眼花缭乱了。为争夺AI人才,大厂们齐齐放大招!
各种天才、顶尖人才计划简直看不过来。
 图片
图片
每个都扒开粗略一看,满满都是薪资不设上限、CTO亲自参与指导,无需实习经验……
 图片
图片
老天奶,都2025年了抢人咋还这么疯。
而与抢人同步进行的是,他们还到处挖大牛,以大牛的明星效应来吸引大量业内顶级人才加盟——
字节挖来谷歌DeepMind研究副总裁吴永辉、阿里招揽全球顶尖AI科学家许主洪。前几天,阿里薄列峰离职被曝加盟某大厂……
好好好,激烈程度不亚于商战。难怪马斯克也曾经发出感慨:AI的人才争夺战是我见过最疯狂的。
顶尖AI人才成香饽饽
通过仔细梳理本轮的抢人大战,我们发现各家大厂在策略上其实有一些共性和差异。
最明显的,当属大厂们所争夺的对象都是“顶尖人才”、“天才少年”等凤毛麟角的人物。
换句话说,招人要求一整个拉满。
作为想要应聘的学生,要么在顶会期刊上发表过有影响力的论文,要么就是竞赛达人,主打一个优秀本秀,甚至字节的Top Seed计划仅面向博士生。
不过从对招聘要求的具体描述来看,这里我们还是能明显看到大厂分为两派:
一派以京东/百度/阿里为代表,想要招的人很具体,直接贴出“超级学霸”、“工程大牛”等标签;
另一派则以字节/腾讯为代表,描述主打抽象,看重的是技术信仰、好奇心一类,更像是在走情怀路线。
其次从招聘方向来看,目前主要集中在大模型和多模态领域。
背后也透露出两点,一是尽管开源力量已经迅速崛起,但大厂们始终作为AI发展主力军在支撑大模型的更新迭代。
尤其是AI发展至今,得益于拥有更多算力、资金的大厂在大模型上持续投入,其他中小企业或创业团队才能以更低的门槛投身AI应用。
至于多模态,这更是如今一个显而易见的大热门。随着AI进入应用元年,人们对多模态的需求逐渐成为刚需,不过相关技术并未成熟,以致于包括大厂在内,市面上的多模态AI产品仍比较少见。
当然,通过各家对招聘方向的描述,我们还是能看到一个招人特色——核心聚焦在自己的场景。
 图片
图片
以腾讯/阿里/华为为例,这几家明显更强调底层算法和基础设施;而京东/字节等,则与自己的核心业务联系更为紧密,前者特意提到了“搜索推荐”方向,后者更是反复强调了多模型方向。
值得一提的是,字节是几家大厂中对研究方向描述最详细的公司,背后也能看出它对应用的追求。
与此同时,从大厂开出的“筹码”来看,除了默认的顶尖薪酬外,各自也都有一些招牌特色。
比如阿里在招实习生时,特意增加了“反选环节”,让实习生能够主动选择自己感兴趣的研究领域和团队。
又或者字节打出的“不限专业”口号,整体来看招人的氛围比较chill。
其实不止顶尖人才,还能看到今年的一个趋势:AI人才普遍性扩招。
咱们就按最近的4月说。
百度官宣未来三年,将开放21000个实习岗位给优秀校园人才。
腾讯这边发布史上最大招聘计划:未来三年,计划新增28000名员工,包括大模型、研发、算法、市场、策划、运营、销售、美术等多个岗位职能。
华为的2025年“勇敢新世界”计划,拟招聘优秀应届毕业生1万余人,相较于2024年预计实现两位数增幅,岗位覆盖AI工程师、软件开发工程师、硬件技术工程师、人工智能算法工程师等60余类岗位。
……
当然这种人才争夺战,其实从年初就开始进行了。
此前就有爆出某头部大模型公司为招募顶尖算法工程师和资深研究员,开出月薪13万至26万、年薪最高300万的「天价」。而备受瞩目的DeepSeek爆火之后第一时间也被爆出百万年薪招人,一度登上了热搜。
随着大模型应用落地进入深水区,为何大厂抢人大战不仅没有减缓甚至持续白热化呢?
为什么会出现这样的情况?
在众多现象之中抽丝剥茧似乎也找到了些内在原因。
首先,数据和人才是企业竞争的核心资源,对于大厂来说,不缺数据不缺场景,缺的是滔滔不绝的人才。
大厂通过高薪吸引顶尖人才,实现在算法优化、模型迭代上的快速突破。
阿里云CTO周靖人曾表示,在这个时代里面,其实需要更多的人、更多的优秀的人才在各个领域进行探索、突破。
而大厂通过“抢人”迅速补齐技术短板,尤其随着大模型朝着更多垂直领域落地,更多工程方面的难题更需要顶尖人才来携手解决。
不过AI人才供需失衡似乎一直存在,甚至于这些大厂头部的人才紧缺可能更为显著。
在翰德发布的《2025人才趋势报告》中显示,目前国内AI人才的供需比仅为0.5。什么概念呢?相当于每个人工智能岗位只能匹配到一个合适的候选人。
不过这样的争夺加剧,一部分原因还在于DeepSeek引发的「行业重估」。
与过去的大模型混战不同的是,大厂们逐步找到自己的主攻场景。明显感知到的一个现象就是,大家重新加码C端,但各有侧重。
例如腾讯元宝选择多管齐下,在微信、QQ这种国民级产品中部署,一度拿下C端应用下载量榜首。阿里这边AI to C业务势头更为明显,夸克、通义App增长势头很猛,还有与天猫精灵的联合,AI硬件还有更多潜在应用场景。
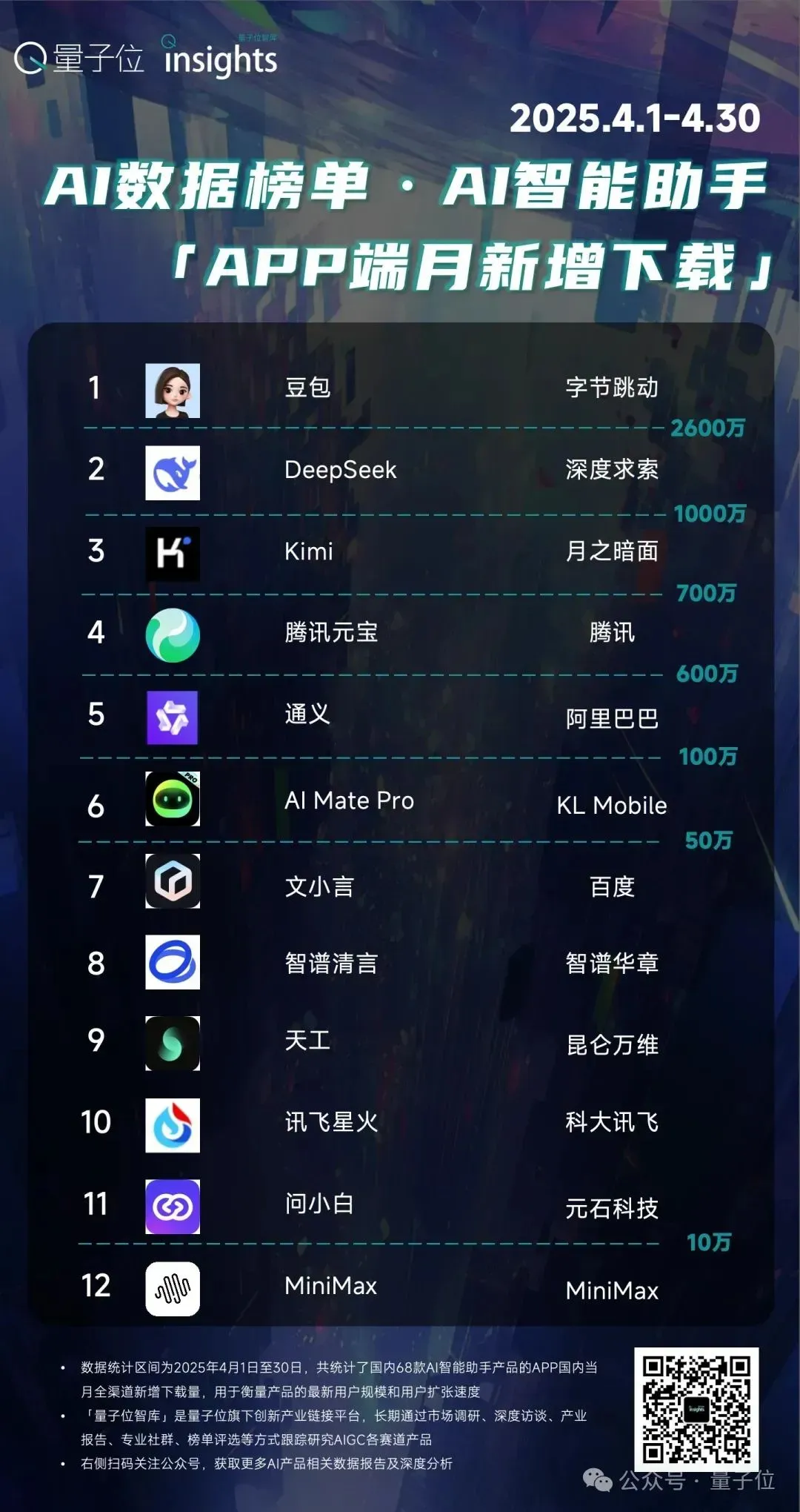
字节则继续加持豆包智能助手,基于原有的内容生态积累,牢牢捍卫住他们榜首之位,截至4月底,豆包在25年的新增下载已近亿,累计用户规模近3亿。
 图片
图片
百度则是继续拉动他们文库、云盘等原有业务,AI加持下他们呈现出强增长的态势;小米侧重于推动大模型在各种终端上部署和落地;华为聚焦在底层突破,包括算力基建、软硬件协同等。
可以看到,大部分选择策略,都与他们业务场景强相关。而只有更快地吸纳人才,才能迅速将业务升维,占领技术高地。
不过,同样疯狂的不只国内,海外硅谷也同样火热。毕竟连马斯克都那样说了:疯狂,很疯狂。
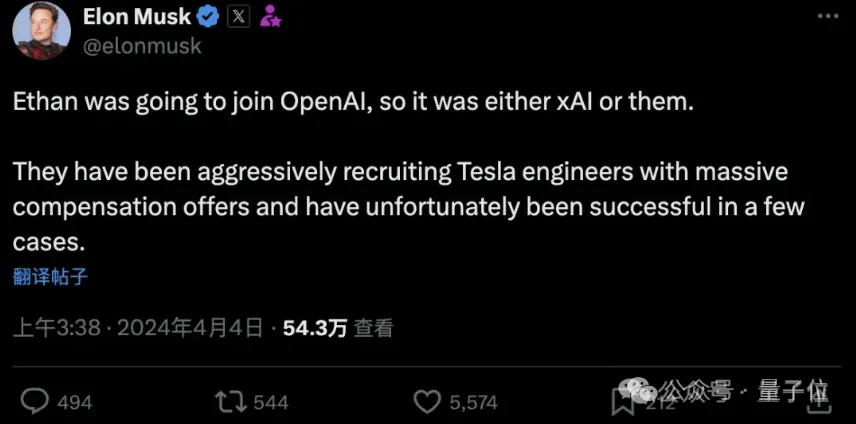
当时的起因是因为特斯拉视觉科学家Ethan Knight离职,加入到了马斯克的xAI公司。结果没成想过程十分曲折,因为他差点就要去OpenAI的,但是被马斯克力挽狂澜:
OpenAI一直在积极招募特斯拉的工程师,并提供巨额薪酬,不幸的是,在少数情况下取得了成功。
 图片
图片
而正如马斯克所说,这些科技巨头们采取的措施也别无二致:有钱、有钱,还是有钱。
正如业内人士所观察到的那样,经常看到轻轻松松超过100万美元(约720万人民币)的薪酬方案。
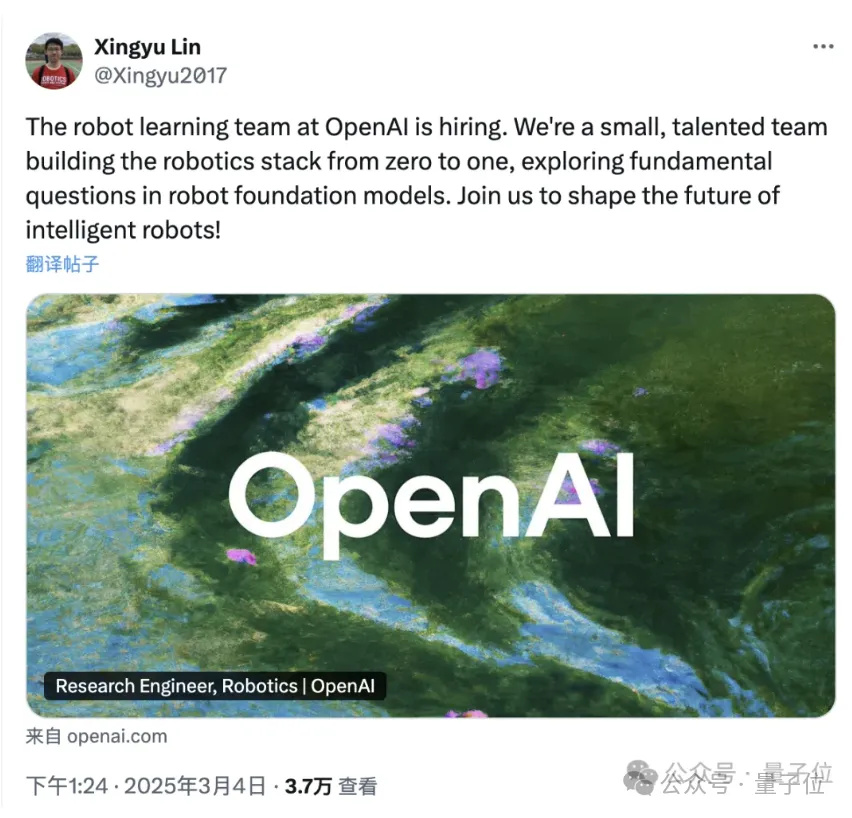
更具体一点,今年三月,OpenAI要扩增一个机器人基础模型团队,薪资可以开到最高385万年薪。
 图片
图片
如果在这基础上还有点啥,那就是主打一个真诚,老板亲自打电话发邮件的那种。奥特曼、扎克伯格、马斯克、谢尔盖·布林等通通都被曝出过有这段经历。
毕竟技术竞争,终究是人才竞争。
抢人大战已经打响,抢人大战还将持续,有身处其中的朋友能说说体验如何吗?
参考链接:
[1]https://mp.weixin.qq.com/s/6B0_bZ9EJYFwrvpb1r_hRw
[2]https://mp.weixin.qq.com/s/ATUz0UW4haIt5A8E8FO7qQ
[3]https://mp.weixin.qq.com/s/z0rXCrO0Bzuz22oLSjskEg
[4]https://finance.sina.com.cn/roll/2025-04-07/doc-ineskazk1185808.shtml
[5]https://join.qq.com/qingyun.html


