小红书

让模型自己找关键帧、视觉线索,小红书Video-Thinker破解视频推理困局
随着多模态大语言模型(MLLM)的飞速发展,“Thinking with Images” 范式已在图像理解和推理任务上取得了革命性突破 —— 模型不再是被动接收视觉信息,而是学会了主动定位与思考。 然而,当面对包含复杂时序依赖与动态叙事的视频推理任务时,这一能力尚未得到有效延伸。 现有的视频推理方法往往受限于对外部工具的依赖或预设的提示词策略,难以让模型内生出对时间序列的自主导航与深度理解能力,导致模型在处理长视频或复杂逻辑时显得捉襟见肘。
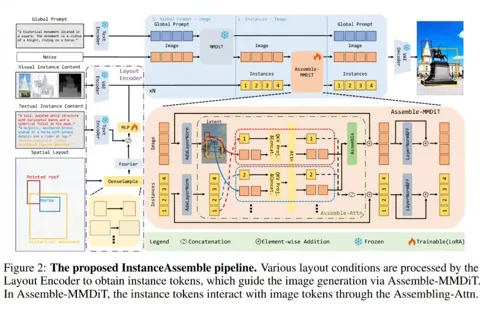
小红书联合复旦开源 InstanceAssemble:实现 AI 图像精准排版控制
近日,小红书与复旦大学联合发布了在布局控制生成(Layout-to-Image)领域的最新研究成果——InstanceAssemble。 这项技术旨在解决 AI 绘画中长期存在的“构图难”问题,通过创新的机制实现了从简单到复杂场景的精准图像生成。 据悉,相关论文已被人工智能顶级会议 NeurIPS2025收录。

小红书开源 InstanceAssemble:让 AI 精准还原复杂图像排版
AI在线 12 月 26 日消息,小红书携手复旦大学,联合推出布局控制生成(Layout-to-Image)领域的突破性方案 InstanceAssemble,通过创新“实例组装注意力”机制,实现了从简单到复杂、稀疏到密集布局的精准图像生成,相关成果已被 NeurIPS 2025 收录。 AI 绘画技术近年来快速发展,从最初的“文字生成图像”(Text-to-Image)逐步迈向“布局控制生成”(Layout-to-Image),后者会根据用户给定的空间布局约束(如边界框 Bounding Boxes、分割掩码 Masks 或骨架图)生成与之对应的图像。 “布局控制生成”技术的难点之一,就是如何让 AI 精确按照用户指定的位置和内容生成图像,面临布局对齐不准、语义脱节或计算成本过高的问题。

日更小红书想破头?用这个偷懒工作流,10 分钟搞定一周存货!
大家好,我是陌晨,分享有用的 AI 知识与工具,喜欢记得关注。 往期教程:大家看小红书,经常会刷到类似「每日一个养生知识、每日拆解一个 xxx、或是 xx 企业的发展史...」等类似的图文笔记。 基本上,此类都可以使用该方法实现批量化制作,实现日更。

NIPS2025|小红书智创AIGC团队提出布局控制生成新算法InstanceAssemble
当下的文本生成图像扩散模型取得了长足进展,为图像生成引入布局控制(Layout-to-Image, L2I)成为可能。 然而,现有布局到图像生成方法在复杂场景下表现仍不理想:一方面,如何精确对齐给定布局并同时保持高画质是巨大挑战;另一方面,在扩散生成的逐步去噪过程中确保每个目标的位置与语义属性不偏离也极为困难。 此外,布局控制往往需要支持多模态条件(如文本、参考图等信息),这进一步增加了技术复杂度。

小红书RecSys 2025最佳论文提名背后:破解视频时长预测难题
最近,一则趣闻在社交媒体上流传:当诺贝尔奖委员会还在费力寻找新晋生理学或医学奖得主时,一位小红书网友似乎早已在美国落基山脉与他偶遇并聊了天。 这件「让世界先一步找到你」的轶事,再次让人们将目光投向了小红书。 这真是一个总能创造神奇连接的社区!
小红书发布FireRedChat:首个可私有化部署的全双工大模型语音交互系统
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。 彻底开源、可私域落地,打造真正 “知冷暖、能共情、懂表达” 的语音 AI。 小红书智创音频团队发布 FireRedChat—— 业内首个支持私有化部署的全双工大模型语音交互系统,直击延迟高、噪声敏感、可控性差、依赖外部 API 等痛点。

一套万能提示词,教你生成刷爆小红书的「梗图游戏」
话说,你真觉得,人类比 AI 更会玩梗、搞抽象吗? 先别急着回答。 来玩一组「看图猜谜」的游戏,看你能猜出几个:你猜出来了几个?

小红书智创音频技术团队:SOTA对话生成模型FireRedTTS-2来了,轻松做出AI播客!
小红书智创音频技术团队近日发布新一代对话合成模型 FireRedTTS-2。 该模型聚焦现有方案的痛点:灵活性差、发音错误多、说话人切换不稳、韵律不自然等问题,通过升级离散语音编码器与文本语音合成模型全面优化合成效果。 在多项主客观测评中,FireRedTTS-2 均达到行业领先水平,为多说话人对话合成提供了更优解决方案。

ACM MM 2025 | 小红书AIGC团队提出风格迁移加速新算法STD
基于一致性模型(Consistency Models, CMs)的轨迹蒸馏(Trajectory Distillation)为加速扩散模型提供了一个有效框架,通过减少推理步骤来提升效率。 然而,现有的一致性模型在风格化任务中会削弱风格相似性,并损害美学质量 —— 尤其是在处理从部分加噪输入开始去噪的图像到图像(image-to-image)或视频到视频(video-to-video)变换任务时问题尤为明显。 这一核心问题源于当前方法要求学生模型的概率流常微分方程(PF-ODE)轨迹在初始步骤与其不完美的教师模型对齐。

小红书发布DynamicFace人脸生成技术,实现高质量图像视频人脸融合
小红书AIGC团队近日正式发布了名为DynamicFace的可控人脸生成技术。 据官方介绍,这项技术专门针对图像和视频领域的人脸融合任务进行优化,能够实现高质量与高度一致性的人脸置换效果。 DynamicFace技术的推出标志着小红书在AI内容生成领域的重要技术突破。

ICCV 2025 | 小红书AIGC团队提出图像和视频换脸新算法DynamicFace
本论文主要作者来自小红书 AIGC 团队(Dynamic-X-Lab),Dynamic‑X‑LAB 是一个专注于 AIGC 领域的研究团队,致力于推动姿态驱动的人像生成与视频动画技术。 他们以高质量、高可控性的生成模型为核心,围绕文生图(t2i)、图像生成(i2i)、图像转视频(i2v)和风格迁移加速等方向展开研究,并通过完整的开源方案分享给开发者与研究者社区。 论文标题:DynamicFace: High-Quality and Consistent Face Swapping for Image and Video using Composable 3D Facial Priors论文链接::,扩散模型在图像与视频合成领域展现出前所未有的生成能力,为人脸生成与编辑技术按下了加速键。

刚刚,小红书开源了多模态大模型dots.vlm1,性能直追SOTA!
最近的AI圈只能说是神仙打架,太卷了。 OpenAI终于发了开源模型,Claude从Opus 4升级到4.1,谷歌推出生成游戏世界的Genie 3引发社区热议。 国产模型这边,就在前几天,HuggingFace上排在最前面的10个开源模型还都来自国内。
小红书提出首个社交大模型:八大社交任务平均提升14.02%
大模型也能“通人情”? 行业首个社交大模型全景解析:既能兼顾社交理解与平台规则,又能洞察理解用户。 小红书重磅推出RedOne——一款面向SNS(社交网络服务)领域的定制化LLM,旨在突破单一任务基线模型的性能瓶颈,并且构建全面覆盖SNS任务的基座模型。

万字干货:小红书 hi lab 团队关于奖励模型的一些探索
奖励模型(Reward Models,RM)在确保大语言模型(LLMs)遵循人类偏好方面发挥着关键作用。 这类模型通过学习人类的偏好判断,为语言模型的训练提供重要的引导信号。 奖励模型很多科学问题都充满挑战,小红书 hi lab团队过去一段时间对下列几个问题和关键挑战进行了一些探索:奖励模型应该如何评估?

上海市委网信办指导小红书、B站、拼多多等平台清理违规 AI 产品及信息
上海市委网信办指导小红书、哔哩哔哩、拼多多等 15 家重点网站平台,集中清理“一键脱衣”、未经授权的人脸或人声克隆编辑、未备案等违规 AI 产品、商品及相关营销、炒作、推广、教程信息。小红书、哔哩哔哩主动发布专项行动治理公告,开通了有害 AI 内容的举报受理处置渠道;星野开展智能体全面排查清理。各重点网站和 AI 平台共拦截清理相关违法违规信息 82 万余条,处置违规账号 1400 余个,下线违规智能体 2700 余个。经整治,网络违规 AI 信息显著减少。

小红书重磅出击!全新开源大模型 “dots.llm1” 震撼登场,参数量达 1420 亿!
近日,小红书的 hi lab 团队正式推出了其首个开源文本大模型 ——dots.llm1。 这一新模型以其卓越的性能和庞大的参数量引起了业界的广泛关注。 dots.llm1是一款大规模的混合专家(MoE)语言模型,拥有惊人的1420亿个参数,其中激活参数达到140亿。

小红书Hi Lab提出DeepEyes,探索O3「Thinking with Images」能力
OpenAI 的 o3 首次将图像直接注入推理过程,打破了传统文字思维链的边界,成为多模态推理新的里程碑。 但是如何赋予模型这一能力,目前不得而知。 因此,小红书联合西安交通大学,采用端到端强化学习,在完全不依赖监督微调(SFT)的前提下,激发了大模型“以图深思”的潜能,构建出多模态深度思考模型 DeepEyes,首次实现了与 o3 类似的用图像进行思考的能力,并已同步开源相关技术细节,让“用图像思考”不再是 OpenAI 专属。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉