慕尼黑工业大学和伦敦大学学院提出了一款经过微调的 DINO ViT模型 Pixel3DMM,用于逐像素表面法线和 UV 坐标预测。从上到下,下图展示了 FFHQ 输入图像、估计的表面法线、根据预测的 UV 坐标估计的二维顶点,以及针对上述两个线索的 FLAME 拟合结果。

使用Pixel3DMM 进行野外追踪。
从左到右:输入、预测法线、预测二维顶点、跟踪覆盖、FLAME 跟踪。

单幅图像重建
给定一个输入图像(右上),下图展示了 DECA、FlowFace 和 Ours 相对于地面真实 COLMAP 点云的几何重建。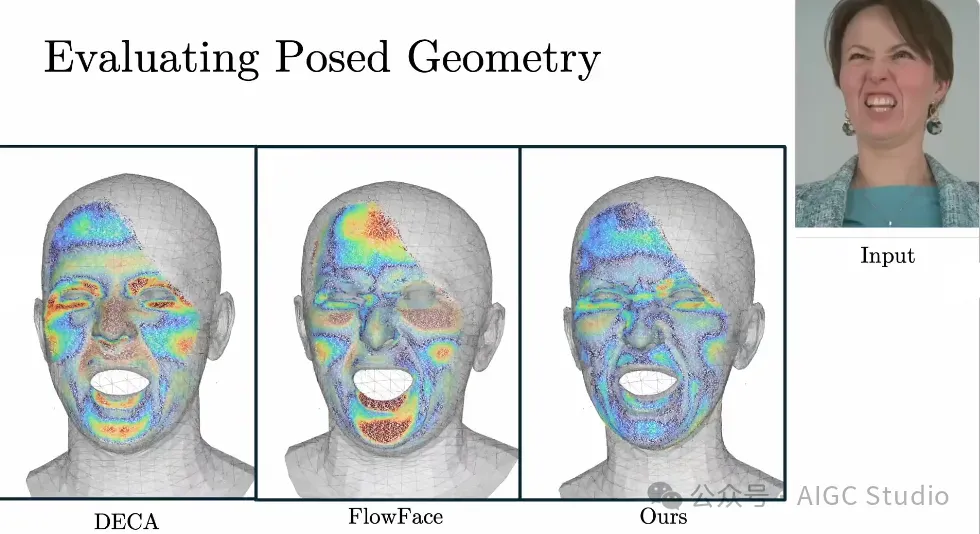
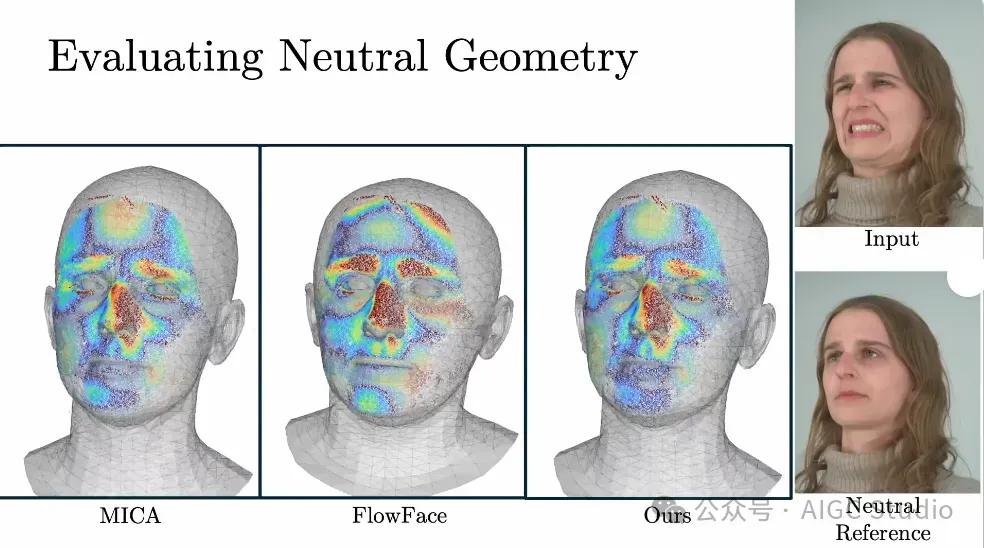
给定一个输入图像(右上),我们展示了 DECA、FlowFace 和 Ours 相对于地面真实 COLMAP 点云的中性几何重建。
相关链接
- 项目:https://simongiebenhain.github.io/pixel3dmm
- 论文:https://simongiebenhain.github.io/pixel3dmm/static/Pixel3DMM.pdf
论文介绍
我们致力于从单张 RGB 图像进行人脸的 3D 重建。为此,我们提出了 Pixel3DMM,这是一组高度泛化的视觉变换器,能够预测每个像素的几何线索,从而限制 3D 可变形人脸模型 (3DMM) 的优化。我们利用 DINO 基础模型的潜在特征,并引入了定制的表面法线和 uv 坐标预测头。我们通过将三个高质量的 3D 人脸数据集与 FLAME 网格拓扑进行配准来训练我们的模型,最终共计生成超过 1,000 个身份和 976,000 张图像。对于 3D 人脸重建,我们提出了一种 FLAME 拟合优化方法,该方法可以根据 uv 坐标和法线估计值求解 3DMM 参数。为了评估我们的方法,我们引入了一个用于单图像人脸重建的新基准,该基准具有高度多样化的面部表情、视角和种族特征。至关重要的是,我们的基准是第一个同时评估姿势面部和中性面部几何形状的基准。最终,我们的方法在姿势面部表情的几何精度方面比最具竞争力的基线高出 15% 以上。
方法概述

- 左图:我们的网络由 DINO 主干网络和轻量级预测头组成。我们在 NPHM、FaceScape 和 Ava256 数据集上训练模型,并使用 FLAME 和非刚性配准将这些数据集转换为统一的格式。
- 右图:在推理阶段,我们使用法线和 UV 坐标预测作为 FLAME 拟合过程中的优化目标。虽然法线约束很简单,但我们首先使用最近邻查找法预测二维顶点位置,从而将 UV 坐标预测纳入其中。
实验结果
表面法线估计
给定一个输入图像(左),下图展示了几个表面法线估计器(右上)和误差图(右下)的预测




