资讯列表

DeepSeek 与元宝 “互动”!AI 助手日渐融入我们的生活
在科技迅速发展的今天,AI 助手已逐渐成为人们日常生活中不可或缺的一部分。 12 月 24 日,DeepSeek 官方在小红书上与元宝互动,点赞并回应了元宝发布的年度报告,这一罕见的公开互动引起了行业的广泛关注。 根据《元宝 ×DeepSeek 年度报告》,自今年 2 月接入 DeepSeek 以来,元宝的用户规模稳步增长,并在 12 月 14 日达到了使用高峰,增长幅度超过 100 倍。

长城汽车全面升级!哈弗猛龙将首次搭载城区 NOA,智能驾驶加速普及
在智能汽车技术快速发展的今天,长城汽车再一次引起了业界的关注。 继魏牌蓝山成功搭载智能辅助驾驶系统后,长城旗下的核心品牌哈弗也将迎来一项重大升级 —— 首次在其车型上搭载城区 NOA(导航辅助驾驶)。 这一消息无疑为长城的销量主力注入了新动力。

全球首款无需遥控的智能机器狗,维他动力“大头 BoBo”将开启公测
AI在线 12 月 25 日消息,今日,Vbot 维他动力联合创始人赵哲伦宣布机器狗“大头 BoBo”将开启公测,这款产品号称“全球首款无需遥控的智能机器狗”,于 12 月 23 日正式发布并开启预订。 AI在线附公测详情:2026 年 1 月 12 日,向所有预订用户公开发布公测报名问卷;首批公测用户,将会在 1 月底之前,收到公测产品;1 月到 3 月期间,持续招募公测用户,预计测试 500 台;公测不收取任何费用,公测产品的使用时限为 8 周,8 周后回收产品,到工厂做全面检测;若公测过程中机器狗出现故障,将召回产品进行全面检测;2026 年 3 月,将会开启预订锁单,按锁单顺序进行交付。 据此前官方介绍,该产品采用 1:1 的大小腿比例,搭载 12 个自研关节电机。

周大福与火山引擎携手推出 AI 智能助手,提升珠宝零售效率
近日宣布与火山引擎达成合作,推出全新的 “AI 阿福智能体家族”,旨在通过人工智能技术提升珠宝零售行业的运营效率。 随着全球业务规模的不断扩展,周大福珠宝在运营中面临着越来越复杂的挑战,因此决定积极拥抱 AI 技术,以提高各个业务环节的效率。 自2024年末 AI Agent 平台上线以来,周大福珠宝已构建351个智能体,为公司内的市场、财务、IT、人力资源和销售等多个部门提供支持。

200台机器人上岗!京东物流“智狼”远征英国,加速织就全球供应链网
12月25日,京东物流宣布其在英国的首个“智狼仓”正式投入使用。 作为京东在英国打造的自动化标杆项目,该仓库占地面积超过3000平方米,内部配置了近200台京东物流自主研发的“智狼机器人”。 得益于高度自动化的仓储管理,该智狼仓的拣货及出库效率相比传统模式实现了约4倍的显著提升,大幅增强了京东在当地的履约响应能力。
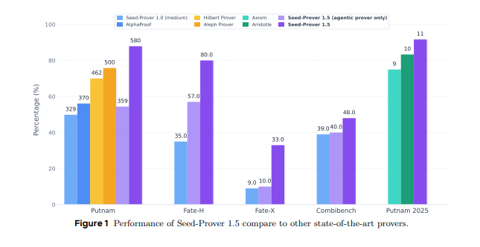
字节 Seed 新模型问世:数学竞赛金牌实力爆表,AI 推理迈入新阶段!
近日,字节跳动旗下的 Seed AI 团队发布了一款名为 Seed Prover1.5的数学推理模型,该模型在国际数学奥林匹克(IMO)比赛中表现卓越,成功获得金牌,标志着人工智能在数学领域的又一突破。 Seed Prover1.5采用了 Scaling Law 理论,并在16.5小时内解决了 IMO2025的前五道题,仅失一题,最终以35分的成绩达到了金牌标准。 这一成绩与谷歌 Gemini 并驾齐驱,而字节之前的模型在当时需用三天才完成四道题,最终仅获得银牌。

解锁机器人的 3D 视觉:原力灵机推出 GeoVLA 框架,颠覆传统 VLA 模型!
在人工智能和机器人技术快速发展的今天,视觉 - 语言 - 行动(VLA)模型被广泛认为是构建通用机器人的关键。 然而,许多现有的 VLA 模型(如 OpenVLA、RT-2等)在处理复杂的非结构化环境时暴露出一个严重的短板:空间失明。 它们依赖于2D RGB 图像作为视觉输入,导致模型在三维空间中的表现受限,难以准确判断物体的深度和位置。

2030年全球AI消费将达7000亿美元:硬件仍是主角,软件正决定成败
根据分析机构Counterpoint Research最新发布的预测报告,全球生成式 AI 领域的消费支出正步入爆发式增长期。 预计到2030年,全球消费者的相关总支出将达到近7000亿美元。 这一增长引擎将由终端硬件的更新换代与应用层软件的普及共同驱动。

清华开源 TurboDiffusion:AI 视频生成步入“秒级”时代,最高提速达 200 倍
近日,清华大学 TSAIL 实验室联合生数科技推出了全新的开源视频生成加速框架TurboDiffusion。 这一突破性的技术框架在确保视频生成质量不减的前提下,成功将端到端扩散生成的推理速度提升了100至200倍。 AIbase 获悉,该框架为了实现极致的生成效率,集成了 SageAttention 和 SLA(稀疏线性注意力机制)。

纽约州正式签署《RAISE法案》严管先进AI模型
近日,纽约州州长凯西·霍楚尔正式签署了备受关注的《负责任人工智能与安全教育法案》(简称RAISE法案)。 这一举动不仅标志着纽约州在AI监管上迈出实质性一步,更被外界视为对联邦政府近期试图削弱州级监管政策的直接回应。 AIbase 获悉,该法案的核心目标是为全球最先进的 AI 模型划定安全红线。

微软辟谣“重写 Windows”传闻:暂无使用 AI 和 Rust 彻底更替代码的计划
近日,关于微软将利用人工智能(AI)和 Rust 编程语言彻底重写 Windows 操作系统的消息在技术圈引发了广泛热议。 起因是微软杰出工程师盖伦·亨特在招聘信息中提到,计划在2030年前通过 AI 辅助,实现每月迁移百万行代码的目标,以替代现有的 C/C 代码库。 针对这一传闻,微软官方正式发布声明予以澄清。

2026 北京亦庄人形机器人半程马拉松开启报名,首届天工 Ultra 夺冠
AI在线 12 月 25 日消息,今日,在北京市政府新闻办公室举行的发布会上,北京经济技术开发区(北京亦庄)发布消息称将于 2026 年 4 月 19 日举办人形机器人半程马拉松和北京亦庄半程马拉松。 赛事采用“人机共跑”模式,人类选手和人形机器人选手同时起跑、共用同一赛道。 北京经济技术开发区管委会副主任梁靓介绍,本届赛事以“亦马当先”为主题,起点设于北京亦庄通明湖畔的科创十七街,终点为南海子公园,全长 21.0975 公里,赛道融合城市主干道、国际汽车赛事路段与公园生态场景,实现硬核科技街区和自然生态空间的衔接,为机器人提供真实、多元、复杂的实战环境,全面检验其在开放场景中的适应与决策能力,推动人形机器人从“遥控”到“自主”关键跃迁。

美银分析师:2026 年半导体营收同比将增长三成,总额破万亿美元
AI在线 12 月 25 日消息,根据《雅虎财经》引述的报告,美国银行分析师 Vivek Arya 预测,2026 年全球半导体产业营收将同比增长 30%,总额则将超越 1 万亿美元(AI在线注:现汇率约合 7.03 万亿元人民币)。 图源:Pixabay对于 AI 数据中心,这位分析师表示到 2030 年该领域的潜在市场总额将超过 1.2 万亿美元,CAGR 复合年增长率是惊人的 38%,而仅 AI 加速器一项的市场机遇就将达到 9000 亿美元。 对于如此高昂的 AI 支出,Vivek Arya 认为大型科技企业目前的投资既具有“进攻性”也具有“防御性”:企业必须大手笔投资才能在厮杀的业界中稳固自身基本盘。

阿里通义 Qwen-lmage-Edit-2511 图像编辑 AI 模型开源,支持两人隔空“合照”
AI在线 12 月 25 日消息,阿里通义千问今日宣布 Qwen-Image-Edit-2511 正式开源。 Qwen-Image-Edit 是阿里通义团队推出的图像编辑模型。 2511 版本中着重进行了包括一致性提升在内的多项增强,新版本的整体生成质量、尤其是人物生成质量,得到显著提升。

清华开源 TurboDiffusion:AI 视频生成最高提速 200 倍,单张 RTX 5090 秒出大片
AI在线 12 月 25 日消息,清华大学 TSAIL 实验室联合生数科技推出开源视频生成加速框架 TurboDiffusion,该框架能在保持视频质量的前提下,将端到端扩散生成的推理速度提升 100 至 200 倍。 在技术方面,TurboDiffusion 为实现极致的推理速度,采用了 SageAttention 和 SLA(稀疏线性注意力机制)来加速注意力计算,显著降低了模型处理高分辨率视频时的算力开销。 其次,团队引入了 rCM(时间步蒸馏)技术,有效减少了扩散模型的采样步数。

修图 AI 模型 Qwen-Image-Edit-2511 开源上线:提升角色一致性、增强几何推理
AI在线 12 月 25 日消息,阿里通义 Qwen 团队于 12 月 23 日上线推出 Qwen-Image-Edit-2511 全新图像编辑模型,在 Qwen-Image-Edit-2509 基础上,减轻图像漂移、提升人物一致性、集成 LoRA 能力、增强工业设计生成能力,以及强化几何推理能力。 该模型作为通义家族在视觉生成领域的最新尝试,专门针对“图像编辑”场景进行了优化。 不同于传统的文生图模型(Text-to-Image),该模型主要解决的是“在保持原图主体结构不变的前提下,对特定区域进行精准修改”这一行业难题,为开发者和设计师提供了更高效的 AI 辅助工具。
中文数据占比突破80%!国产大模型加速“去英文依赖”,文化理解成AI竞争新高地
当AI开始真正“读懂”中文,一场静默的技术革命正在发生。 在国产大模型竞速赛中,中文高质量数据正成为决定胜负的关键变量。 据行业调研,当前主流国产大模型训练数据中,中文内容占比普遍超60%,部分模型甚至高达80%,显著降低对英文语料的依赖。

X 平台推出 AI 图片编辑器,部分创作者撤离
近日,X 社交平台宣布上线一款基于 xAI Grok 技术的在线图片 AI 编辑功能,用户可以在发布帖子时,轻松找到编辑按钮,点击后即可输入提示词进行图片编辑。 这一新功能旨在为用户提供更便捷的图片处理体验,吸引更多用户参与内容创作。 然而,这项新功能却引发了广泛的争议。