉负责人薄列峰离职 或加入某大厂新组建多模态团队
据多方信源透露,阿里巴巴通义实验室应用视觉团队负责人薄列峰(职级P10)已于2024年4月30日正式离职,并低调加盟某头部互联网公司,出任新设立的多模态模型部副总经理一职。 尽管该互联网公司具体名称尚未公开,坊间普遍猜测其去向可能是字节跳动或腾讯,但目前相关公司及本人均未作出回应,尚无法证实具体归属。 图源备注:图片由AI生成,图片授权服务商Midjourney此次人事变动引发业界关注的另一焦点在于“竞业限制”。

Gemini 2.5 Pro再更新!编程能力屠榜!一句话、一张草图变应用
出品 | 51CTO技术栈(微信号:blog51cto)AI 编码模型的新王者登基了! 今天,Google 旗下的 DeepMind AI 研究部门正式发布了 Gemini 2.5 Pro “I/O” 版,这是今年 3 月推出的 Gemini 2.5 Pro 多模态大语言模型(LLM)的更新版本。 DeepMind CEO Demis Hassabis 在 X 上表示:“这是我们迄今为止打造的最佳编码模型!

从看见到理解,多模态大模型如何重塑行为检测
在人工智能技术快速迭代的今天,行为检测作为计算机视觉领域的重要分支,正迎来一场由多模态大模型引领的技术革命。 作为曾在CV算法公司工作的从业者,我深刻体会到传统计算机视觉方法在实际落地中的诸多痛点。 过去几年,许多行为检测、烟火检测等应用,往往因为高昂的训练成本和难以接受的误报率而被甲方叫停。

通义实验室又一位大佬出走!传应用视觉团队负责人薄列峰已离职,将任职另一大厂多模态模型负责人!
出品 | 51CTO技术栈(微信号:blog51cto)北京时间5月6日,据知情人士透露,阿里巴巴通义实验室应用视觉团队负责人薄列峰(title中不是阿里集团副总裁,所以职级应该为P10)已于4月30日低调离职。 有消息称他已经加入刚刚进行架构调整的某互联网大厂,担任多模态模型部副总经理,向公司副总裁汇报。 最早爆料该消息的公众号之一“互联网八卦小喇叭”发文表示:据可靠消息称:“薄老师于本月离职通义,即将进入某大厂担任多模态模型负责人”。

阿里开源多模态模型Qwen2.5-Omni:显存大幅降低暴降 50%
在开源大模型的竞争中,阿里巴巴推出了其最新的多模态模型 Qwen2.5-Omni-3B。 这款模型的显著特点是显存使用减少了50%,在同等处理能力下,更加适合普通消费者的 GPU 设备。 这一创新标志着阿里在多模态人工智能领域的进一步突破。

图像编辑开源新SOTA,来自多模态卷王阶跃!大模型行业正步入「多模态时间」
全球AI大模型智能涌现,现在正在进入“多模态时间”。 一方面,全球业内各式各样的技术进展,都围绕多模态如火如荼展开。 另一方面,AI应用和落地的需求中,多模态也是最重要的能力。

Encoder-free无编码器多模态大模型EVEv2模型架构、训练方法浅尝
基于视觉编码器的MLLM的基本构成:MLLM通常由预训练的模态编码器、预训练的LLM和一个连接它们的模态接口三个模块组成。 模态编码器(如:CLIP-ViT视觉编码器、Whisper音频编码器等)将原始信息(如图像或音频)压缩成更紧凑的表示。 预训练的LLM则负责理解和推理处理过的信号。

机械臂+大模型+多模态:打造人机协作具身智能体
在人工智能快速发展的浪潮中,多模态大模型已成为技术前沿,使AI能够同时理解文本、图像、音频等多种信息。 这一突破为具身智能体开辟了新天地。 最近我在github中就找到了一个这样好玩的项目vlm_arm,其将机械臂与多模态大模型结合,打造一个能听人话、看图像、执行精准操作的人机协作智能体系统。

MinerU部署实践:从零开始搭建你的专属PDF解析服务
在多模态RAG(Retrieval-Augmented Generation)系统中,PDF文件的高效、安全解析与处理是实现高质量知识检索和生成的关键环节。 PDF文件通常包含丰富的文本、图像和表格信息,这些多模态数据的有效提取和整合对于提升RAG系统的性能至关重要。 然而,传统的PDF解析工具往往存在解析精度不足、无法处理复杂格式(如图像和表格)等问题,尤其是在涉及私密文档时,数据安全和隐私保护也是一大挑战。

万字拆解!最新多模态 RAG 技术全景解析!
来自华为云的最新多模态RAG综述,非常全面,对多模态RAG感兴趣的朋友强烈推荐! 复制1、引言传统的RAG系统主要依赖于文本数据,通过检索与查询语义相似的相关文档片段,并将其与查询结合,形成增强的输入,供LLMs生成回答。 这种方法使得LLMs能够在推理阶段动态整合最新信息,从而提高回答的准确性和可靠性。

视觉自回归生成理解编辑大一统!北大团队多模态新突破,训练数据代码全面开源
最近Google的Gemini Flash和OpenAI的GPT-4o等先进模型又一次推动了AI浪潮。 这些模型通过整合文本、图像、音频等多种数据形式,实现了更为自然和高效的生成和交互。 北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。

地表最强,全面第一!可灵2.0多模态编辑震撼全场!开辟视频模型的“新语言”,Prompt的门槛被砍没了!
出品 | 51CTO技术栈(微信号:blog51cto)今天,可灵全系正式进入2.0时代了! 先来看看2.0动态质量、语义响应、画面美学等维度做了升级,直接看视频是最直观的: 要知道,可灵1.6表现已经相当能打,做到了文生图行业第一,文生视频行业第二的水平。 图片根据发布会介绍,可灵AI全球用户规模突破2200万,过去的10个月里,其月活用户量增长25倍,累计生成超过1.68亿个视频及3.44亿张图片。

MiniMax MCP Server 上线 文本输入即可调用
今日,MiniMax稀宇科技宣布其MiniMax MCP Server正式上线。 这一创新平台为用户带来了一站式的多模态解决方案,只需简单文本输入,即可调用视频生成、图像生成、语音生成和声音克隆等多项前沿能力,极大地拓展了人工智能在创意内容生成领域的应用边界。 平台亮点强大的多模态功能:MiniMax MCP Server支持多种模态的生成能力,包括但不限于视频、图像、语音以及声音克隆。

阿里全模态Qwen2.5-Omni技术报告万字解读!
Qwen 团队最近发布了一款统一多模态大模型 Qwen2.5-Omni,开放了 7B 版本的权重。 能够同时处理文本、图像、音频和视频输入,并以流式方式生成文本和语音响应。 下面来详细看下:开源地址:论文地址:: 地址: Face:::官方体验:::在日常生活中,人类能够同时感知视觉和听觉信息,并通过大脑处理这些信息后,以书写、说话或使用工具等方式进行反馈,从而与世界上的各种生物进行信息交流并展现智能。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉