
本论文主要作者来自小红书 AIGC 团队(Dynamic-X-Lab),Dynamic‑X‑LAB 是一个专注于 AIGC 领域的研究团队,致力于推动姿态驱动的人像生成与视频动画技术。他们以高质量、高可控性的生成模型为核心,围绕文生图(t2i)、图像生成(i2i)、图像转视频(i2v)和风格迁移加速等方向展开研究,并通过完整的开源方案分享给开发者与研究者社区。

论文标题:DynamicFace: High-Quality and Consistent Face Swapping for Image and Video using Composable 3D Facial Priors
论文链接:https://arxiv.org/abs/2501.08553
项目主页:https://dynamic-face.github.io/
近年来,扩散模型在图像与视频合成领域展现出前所未有的生成能力,为人脸生成与编辑技术按下了加速键。特别是一张静态人脸驱动任意表情、姿态乃至光照的梦想,正在走向大众工具箱,并在三大场景展现巨大潜力:
影视行业:导演只需一张定妆照,即可让演员「数字替身」在绿幕里实时完成高难度的表情捕捉与重打光,后期不再为补拍镜头而烧预算,真正进入「先拍脸、后拍景」的降本增效时代。
游戏行业:捏脸系统将不再局限于预设模板。玩家上传一张自拍,即刻生成 360° 可旋转、可眨眼、可微表情的个性化角色;配合实时语音驱动,NPC 的口型与情绪可随剧情即时变化,沉浸式体验再升一级。
自媒体与电商:短视频创作者无需真人出镜,一张品牌代言照即可批量产出不同光线、不同角度的口播视频;虚拟主播更可 7x24 小时直播带货,表情自然、光影一致,告别「恐怖谷」效应。
人脸视频生成的核心难题在于,如何在根据参考图像和外部动作序列,严谨地保持源参考人脸身份特征不被损伤的同时,还要维持目标人脸动作的一致性。现有方法在追求真实动态表现时,通常会遭遇以下三大挑战:
空间与时间建模的内在矛盾:许多聚焦于身份一致性的图像生成模型在空间特征提取方面已足够优秀,然而由于在注入运动信息时耦合了目标身份特征,进而导致运动信息不准确,一旦需要建模时间变化的视频扩散模型时,不准确的运动建模会被逐帧放大,最终陷入身份还原能力和运动一致难以两全的问题。
身份一致性降低:在复杂或大幅度动作变化情况下,面部区域极易出现形变、失真,难以保证人物独特的面貌特征能随时保留。这种问题直接影响动画人物的个体识别度和可信度,也是用户接受数字人像动画的首要阻碍。
整体视频质量受损:当前最优秀的人像动画生成模型虽然在动画效果层面取得进展,但往往还需借助外部换脸后处理工具以改善关键帧细节。可惜,这类后处理虽能暂时修复细节,却往往损伤了整段视频在视觉上的统一性和自然度,导致画面出现割裂感和不连贯的现象。
小红书提出 DynamicFace,让视频人脸交换迈入「电影级」工业流水线!
方法介绍
本研究提出了一种创新性的人脸置换方法 DynamicFace,针对图像及视频领域的人脸融合任务实现了高质量与高度一致性的置换效果。
与传统人脸置换方法相比,DynamicFace 独创性地将扩散模型(Diffusion Model)与可组合的 3D 人脸先验进行深度融合,针对人脸运动与身份信息进行了精细化解耦,以生成更一致的人脸图像和视频。
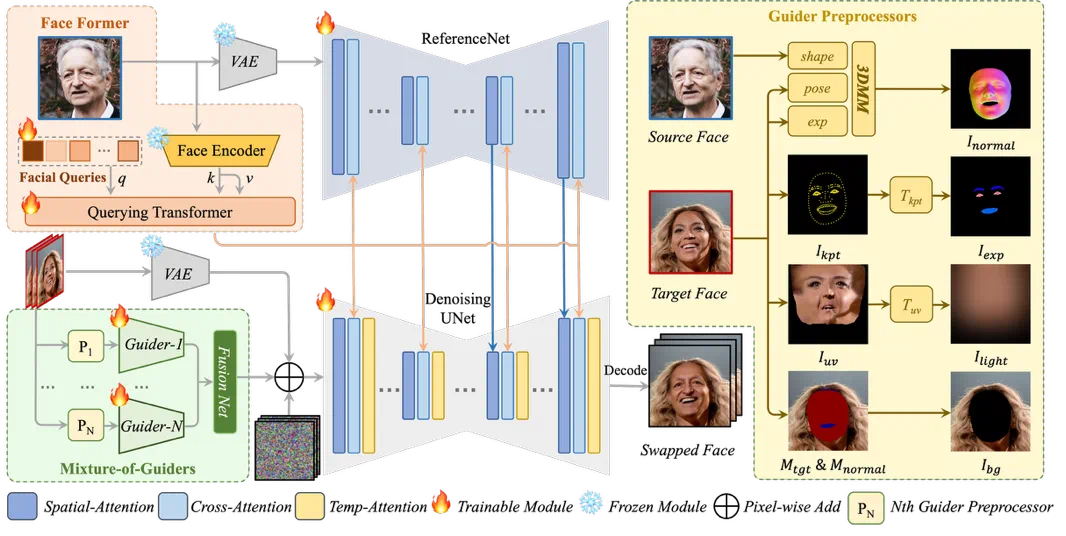
可组合三维面部先验的显式条件解耦
针对现有方法在身份与运动表征中普遍存在的耦合冗余问题,DynamicFace 提出将人脸条件显式分解为身份、姿态、表情、光照及背景五个独立的表征,并基于 3DMM 重建模型获取对应参数。
具体而言,利用源图像提取身份形状参数 α,目标视频逐帧提取姿态 β 与表情 θ,随后渲染生成形状–姿态法线图,减少目标人脸身份泄露,最大程度保留源身份;表情信息从二维关键点中提取,建模更精准的表情信息,仅保留眉毛、眼球及口唇区域的运动先验,避免引入目标身份特征;光照条件由 UV 纹理图经模糊处理得到,仅保留低频光照分量;背景条件采用遮挡感知掩码与随机位移策略,实现训练–推理阶段的目标脸型对齐。
四条条件并行输入 Mixture-of-Guiders,每组由 3×3 卷积与零初始化卷积末端构成轻量级条件注入模块,在注入网络前经过 FusionNet 融合四个条件特征后注入到扩散模型中,可在保持 Stable Diffusion 预训练先验的同时实现精准控制。
身份–细节双流注入机制
为实现高保真身份保持,DynamicFace 设计了双流并行注入架构。高层身份流由 Face Former 完成:首先利用 ArcFace 提取 ID Embedding,再通过可学习 Query Token 与 U-Net 各层 Cross-Attention 交互,确保全局身份一致性;细节纹理流由 ReferenceNet 实现,该网络为 U-Net 的可训练副本,将 512×512 源图潜变量经 Spatial-Attention 注入主网络,实现细粒度的纹理迁移。
即插即用时序一致性模块
针对时序一致性问题,DynamicFace 会在训练中插入时序注意力层来优化帧间稳定性,但时序层在处理长视频生成时会出现帧间跳动的现象。为此,我们提出了 FusionTVO,将视频序列划分为若干段,并为每段设置融合权重,在相邻段的重叠区域实行加权融合;并在潜变量空间引入总变差(Total Variation)约束,抑制帧与帧之间的不必要波动;对于人脸之外的背景区域,在每一步去噪迭代过程中采用目标图像中的背景潜变量空间进行替换,维持了场景的高保真度。
生成结果展示




与 SOTA 方法的定性对比实验
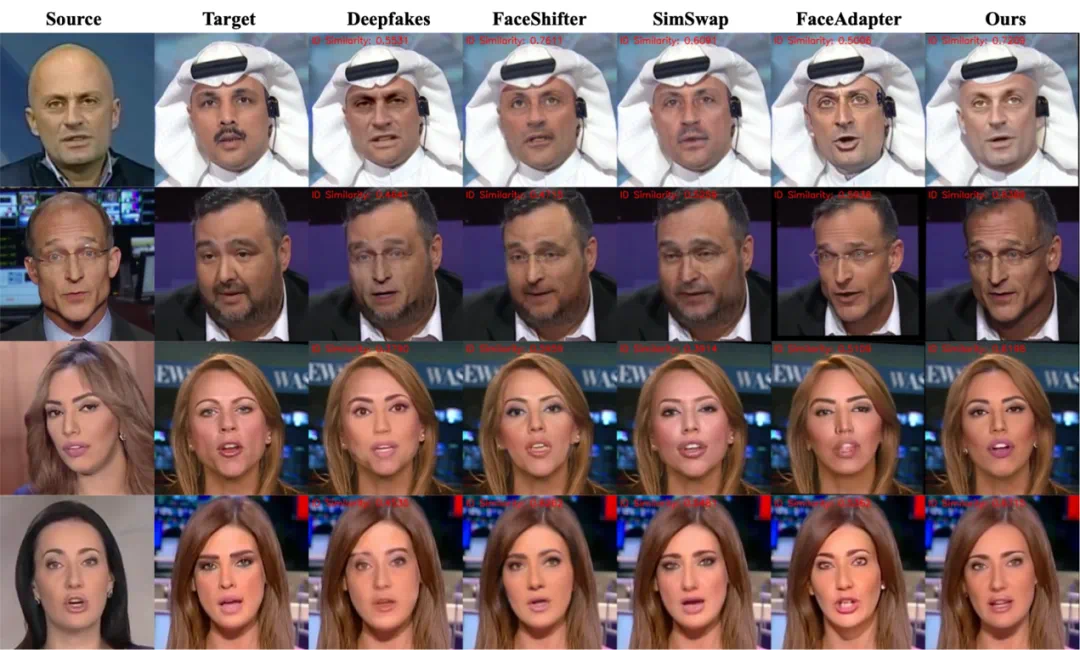


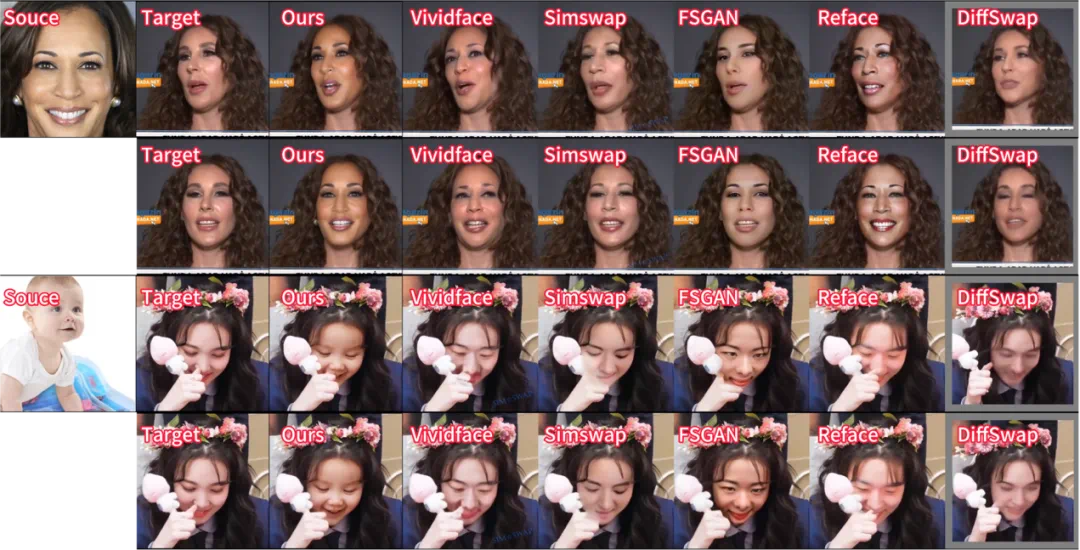
DynamicFace 可以很好地保持身份(例如,形状和面部纹理信息)和动作(包括表情和姿势等),并且生成结果维持了更好的背景一致性。
具体来说,基于 GAN 的方法往往会生成较为模糊、视觉上并不真实且身份一致性较差的结果,但可以维持不错的运动一致性;其他基于扩散模型的方法能生成分辨率更高且更真实的结果,但运动一致性保持较差(如表情不一致,眼神朝向不同等)。
DynamicFace 通过精细化解耦的条件注入可以保证更优的表情一致、眼神一致和姿势一致性。
与 SOTA 方法的定量对比实验
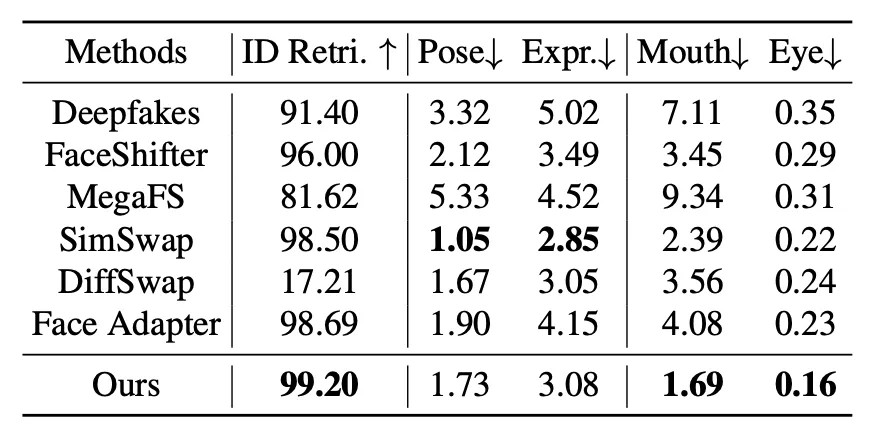
为全面评估 DynamicFace 的性能,研究团队在 FaceForensics++(FF++)和 FFHQ 数据集上进行系统性的定量实验,并与当前最具代表性的 6 种换脸方法进行对比,包括 Deepfakes、FaceShifter、MegaFS、SimSwap、DiffSwap 以及 Face Adapter。
实验遵循先前论文的参数设置:从每个测试视频中随机抽取 10 帧作为评估样本,并另取连续 60 帧用于视频级指标计算。所有方法均使用官方开源权重或公开推理脚本,在输入分辨率(512×512)下复现结果。定量结果如表中所示:DynamicFace 同时在身份一致性(ID Retrieval)和运动一致性(Mouth&Eye Consistency)达到了最优的结果。
整体而言,实验结果充分证明了 DynamicFace 在身份保真与运动还原方面的综合优势,验证了其在高质量人脸可控生成中的卓越性能。
更多应用样例
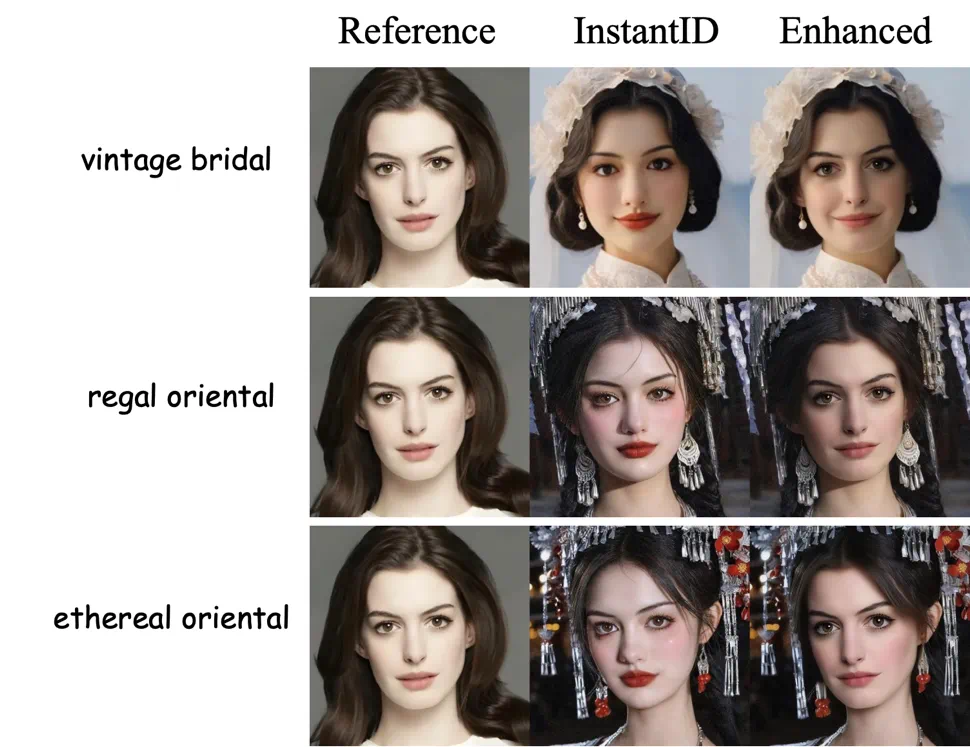

我们也展示了一些其他的应用示例,DynamicFace 可以对身份保持和人体驱动等生成结果进行后处理,显著提升生成结果的人脸 ID 一致性和表情控制,更多效果展示可以在项目主页中进行查看。期望这种精细化解耦条件注入的方法能为可控生成的后续工作提供新思路。


