
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。
UniOcc 融合真实世界(nuScenes、Waymo)与仿真环境(CARLA、OpenCOOD)的多源数据,统一体素(voxel)格式与语义(semantic)标签,首次引入体素级前后向运动流标注,并支持多车协同占位预测与推理。为摆脱伪标签(pseudo-label)评估限制,UniOcc 设计了多项免真值(ground-truth-free)指标,用于衡量物体形状合理性与时序一致性。在多个 SOTA 模型上验证了其在运动流信息利用、跨域泛化和协同预测方面的显著优势。
UniOcc 已全面开源,支持占位预测、长时序预测、动态追踪等多种任务,致力于构建标准化的感知研究平台,推动自动驾驶迈向多模态、泛化能力更强的新阶段。
论文标题:UniOcc: A Unified Benchmark for Occupancy Forecasting and Prediction in Autonomous Driving
论文链接: https://arxiv.org/abs/2503.24381
项目主页: https://uniocc.github.io/
代码开源: https://github.com/tasl-lab/UniOcc
数据集下载:
Hugging Face: https://huggingface.co/datasets/tasl-lab/uniocc
Google Drive: https://drive.google.com/drive/folders/18TSklDPPW1IwXvfTb6DtSNLhVud5-8Pw?usp=sharing
百度网盘: https://pan.baidu.com/s/17Pk2ni8BwwU4T2fRmVROeA?pwd=kdfj 提取码 kdfj
背景与挑战
占用栅格(3D Occupancy Grid)是自动驾驶感知的重要方向,旨在从传感器数据构造或预测(Prediction and Forecasting)三维占用格栅。然而当前研究面临诸多挑战:
伪标签缺陷:主流数据集(如 nuScenes、Waymo)缺乏真实占位标注,只能依赖 LiDAR 启发式生成的伪标签。这些伪标签通常仅覆盖可见表面,无法反映真实物体的完整形状,导致训练出的模型结果欠佳,且使用传统 IoU 等指标无法发现此类问题。Figure 3 展示了 Occ3D 伪标签的缺失形状与模型预测的对比。

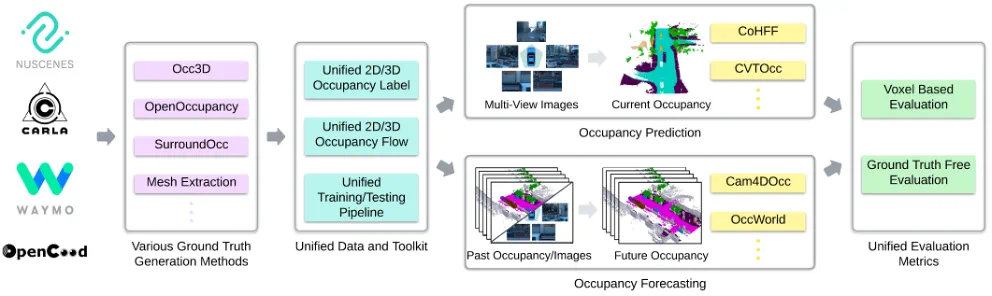
数据割裂:现有方法多局限于单一数据源,不同数据集间配置、采样率、格式、注释不统一,训练和评估都需分别适配。为此迫切需要统一格式和工具链来跨数据集训练和测试,提高模型泛化能力。
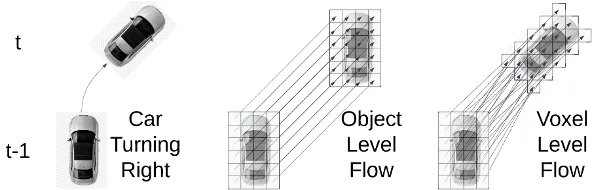
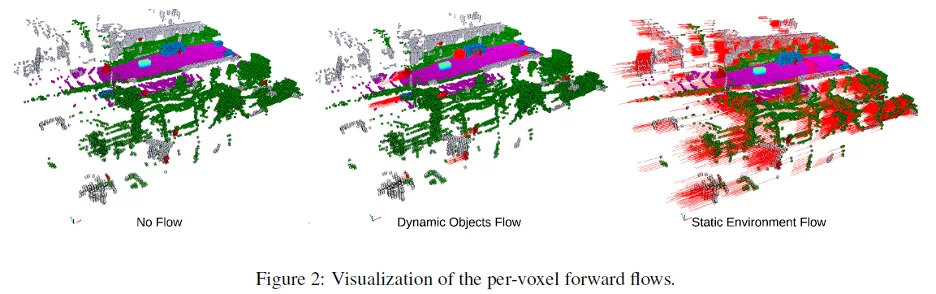
动态信息缺失:当前三维占位标签通常不包含物体运动信息,模型无法利用运动线索进行预测。与以往单个物体层面(Object-level)的运动流(Occupancy Flow)不同,UniOcc 首次在占位数据中提供体素级(Voxel-level)的三维运动流标注(对比如下图),可以捕捉物体的平移和旋转信息,从而增强对动态场景的建模。
协同驾驶:尽管多车协同感知是前沿方向,之前缺乏多车协同占位预测的数据集。UniOcc 基于 OpenCOOD 扩展了多车场景,成为首个支持多车协同占位预测的开放基准。
UniOcc 的四项关键创新
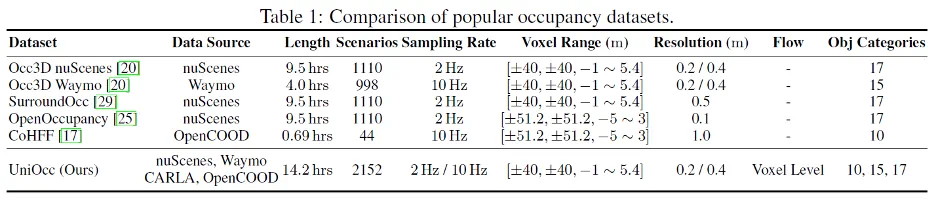
多源数据统一处理:UniOcc 汇聚了真实场景(nuScenes、Waymo)和仿真场景(CARLA、OpenCOOD)的数据,统一格式并提供标准化的数据预处理和加载 Dataloader。这是首个将多个占位数据源集成在同一个框架下的工作,使得研究者可以 “开箱即用” 地进行跨域训练和评估 (Table 1)。
体素级运动流标注:UniOcc 为每个三维体素同时标注了前向和反向三维速度向量,全面记录物体的平移与旋转。这种体素级运动流标注是占位预测领域首次提出的创新,有助于模型更好地捕捉场景中的动态变化(Figure 2)。
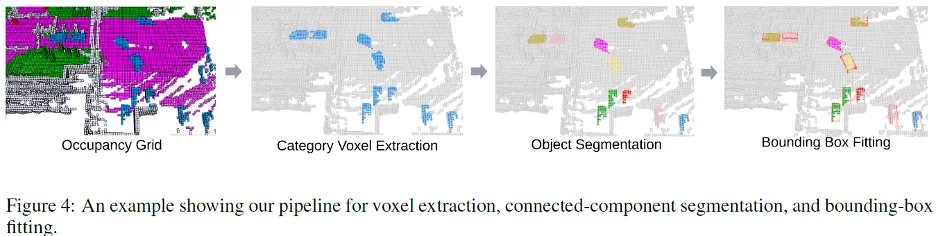
免真值评估指标:UniOcc 提出了免真值的评估指标和工具,避免只依赖伪标签进行评价。通过学习真实物体尺寸分布的高斯混合模型(GMM)等方法,UniOcc 可以在无完美标签的情况下定量评估预测合理性。在时间维度上,UniOcc 提供的工具可以对连续帧中同一物体及背景的 Voxel 分别进行提取和对齐,实现了对于时序一致性的评估(Figure 4)。
支持协同预测能力:通过扩展 OpenCOOD 框架,UniOcc 涵盖了多车协同感知场景,使得研究者可以探索多车传感器融合的方法。
实验验证
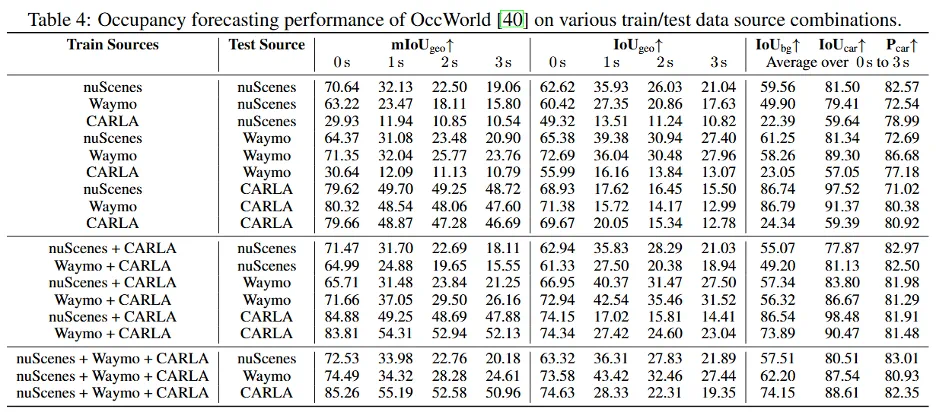
引入运动流信息:将 UniOcc 提供的体素运动流输入 OccWorld 等 3D 占位预测模型后,预测性能显著提升。Table 3 中可见,在 nuScenes 和 Waymo 上加入流信息后,各类别的 mIoU 指标均有提高。

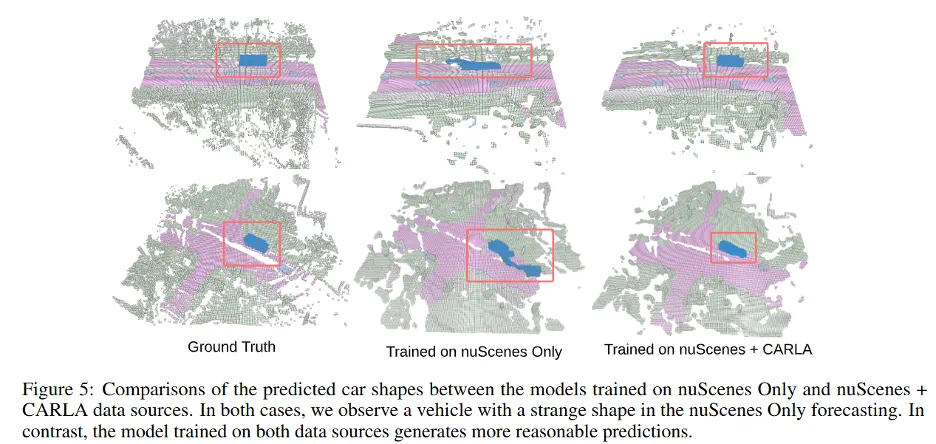
多源联合训练:利用多源数据进行训练可增强跨域泛化能力。Table 4 显示,在 nuScenes 和 CARLA 等多域数据上联合训练 OccWorld,其在各自测试集上的 mIoU 均优于单源训练,详见 Table 4 中 不同训练源组合下的性能。与此同时由于从 CARLA 获得的占用栅格外形接近完美,不存在伪标签中的不完整问题,训练中加入 CARLA 数据提高了生成物体的真实性(Figure 5)。
验证现有 Occupancy 预测模型的质量:在 Table 5 中,作者使用 UniOcc 对 Cam4DOcc 和 CVTOcc 的生成质量进行了度量并且使用 UniOcc 可以对如 Figure 3 的不完整预测进行归类分析(Problem Cluster)。

协同预测效果:在模拟的多车场景中验证了协同优势。以 CoHFF 模型为例,在 OpenCOOD 多车数据上进行测试时,通过多车信息共享对 Car 类别的 IoU 达到了 87.22%,验证了协同感知能够扩展视野、减轻遮挡的潜力。

开源与应用价值
UniOcc 框架设计统一,可支持多种占位相关任务,包括:
单帧占位预测:从当前相机 / 激光雷达数据估计当前时刻的 3D 占位格 (如 CVTOcc);
多帧占位预测:基于历史信息预测未来时刻的三维占位(如 OccWorld);
多车协同预测:在多车共享感知信息下完成占位预测,提升覆盖范围 (如 CoHFF);
动态分割与跟踪:利用体素级流信息进行动态目标的分割与跟踪。UniOcc 还包含体素分割和跟踪工具,使得研究者可以直接在占位格空间中进行目标识别和跨帧关联。
总结与展望
UniOcc 作为首个自动驾驶占位预测统一基准,将推动行业从依赖伪标签的阶段迈向真正的统一评估体系。它提供了跨域的数据格式、完整的流注释、分割跟踪工具和免真值评估指标,极大简化了研究者的开发和对比工作。未来,随着多模态和大型模型在自动驾驶中的兴起,UniOcc 统一的占位–图像数据为训练和评估多模态 / 语言模型奠定了基础。期待基于 UniOcc 的数据和工具,能够涌现出更多创新算法,加速语义占位预测技术向前发展。


