3D

2D图像作中介,零训练实现3D场景生成SOTA:英伟达&康奈尔提出文本驱动新流程
本文第一作者顾泽琪是康奈尔大学计算机科学四年级博士生,导师为 Abe Davis 教授和 Noah Snavely 教授,研究方向专注于生成式 AI 与多模态大模型。 本项目为作者在英伟达实习期间完成的工作。 想象一下,你是一位游戏设计师,正在为一个奇幻 RPG 游戏搭建场景。

一个md文件收获超400 star,这份综述分四大范式全面解析了3D场景生成
在构建通用人工智能、世界模型、具身智能等关键技术的竞赛中,一个能力正变得愈发核心 —— 高质量的 3D 场景生成。 过去三年,该领域的研究呈指数级增长,每年论文数量几乎翻倍,反映出其在多模态理解、机器人、自动驾驶乃至虚拟现实系统中的关键地位。 注:图中 2025 年的数据截至 4 月底来自南洋理工大学 S-Lab 的研究者们全面调研了该领域最前沿的研究方法,发表了综述《3D Scene Generation: A Survey》,对 300 篇代表性论文进行了系统归纳,将现有方法划分为四大类:程序化方法、基于神经网络的 3D 表示生成、图像驱动生成,以及视频驱动生成。

影视级3D生成新王:Direct3D-S2全面开源!8块GPU超越闭源登顶HF
HuggingFace是全球最大的开源大模型社区,汇集了来自世界各地的上百个开源大模型。 其趋势榜(HuggingFace Trending)展示了各类开源大模型在全球开发者中的受欢迎程度,DeepSeek、Qwen等大模型就因曾登顶HuggingFace榜单而获得了全球开发者的关注与热议。 可以说,这是当前最具权威性的榜单之一。

推理时间减少70%!前馈3DGS「压缩神器」来了,浙大Monash联合出品
在增强现实(AR)和虚拟现实(VR)等前沿应用领域,新视角合成(Novel View Synthesis,NVS)正扮演着越来越关键的角色。 3D高斯泼溅(3D Gaussian Splatting,3DGS)凭借其革命性的实时渲染能力和卓越的视觉质量,迅速成为NVS领域备受关注的技术方案。 现有的前馈3D高斯泼溅(Feed-Forward 3D Gaussian Splatting,3DGS)模型,虽然在实时渲染和高效生成3D场景方面取得了显著进展,但仍存在一些关键缺陷。

ICLR2025 | MIT何恺明团队提出TetSphere:拉格朗日体积网格精准还原高质量3D形状!
一眼概览TetSphere Splatting提出了一种基于四面体球体(TetSpheres)的拉格朗日表示方法,可生成高质量3D网格,兼具高几何保真度和结构完整性,在多视图重建和图像/文本到3D生成任务中均表现出色。 核心问题当前主流3D建模方法(如基于点云或神经隐式表示)难以同时兼顾高质量网格结构与几何表达能力,尤其在处理复杂形状时,常出现非流形、退化三角面等问题。 论文关注的核心问题是:如何以结构合理、几何一致的方式重建高质量3D网格,同时保持高效计算和良好可扩展性。

谷歌Beam发布!2D视频秒变3D沉浸式体验,实时翻译+真实眼神交流
Google I/O大会上,Google正式推出了其革命性的3D视频通信平台——Google Beam。 这一平台以人工智能为核心,将传统的2D视频通话升级为身临其境的3D体验,旨在让远程沟通如同面对面般真实自然。 AIbase为您带来这一前沿科技的最新资讯,解析其技术亮点与未来潜力。

一图生万物?AI“神笔马良”3DTown,单张照片变3D城市,这波操作太秀了!
最近,一项黑科技直接颠覆了我们对3D 世界构建的认知!普林斯顿大学、哥伦比亚大学和一家叫 Cyberever AI 的公司,联手推出了一套名叫3DTown 的框架。 听名字就知道,它就是来帮你搞3D 城镇的!最骚的是什么?它能仅仅凭借一张俯视图,就能帮你生成一个逼真、连贯的3D 城镇场景! 而且,它还是个免训练(training-free)的框架,这意味着你不用费劲巴拉地去收集海量3D 数据来训练它,直接就能用!

腾讯大模型战略亮相 Turbo S 与 T1 模型全面升级
5月21日,腾讯宣布其混元大模型矩阵全面升级,标志着腾讯在人工智能领域的技术能力持续提升。 此次升级涵盖了多个方面,包括旗舰快思考模型混元TurboS、深度思考模型混元T1的升级,以及基于TurboS基座新推出的视觉深度推理模型T1-Vision和端到端语音通话模型混元Voice。 此外,腾讯还同步更新了混元图像2.0、混元3D v2.5及混元游戏视觉生成等一系列多模态模型。

UC伯克利5千美元造全开源人形机器人,网友:这作业抄定了
仅需5000美元就能实现人形机器人3D打印? UC伯克利这次又又又整新活了! 注意看,画面中这个正在认真写名字的小家伙,就是来自UC伯克利的最新作品——人形机器人Berkeley Humanoid Lite (BHL)。

参数量暴降,精度反升!哈工大宾大联手打造点云分析新SOTA
新架构选择用KAN做3D感知,点云分析有了新SOTA! 来自哈尔滨工业大学(深圳)和宾夕法尼亚大学的联合团队最近推出了一种基于Kolmogorov-Arnold Networks(KANs)的3D感知解决方案——PointKAN,在处理点云数据的下游任务上展现出巨大的潜力。 △PointKAN与同类产品的比较替代传统的MLP方案,PointKAN具有更强的学习复杂几何特征的能力。

新一代开源3D模型 Step1X-3D 亮相,AI行业新动向引关注
近日,科技领域迎来了一款全新的开源3D 大模型 —— 阶跃星辰 Step1X-3D。 该模型的发布,标志着 AI 技术的又一次重大进步,尤其是在3D 建模和推理能力方面。 该模型不仅开源,且针对开发者提供了多种实用的功能,极大地促进了创新和研究的可能性。

The Next Generation Open Source 3D Model Step1X-3D Debuts, AI Industry Trend Draws Attention
Recently, the technology sector welcomed a brand-new open-source 3D large model called "Step1X-3D." The release of this model marks another significant advancement in AI technology, particularly in 3D modeling and reasoning capabilities. Not only is this model open-source, but it also provides developers with various practical features, greatly promoting innovation and research possibilities.At the same time, Xiaomi is continuously expanding its presence in the AI field. It has recently applied for the "MiMo" trademark, which is intended to be used for inference large models.
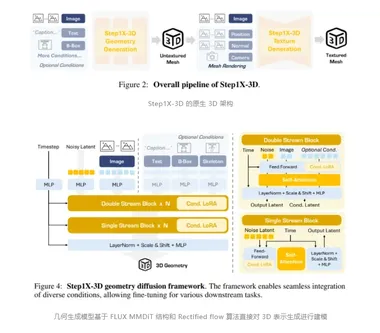
阶跃星辰开源 3D 大模型 Step1X-3D
阶跃星辰正式发布并开源了3D大模型Step1X-3D。 这一模型的推出,标志着阶跃星辰在多模态方向上的最新成果,继图像、视频、语音、音乐等模态后,进一步拓展了AI技术的应用边界。 Step1X-3D模型总参数量达4.8B,其中几何模块1.3B,纹理模块3.5B。

3D人脸黑科技!Pixel3DMM:单张RGB图像秒变3D人脸,姿势表情精准还原,几何精度碾压竞品15%!
慕尼黑工业大学和伦敦大学学院提出了一款经过微调的 DINO ViT模型 Pixel3DMM,用于逐像素表面法线和 UV 坐标预测。 从上到下,下图展示了 FFHQ 输入图像、估计的表面法线、根据预测的 UV 坐标估计的二维顶点,以及针对上述两个线索的 FLAME 拟合结果。 使用Pixel3DMM 进行野外追踪。
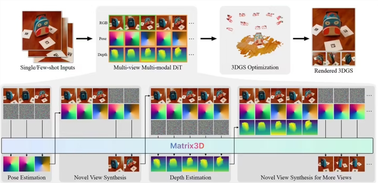
苹果推出革命性 AI 模型 Matrix3D:轻松将 3 张照片转化为 3D 场景
苹果机器学习团队与南京大学和香港科技大学合作,推出了一款名为 Matrix3D 的先进 AI 模型。 该模型的主要功能是从少量的2D 照片中重建真实的物体和场景,为用户提供高质量的3D 输出。 用户只需提供三张照片,Matrix3D 便能自动生成详细的3D 重建效果。

腾讯发布全新 AI 框架 PrimitiveAnything:颠覆 3D 形状生成方式!
在计算机视觉和图形学中,3D 形状的抽象是一个基础且关键的研究领域。 通过将复杂的3D 形状分解为简单的几何单位,研究者能够更好地理解人类视觉感知的机制。 然而,现有的3D 生成方法通常无法满足机器人操作或场景理解等任务对语义深度和可解释性的要求。

CVPR 2025 Highlight | 清华提出一键式视频扩散模型VideoScene,从视频到 3D 的桥梁,一步到位!
清华大学的研究团队首次提出了一种一步式视频扩散技术 VideoScene,专注于 3D 场景视频生成。 它利用了 3D-aware leap flow distillation 策略,通过跳跃式跨越冗余降噪步骤,极大地加速了推理过程,同时结合动态降噪策略,实现了对 3D 先验信息的充分利用,从而在保证高质量的同时大幅提升生成效率。 实验证明VideoScene可弥合从视频到 3D 的差距。

南洋理工 & 牛津 & 新加坡理工提出Amodal3R,可从遮挡 2D 图像重建完整 3D 资产,3D生成也卷起来了!
Amodal3R 是一种条件式 3D 生成模型,能够从部分可见的 2D 物体图像中推测并重建完整的 3D 形态和外观,显著提升遮挡场景下的 3D 重建质量。 给定图像中 部分可见的物体,Amodal3R 重建具有合理几何形状和合理外观的语义上有意义的 3D 资产。 相关链接论文:::即将开放...模型:: 的示例结果。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉