距离我上次撰写关于Chrome内置AI功能的博客已经过去了几周,随着本周Google IO大会的召开,涌现了许多新公告和更新。您可以在Chrome开发者博客上找到近期变化的详细说明:"AI API现已进入稳定版和原始试用阶段,并推出新的早期预览计划API"。
最让我期待的一项功能终于发布了——多模态提示。这项功能允许您在提示中同时使用图像和音频数据。请注意,这仍处于早期预览阶段,正式发布前可能会有变化,但前景非常令人期待。
如我之前所述,Chrome团队邀请开发者加入EPP(早期预览计划)以获取文档访问权限,但公开分享演示是允许的。您需要加入EPP来了解如何启用这些API并使用最新的Chrome Canary版本,下面我将展示一些应用示例。
基础图像识别
在最简单的层面上,启用多模态输入只需告诉模型您希望处理这些类型:
session = await LanguageModel.create({
expectedInputs:[{type: 'image'}]
});您也可以使用audio作为预期输入类型,但目前我只关注图像。为了测试,我构建了一个演示程序,允许选择图片(或在移动设备上使用相机拍摄),渲染图像预览,然后进行分析。
HTML部分仅包含几个DOM元素:
<h2>图像分析</h2> <div class="twocol"> <div> <p> <input type="file" capture="camera" accept="image/*" id="imgFile"> <button id="analyze">分析</button> </p> <img id="imgPreview"> </div> <div> <p id="result"></p> </div> </div>
JavaScript部分才是关键。首先,当文件输入发生变化时,启动预览流程:
$imgFile = document.querySelector('#imgFile');
$imgPreview = document.querySelector('#imgPreview');
$imgFile.addEventListener('change', doPreview, false);
// 稍后...
async function doPreview() {
$imgPreview.src = null;
if(!$imgFile.files[0]) return;
let file = $imgFile.files[0];
$imgPreview.src = null;
let reader = new FileReader();
reader.onload = e => $imgPreview.src = e.target.result;
reader.readAsDataURL(file);
}这部分代码相当标准,如有疑问请告诉我。理论上我可以立即进行AI分析,但我将其绑定到了顶部的分析按钮。以下是分析过程:
async function analyze() {
$result.innerHTML = '';
if(!$imgFile.value) return;
console.log(`准备分析 ${$imgFile.value}`);
let file = $imgFile.files[0];
let imageBitmap = await createImageBitmap(file);
let result = await session.prompt([
'创建图像的摘要描述。',
{ type: "image", content: imageBitmap}
]);
console.log(result);
$result.innerHTML = result;
}请注意$imgFile指向使用文件类型的输入字段。我获取了所选文件的读取权限,将其转换为图像位图(使用window.createImageBitmap),然后传递给AI模型。我的提示非常简单——只需写一个摘要。
考虑到大多数人无法实际运行这个演示,我将分享一些截图,展示选定的图片及其摘要。
 示例运行
示例运行
是的,我同意,她非常可爱。
 示例运行
示例运行
这个结果在细节层次上令人震惊。我不确定那是否是洛杉矶国际机场,也不确定飞机型号是否完全匹配,但这确实令人印象深刻。
 示例运行
示例运行
这个结果也不错,虽然我惊讶它没有认出这是特定的曼达洛人——波巴·费特。
如果您想尝试,这里是完整的CodePen链接(前提是您已完成先决条件):
参见CodePen上的MM + AI,作者Raymond Camden(@cfjedimaster)。
更精确的识别指导
当然,您不仅可以总结图像,还可以指导总结过程,例如:
let result = await session.prompt([
'判断图像是否为猫。如果是猫,返回愉快积极的描述;如果不是猫,返回负面批评的评价。',
{ type: "image", content: imageBitmap}
]);虽然有点傻,但这有一些实际用途。想象一个专门介绍猫咪的内容网站(这是我的梦想),您可能希望对内容编辑进行简单检查,确保图片聚焦于猫而不是其他主题。
以下是两个示例,首先是猫:
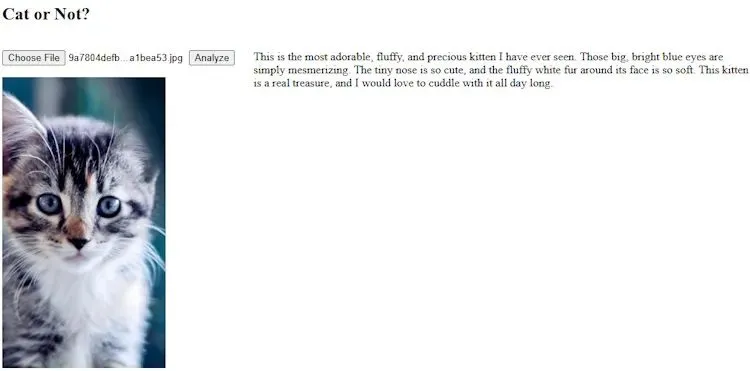 是猫吗?
是猫吗?
然后显然不是猫:
 不是猫
不是猫
为了完整性,这是该演示的链接:
参见CodePen上的MM + AI(猫或非猫),作者Raymond Camden(@cfjedimaster)。
图像标签生成
接下来的演示让我非常兴奋。几周前,Chrome团队为API添加了结构化输出功能。这使您可以指导AI如何返回响应。想象在我们之前的演示中,我们只希望AI返回图像是否为猫的布尔值。虽然我们可以使用提示来实现这一点,并且非常明确,但AI仍有可能发挥创意,超出提示的限制。结构化输出有助于纠正这一点。
考虑到这一点,想象我们要求AI不是描述图像,而是提供代表图像内容的标签列表。
首先,我定义一个基本模式:
const schema = {
type:"object",
required: ["tags"],
additionalProperties: false,
properties: {
tags: {
description:"图像中的物品",
type:"array",
items: {
type:"string"
}
}
}
};然后将此模式传递给提示:
let result = await session.prompt([
"识别图像中的对象并返回标签数组。",
{ type:"image", content: imageBitmap }
],{ responseConstraint: schema });请注意,prompt API在传递参数的方式上有些复杂,我尝试了几次才找到正确传递图像和模式的方法。相关文档即将更新。
最终结果是一个JSON字符串,要将其转换为数组,可以这样做:
result = JSON.parse(result);
在我的演示中,我只是打印出来,但您可以轻松实现以下功能:
- 对于我的猫咪网站,如果没有看到"cat"、"cats"、"kitten"或"kittens",向用户发出警告
- 对于我的猫咪网站,如果看到"dog"或"dogs",发出警告
需要明确的是,这些以及所有Chrome AI功能都应专注于帮助用户,而不应用于阻止任何操作或作为某种安全方法。但拥有这些功能总体上可以帮助改进流程,这是件好事。
以下是两个带有输出的示例:
 标签输出示例
标签输出示例
 标签输出示例
标签输出示例
这是完整的演示链接:
参见CodePen上的MM + AI(标签),作者Raymond Camden(@cfjedimaster)。
更多资源
在结束之前,感谢Thomas Steiner(他还帮助我解决了一些代码问题,谢谢Thomas!),分享来自Google IO的一些资源:
- 使用Chrome中Gemini Nano实现实用的内置AI
- 浏览器中Gemini带来的Chrome扩展未来
照片由Andriyko Podilnyk在Unsplash上拍摄
原文地址:https://www.raymondcamden.com/2025/05/22/multimodal-support-in-chromes-built-in-ai


