清华大学的研究团队首次提出了一种一步式视频扩散技术 VideoScene,专注于 3D 场景视频生成。它利用了 3D-aware leap flow distillation 策略,通过跳跃式跨越冗余降噪步骤,极大地加速了推理过程,同时结合动态降噪策略,实现了对 3D 先验信息的充分利用,从而在保证高质量的同时大幅提升生成效率。实验证明VideoScene可弥合从视频到 3D 的差距。


视频结果



相关链接
- 论文: https://arxiv.org/abs/2504.01956
- 项目: https://hanyang-21.github.io/VideoScene
- 代码: https://github.com/hanyang-21/VideoScene
论文介绍
 VideoScene:提取视频扩散模型,一步生成 3D 场景
VideoScene:提取视频扩散模型,一步生成 3D 场景
从稀疏视图中恢复 3D 场景是一项具有挑战性的任务,因为它存在固有的不适定问题。传统方法已经开发出专门的解决方案(例如,几何正则化或前馈确定性模型)来缓解该问题。然而,由于输入视图之间的最小重叠和视觉信息不足,它们仍然会导致性能下降。幸运的是,最近的视频生成模型有望解决这一挑战,因为它们能够生成具有合理 3D 结构的视频片段。在大型预训练视频扩散模型的支持下,一些先驱研究开始探索视频生成先验的潜力,并从稀疏视图创建 3D 场景。尽管取得了令人瞩目的改进,但它们受到推理时间慢和缺乏 3D 约束的限制,导致效率低下和重建伪影与现实世界的几何结构不符。在本文中,我们提出VideoScene来提炼视频扩散模型以一步生成 3D 场景,旨在构建一个高效的工具来弥合从视频到 3D 的差距。具体来说,我们设计了一种 3D 感知的跳跃流精炼策略,用于跳过耗时的冗余信息,并训练了一个动态去噪策略网络,以便在推理过程中自适应地确定最佳跳跃时间步长。大量实验表明,我们的 VideoScene 比以往的视频扩散模型实现了更快、更优异的 3D 场景生成结果,凸显了其作为未来视频到 3D 应用高效工具的潜力。
方法概述
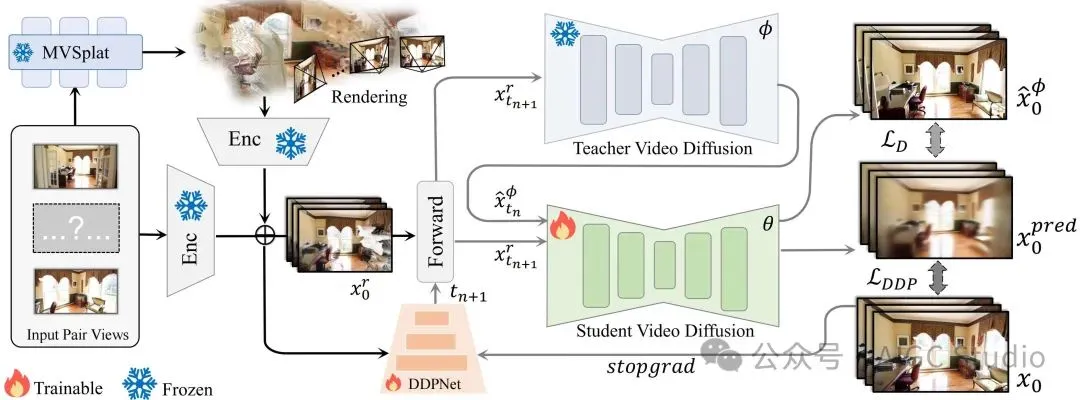 VideoScene 的流程。 给定输入对视图,我们首先使用快速前馈 3DGS 模型(即MVSplat)生成粗略的 3D 表示,从而实现精确的摄像机轨迹控制渲染。编码后的渲染潜在向量(“输入”)和编码后的输入对潜在向量(“条件”)组合在一起,作为一致性模型的输入。随后,执行前向扩散操作,为视频添加噪声。然后,将加噪视频分别发送给学生模型和教师模型,以预测视频。最后,通过蒸馏损失和 DDP 损失分别更新学生模型和 DDPNet。
VideoScene 的流程。 给定输入对视图,我们首先使用快速前馈 3DGS 模型(即MVSplat)生成粗略的 3D 表示,从而实现精确的摄像机轨迹控制渲染。编码后的渲染潜在向量(“输入”)和编码后的输入对潜在向量(“条件”)组合在一起,作为一致性模型的输入。随后,执行前向扩散操作,为视频添加噪声。然后,将加噪视频分别发送给学生模型和教师模型,以预测视频。最后,通过蒸馏损失和 DDP 损失分别更新学生模型和 DDPNet。
结果展示

定性比较。可以观察到基线模型存在诸如模糊、跳帧、过度运动以及物体相对位置偏移等问题,而 VideoScene 实现了更高的输出质量和更好的 3D 连贯性。
结论
VideoScene是一种新颖的快速视频生成框架,它通过提炼视频扩散模型,一步生成 3D 场景。具体而言,利用3D先验知识约束优化过程,并提出一种 3D 感知跳跃流提炼策略,以跳过耗时的冗余信息。此外设计了一个动态去噪策略网络,用于在推理过程中自适应地确定最佳跳跃时间步长。大量实验证明了 VideoScene 在 3D 结构效率和一致性方面的优势,凸显了其作为弥合视频到 3D 差距的高效工具的潜力。


