非羊 整理自 凹非寺
量子位 | 公众号 QbitAI
一张照片,就能生成可直接用于仿真的3D资产。
(没错,下图中几乎所有物体都是AI生成的)

随着三维建模从传统的静态视觉效果,逐步迈向可用于仿真与交互的物理可动资产,如何直接生成具备物理属性与关节结构的3D对象,成为推动具身智能(embodied AI)发展的关键。
然而,现有大多数3D生成方法往往忽视这些核心的物理与运动特性,严重限制了其在机器人等相关领域的应用。
为此,来自南洋理工大学与上海人工智能实验室的合作研究团队提出PhysX-Anything——首个面向仿真、具备物理属性的3D生成框架:仅需单张图像,即可生成高质量、可直接用于仿真的3D资产,并同时具备显式几何结构、关节运动以及物理参数。
在机器人、具身智能和交互仿真等任务中,对能在物理引擎中直接运行的高质量3D资产需求日益增长。然而,当前大多数3D生成方法仍侧重于整体几何与外观,或仅关注部件结构,普遍缺失密度、绝对尺度、关节约束等关键物理信息,难以直接用于真实仿真与控制。
尽管已有少数研究开始探索可动3D对象的生成,但由于高质量3D物理标注数据的稀缺,多采用“检索现有模型+附加运动”的范式,难以从单张真实图像泛化生成全新且物理一致的资产。此外,现有方法对形变行为的建模也常假设材料均匀或忽略部分物理属性。即便是能够生成物理3D资产的PhysXGen,其输出也尚未支持在主流物理引擎中即插即用,限制了在控制任务中的实用性。
为弥合合成3D资产与真实下游应用之间的差距,研究团队提出了PhysX-Anything——首个面向仿真的物理3D生成范式。该框架仅凭一张图像,即可生成高质量、可直接导入标准模拟器的sim-ready(仿真就绪)3D资产。该成果有望为3D生成、具身智能与机器人领域带来新的可能性与研究范式。

PhysX-Anything采用“由粗到细(coarse-to-fine)”的生成框架。给定一张真实场景图像,系统通过多轮对话,依次生成整体物理描述与各部件几何信息,通过对物理表征进行解码,最终解码输出六种常用格式的可仿真3D资产。
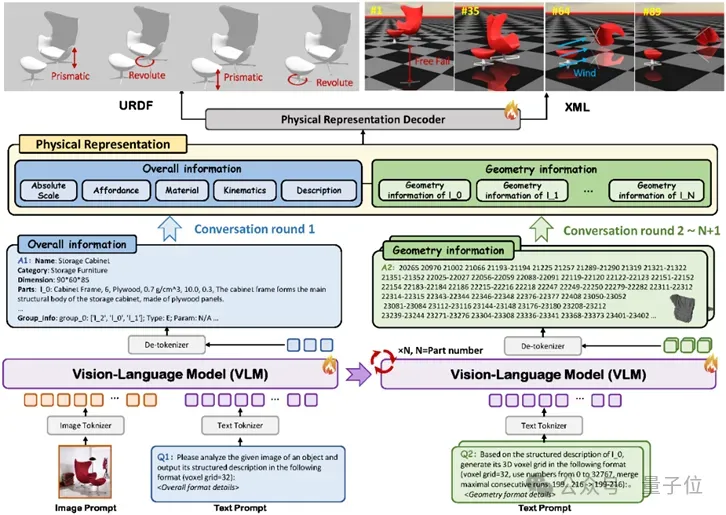
在传统视觉语言模型(VLM)中进行3D生成时,为压缩原始网格的token长度,主流方法通常采用基于顶点量化的文本序列表示,但所得几何token仍十分冗长。3D VQ-GAN虽可进一步压缩几何token,却需要在微调阶段引入额外特殊token和自定义tokenizer,增加了训练与部署的复杂度。
为此,研究团队提出一种新型3D表征方式,在显式保留几何结构的同时显著缩短token序列,且无需任何额外token。该方法受体素(就是三维的像素)表征在精度与效率间良好折中的启发,基于体素构建几何表示:首先在323体素网格上由VLM建模粗略几何,再由下游解码器细化得到高保真形状,从而保留体素显式结构优势,同时避免过高token开销。

在整体信息表征上,团队沿用树状、VLM友好的结构,并以JSON风格格式替代标准URDF,使其包含更丰富的物理属性与文本描述,便于VLM理解与推理。同时,团队将关键运动学参数(如运动方向、关节轴位置、运动范围等)统一映射到体素空间,以保证运动学与几何结构的一致性。
在上述物理3D资产表征的基础上,研究团队采用Qwen2.5作为基础模型,并在自建的物理3D数据集上对该VLM进行微调。通过精心设计的多轮对话流程,PhysX-Anything能同时生成高质量的全局描述(整体物理与结构属性)与局部信息(部件级几何)。
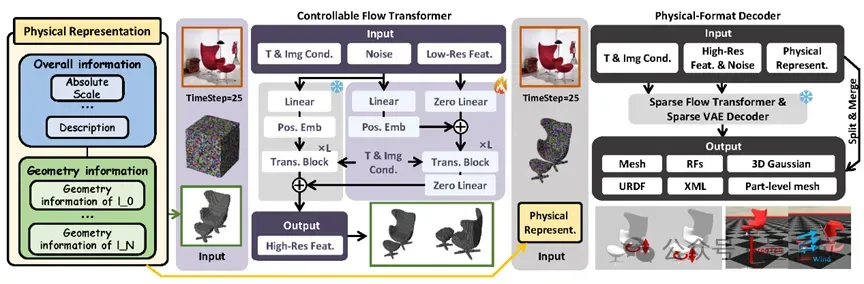
为获取更精细的几何细节,团队受ControlNet启发,设计了一个可控的flow transformer。该模块将粗体素表示作为扩散模型的引导信号,控制细粒度体素几何的生成。在得到细粒度体素表示后,系统采用预训练的结构化潜在扩散模型解码出多种格式的3D资产,包括网格表面、辐射场与3D高斯等。
随后,基于体素分配结果,使用最近邻算法将重建网格划分为部件级组件。
最终,结合全局结构信息与细粒度体素几何,PhysX-Anything能够生成用于仿真的URDF、XML及部件级网格,实现“仿真就绪”的物理3D生成。
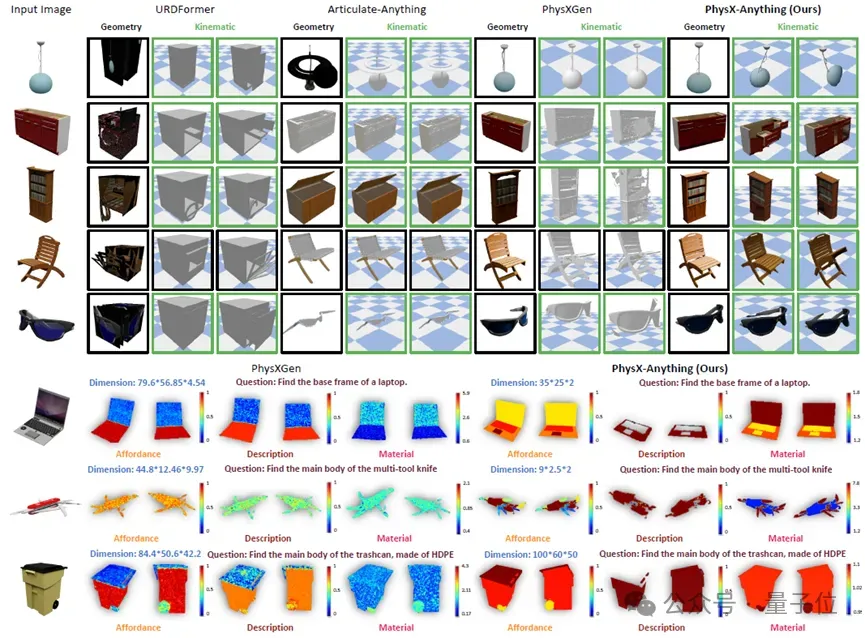
研究团队将PhysX-Anything与当前最新方法URDFormer、Articulate-Anything和PhysXGen进行对比。如下表所示,PhysX-Anything在几何与物理两类指标上均取得最优表现。得益于强大的VLM先验,其在绝对尺度上的误差大幅降低。此外,由于VLM结构适合处理文本,PhysX-Anything在文本描述相关指标上也取得最高得分,表明该方法方法不仅能够生成物理上合理的属性,还能产出连贯的、具备部件层级的文字描述,对物体结构与功能具备较强理解能力。

除了定量结果,定性对比也清晰显示,PhysX-Anything在泛化能力方面具有显著优势,尤其相较于检索式方法更为突出。依托强大的VLM先验与高效表征设计,该系统还能生成比PhysXGen更合理、可信的物理属性。
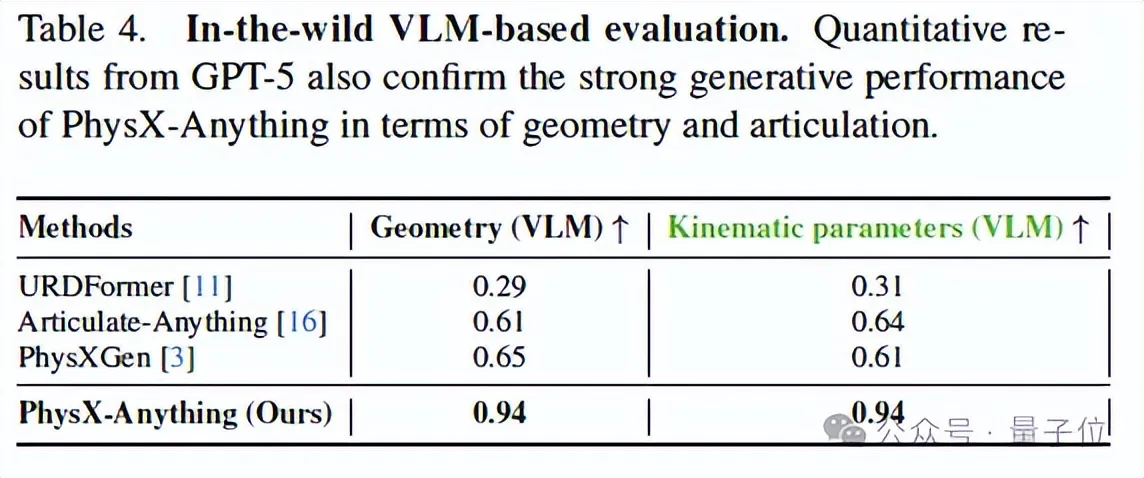
基于VLM的评估:为评估方法的泛化能力,团队进一步在真实世界图像上测试其性能。这些图像覆盖了最常见的日常物体类别。为避免VLM在某些具体物理属性上判断不稳定的问题,本次评估重点放在几何与关节运动质量上。结果表明,PhysX-Anything在几何与运动学参数两项指标上均显著优于所有对比方法,显示出对真实输入的强泛化能力。
作为补充,团队还召集了一些人类志愿者为不同模型的生成结果打分,PhysX-Anything的生成结构在几何与物理属性都获得了最高分,表明其生成结果对比来看也更受人类认可。
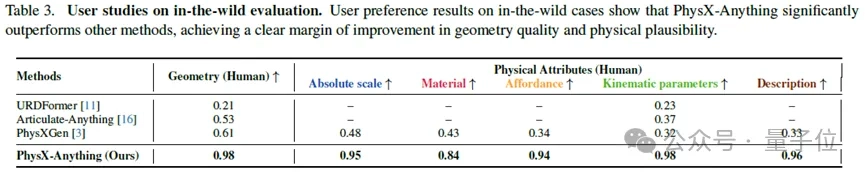
在真实场景上的可视化结果也可进一步直观展示该方法的优势:PhysX-Anything能够生成更加准确的几何结构、关节运动以及物理属性。
为验证生成资产对下游任务的支撑能力,团队在MuJoCo风格的模拟器中进行了实验。生成的sim-ready 3D资产——包括水龙头、柜子、打火机、眼镜等日常物体——可以直接导入模拟器,并用于接触丰富的机器人策略学习。
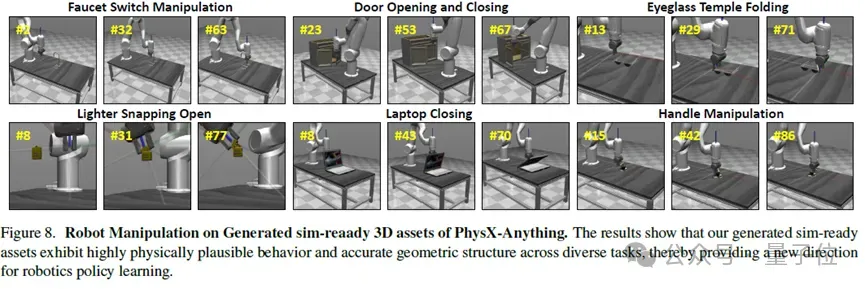
该实验不仅展示了生成资产在物理行为与几何结构上的高度可信性,也突显了它们在推动多种下游机器人与具身智能应用方面的巨大潜力。
研究团队提出首个面向仿真的物理3D生成范式PhysX-Anything,通过统一的VLM管线与定制3D表征,在显式保留几何结构的前提下实现超过193倍的token压缩,显著提升了物理3D生成的效率与可扩展性。
同时,团队构建了覆盖47个常见真实类别、具备丰富物理标注的PhysX-Mobility数据集,大幅拓展了现有物理3D资产的多样性。基于该数据集及真实世界场景的实验表明,PhysX-Anything在sim-ready物理3D生成上具有优异性能与稳健泛化能力,仿真实验进一步验证了其在下游机器人策略学习中的应用潜力。
该框架有望为3D视觉、具身智能与机器人研究开辟新的方向,推动从“视觉建模”到“物理建模”的范式转变。

视频链接:https://mp.weixin.qq.com/s/gUooZUSc1yWQlf4NpViZrA
原论文第一作者曹子昂,南洋理工大学博士二年级,研究方向是计算机视觉、3D AIGC和具身智能。主要合作者为来自南洋理工大学洪方舟、陈昭熹和来自上海人工智能实验室的潘亮,通讯作者为南洋理工大学刘子纬教授。
论文链接:https://arxiv.org/abs/2511.13648 项目主页:hthttps://physx-anything.github.io/ GitHub代码:https://github.com/ziangcao0312/PhysX-Anything


