多模态

谷歌DeepMind计划整合Gemini与Veo,打造智能全能助手
在人工智能领域不断创新的谷歌,近日宣布了一项激动人心的计划。 谷歌 DeepMind 的首席执行官 Demis Hassabis 在播客节目 Possible 中透露,公司将把其 Gemini AI 模型与 Veo 视频生成模型进行整合。 这一举措旨在提升 Gemini 对物理世界的理解能力,助力开发出一个真正能够在现实生活中为用户提供帮助的通用数字助手。

模态编码器 | CLIP改进之SigLIP,采用sigmoid损失的图文预训练
DeepMind对CLIP改进的一篇工作--SigLIP,发表在2023CVPR。 简单看下研究动机:传统的对比学习方法如CLIP等依赖于 softmax 归一化,这需要一个全局视角来计算成对相似度,从而限制了批处理大小的扩展能力,并且在小批处理大小下表现不佳。 因此本文提出了一个简单的成对 Sigmoid 损失函数用于语言-图像预训练(SigLIP)。

模态编码器|CLIP详细解读
下面来详细了解一下多模态大模型模态编码器部分。 今天首先来看下CLIP,OpenAI发表在2021年ICML上的一篇工作。 项目地址::在自然语言处理(NLP)领域,通过大规模的文本数据预训练模型(如GPT-3)已经取得了显著的成果,但在计算机视觉领域,预训练模型仍然依赖于人工标注的图像数据集,严重影响了其在未见类别上的泛化性和可用性(需要用额外的有标注数据)。

多模态模型结构与训练总结
01、模型结构一般的多模态模型架构包含5个部分,分别是:模态编码器、输入映射器、大模型骨干、输出映射器以及模态生成器。 模态编码器(Modality Encoder, ME)将多种模态输入编码成特征表示,公式如下X表示模态,表示各种预训练好的编码器。 目前模态主要分为:视觉模态、语音模态、3D点云模态,其中视觉模态主要包括图像和视频,对于视频,视频通常被均匀采样成5帧图像,然后进行与图像相同的预处理。

多模态AI核心技术:CLIP与SigLIP技术原理与应用进展
近年来,人工智能领域在多模态表示学习方面取得了显著进展,这类模型通过统一框架理解并整合不同数据类型间的语义信息,特别是图像与文本之间的关联性。 在此领域具有里程碑意义的模型包括OpenAI提出的CLIP(Contrastive Language-Image Pre-training,对比语言-图像预训练)和Google研发的SigLIP(Sigmoid Loss for Language-Image Pre-training,用于语言-图像预训练的Sigmoid损失)。 这些模型重新定义了计算机视觉与自然语言处理的交互范式,实现了从图像分类到零样本学习等多种高级应用能力。

AI “看图说话” 更懂细节!腾讯开源多模态理解技术HaploVL
3月27日,腾讯开源团队宣布推出了一项创新的多模态理解技术——HaploVL。 这一技术旨在通过单个Transformer架构实现高效的多模态融合,显著提升AI在视觉和语言交互中的表现,特别是在细粒度视觉理解任务上。 在人工智能领域,多模态大模型(LMMs)近年来迅速崛起,它们能够实现复杂的视觉-语言对话和交互。

阿里通义千问开源发布新一代端到端多模态模型Qwen2.5-Omni
3月27日,阿里云通义千问Qwen团队宣布推出Qwen模型家族中的新一代端到端多模态旗舰模型——Qwen2.5-Omni。 这一全新模型专为全方位多模态感知而设计,能够无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音合成输出。 Qwen2.5-Omni采用了创新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本、图像、音频、视频的跨模态理解,并以流式方式生成文本和自然语音响应。

一文看懂多模态思维链
多模态思维链(MCoT)系统综述来了! 不仅阐释了与该领域相关的基本概念和定义,还包括详细的分类法、对不同应用中现有方法的分析、对当前挑战的洞察以及促进多模态推理发展的未来研究方向。 图片当下,传统思维链(CoT)已经让AI在文字推理上变得更聪明,比如一步步推导数学题的答案。
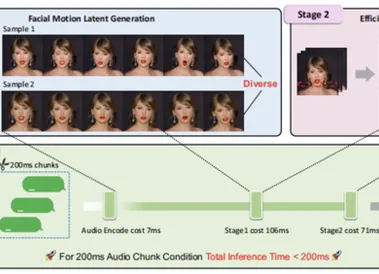
Soul App实时人像视频生成研究成果获国际学术顶会CVPR2025录用
近期,IEEE国际计算机视觉与模式识别会议( Conference on Computer Vision and Pattern Recognition)CVPR 2025公布论文录用结果,社交平台Soul App技术论文《Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation》(《基于自回归动作生成的实时流式音频驱动人像动画系统》)被接收。 Soul App团队在论文中提出了一个新的面向实时音频驱动人像动画(即Talking Head)的自回归框架,解决了视频画面生成耗时长的行业挑战外,还实现了说话时头部生成以及人体各部位运动的自然性和逼真性。 此次论文的入选,也证明了Soul App在推动多模态能力构建特别是视觉层面能力突破上取得了阶段性成果。

智源开源多模态向量模型BGE-VL,助力多模态检索!
智源研究院开源了多模态向量模型BGE-VL,助力主要多模态检索任务达到SOTA。 论文地址:: : :现有的多模态检索模型大多基于预训练的视觉-语言模型,这些模型主要通过文本-图像匹配任务进行预训练,对于其他常见的多模态任务(如组合图像检索和多模态文档检索)表现不足。 为了增强模型的多任务能力,研究者们开始采用指令微调的方法,但高质量的指令微调数据稀缺且难以大规模获取。

谷歌大招网友玩疯了!Gemini原生图像输出抢先推出,OpenAI一年领先优势归零
谷歌推出Gemini原生图像生成,测试版瞬间引爆网络。 如果你迟到了,但没有好的借口,甚至还没有出家门——只需要一张自拍,然后让AI把你P到地铁故障现场。 图片也可以凭空生成一个人物形象,把它放到原神游戏画面中(不用上传游戏截图),让角色往前走两步,再把视角往左移,走近一个建筑,开始爬墙。

具身智能新时代!VLA迎来最强基础模型Magma:UI导航、机器人操作全能
现有的大语言模型、图像生成模型等都只是在某几个模态数据上进行操作,无法像人类一样与物理世界产生交互。 视觉-语言-行动(VLA,Vision-Language-Action)模型是可以感知视觉刺激、语言输入以及其他与环境相关数据的自主智能体,能够在物理和数字环境中生成有意义的「具身行动」(embodied actions)以完成特定任务。 图片由于二维数字世界和三维物理世界之间存在差异,现有的VLA模型通常对任务进行简化,导致多模态理解能力偏弱,在跨任务和跨领域的泛化能力上不够通用。

多模态检索新突破!智源开源多模态向量模型BGE-VL
2025年3月6日,北京智源人工智能研究院宣布开源多模态向量模型BGE-VL,这一成果标志着多模态检索领域的新突破。 BGE-VL模型在图文检索、组合图像检索等多模态检索任务中取得了最佳效果,显著提升了多模态检索的性能。 BGE-VL的开发基于大规模合成数据集MegaPairs,该数据集通过结合多模态表征模型、多模态大模型和大语言模型,从海量图文语料库中高效挖掘多模态三元组数据。

华科字节推出 Liquid:重新定义多模态模型的生成与理解
近年来,大语言模型(LLM)在人工智能领域取得了显著进展,尤其是在多模态融合方面。 华中科技大学、字节跳动与香港大学的联合团队最近提出了一种新型的多模态生成框架 ——Liquid,旨在解决当前主流多模态模型在视觉处理上的局限性。 传统的多模态大模型依赖复杂的外部视觉模块,这不仅增加了系统的复杂性,还限制了其扩展性。

微软发布 Phi-4 多模态与迷你模型,语音视觉文本处理再升级
近日,微软进一步扩展了 Phi-4家族,推出了两款新模型:Phi-4多模态(Phi-4-multimodal)和 Phi-4迷你(Phi-4-mini),这两款模型的亮相,无疑将为各类 AI 应用提供更加强大的处理能力。 Phi-4多模态模型是微软首款集成语音、视觉和文本处理的统一架构模型,拥有5600万参数。 这款模型在多项基准测试中表现优异,超越了目前市场上的许多竞争对手,例如谷歌的 Gemini2.0系列。

微软 Phi-4 多模态及迷你模型上线,语音视觉文本全能
微软推出Phi-4多模态和Phi-4迷你模型,多模态模型集成语音、视觉和文本处理,表现卓越;迷你模型专注于文本任务,性能优异。两款模型已在多个平台上线,为AI应用带来强大处理能力。#微软#AI技术#多模态模型
商汤小浣熊家族全面升级:多模态融合 10秒钟即可复刻网页
2月25日,商汤科技在2025全球开发者先锋大会上宣布其AI生产力工具——商汤小浣熊家族全面升级,进一步强化多模态能力,推动AI应用加速落地,向AI Agent演进。 此次升级不仅提升了工具的性能,还让AI回归其最朴素的使命——成为强有力的生产力工具。 商汤小浣熊家族的升级涵盖了多个方面。

一文读懂多模态 embeddings
传统上,AI研究被划分为不同的领域:自然语言处理(NLP)、计算机视觉(CV)、机器人学、人机交互(HCI)等。 然而,无数实际任务需要整合这些不同的研究领域,例如自动驾驶汽车(CV 机器人学)、AI代理(NLP CV HCI)、个性化学习(NLP HCI)等。 尽管这些领域旨在解决不同的问题并处理不同的数据类型,但它们都共享一个基本过程。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉