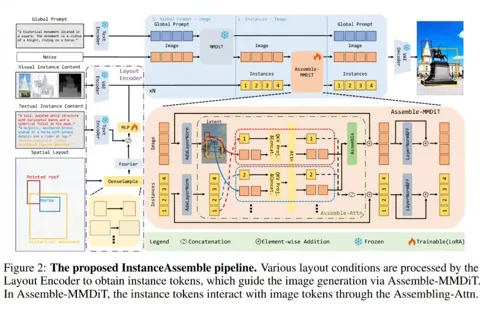
当下的文本生成图像扩散模型取得了长足进展,为图像生成引入布局控制(Layout-to-Image, L2I)成为可能。
然而,现有布局到图像生成方法在复杂场景下表现仍不理想:一方面,如何精确对齐给定布局并同时保持高画质是巨大挑战;另一方面,在扩散生成的逐步去噪过程中确保每个目标的位置与语义属性不偏离也极为困难。此外,布局控制往往需要支持多模态条件(如文本、参考图等信息),这进一步增加了技术复杂度。
现有方案各有不足:无训练方法虽然无需改动基础模型,但在复杂布局下效果显著下降,且对超参数敏感、推理速度慢;有训练方法通过额外模块注入布局信息,但往往引入海量参数,训练代价高昂。评估方面,传统指标也存在偏差,难以准确衡量布局对齐程度。
这些挑战和不足表明,实现稳健且高效的布局可控图像生成亟需新的算法创新。
为此,小红书智能创作 AIGC 团队提出了 InstanceAssemble 框架,从架构和评测上全面应对上述难题,实现了在复杂布局条件下的精确图像生成。


论文链接:https://arxiv.org/abs/2509.16691
项目主页:https://github.com/FireRedTeam/InstanceAssemble
方法
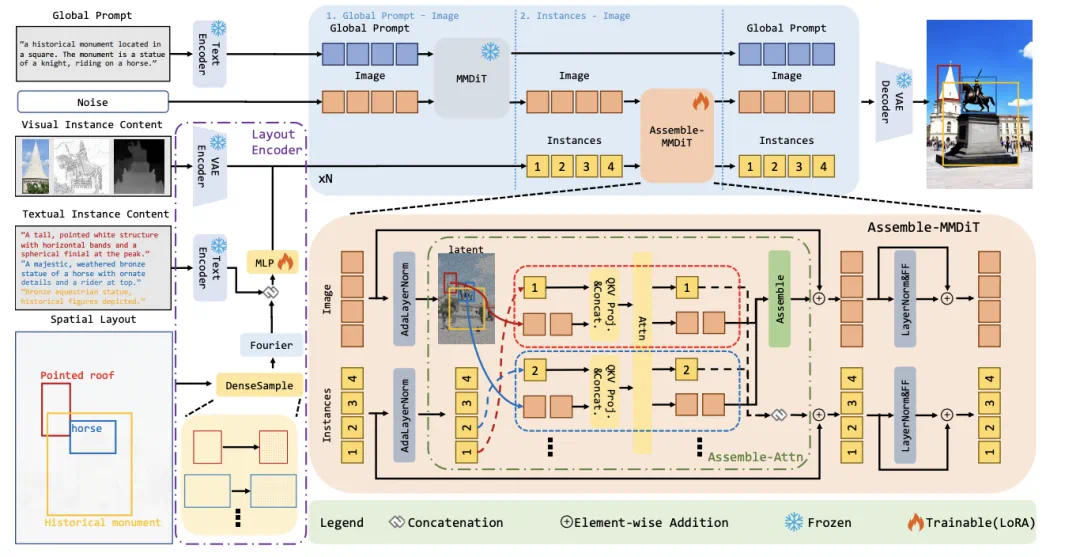
InstanceAssemble 方法在架构上引入了级联结构,将全局文本提示与实例级布局条件分阶段处理。
具体而言,模型先利用原有 DiT 获取全局图像背景和整体语境,再通过新设计的实例组装注意力模块(Assemble-Attn)逐个整合各布局实例信息,实现局部精细控制。这样的级联架构确保了全局质量与局部对齐两方面的兼顾,避免了同时处理所有实例可能产生的冲突。在实例组装注意力中,每个目标实例的注意力计算仅在其对应图像区域内进行,避免不同实例间互相干扰。
这种独立注意力机制使模型能够有效处理重叠或小物体等复杂布局情形,同时通过权重融合各实例特征,保持画面整体协调。
此外,InstanceAssemble 使用 LoRA 模块进行轻量级模型适配。通过在基础扩散模型中注入少量 LoRA 参数(仅增加基础模型的 3% 的参数量左右),实现了对现有 DiT-based 文本生成图像模型的灵活扩展。LoRA 的加入使模型在保留原有生成能力的同时,能够高效地学习布局控制,不需要大规模重训整个模型,并具备良好的兼容性(例如可方便地加载不同风格的 LoRA 权重)。
最后,该方法还支持多模态的布局输入:每个实例既可由文本描述指定,也能利用额外的图像信息(如参考图片、深度图、边缘图等)来丰富内容表示。
效果与对比
为了全面评估模型在复杂布局下的表现,作者构建了全新的基准数据集 DenseLayout,包含 5000 张图像和约 90000 个实例(平均每图 18 个目标),专门用于测试在高密度布局场景下的生成效果。同时提出了 LGS (Layout Grounding Score) 作为评测新指标,将空间精度和语义一致性相结合,更准确地衡量生成图像对布局指令的满足程度。其中空间精度通过检测目标位置与给定边界框的 IoU 计算得到,语义一致性则利用视觉问答模型判断颜色、材质、形状等属性匹配度。
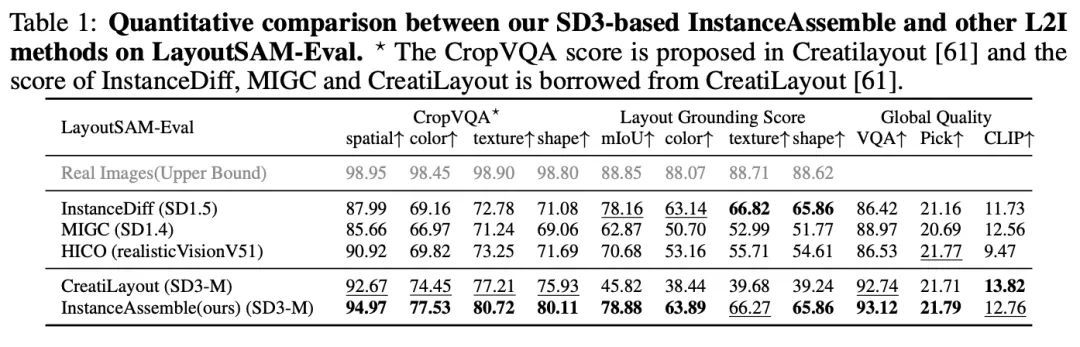
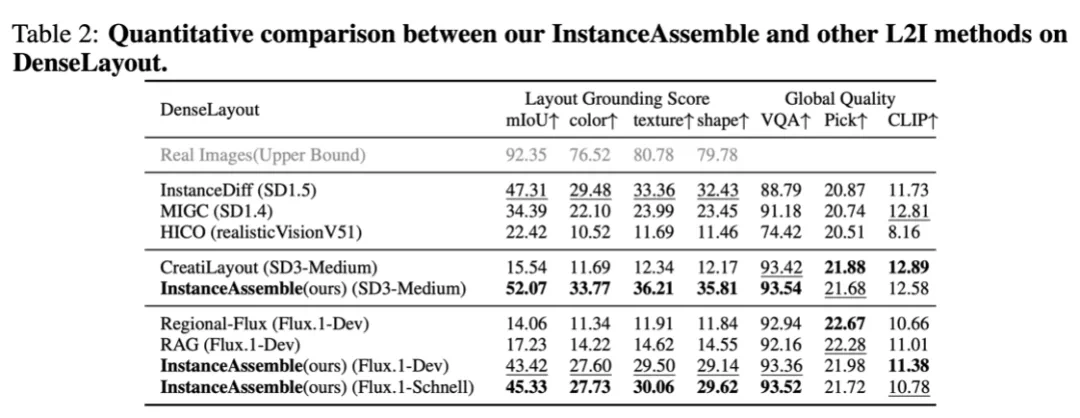
在上述严苛评测下,InstanceAssemble 展现了卓越的性能。实验结果表明,该方法在 DenseLayout 基准上的布局对齐指标 (mIoU) 显著优于现有方法,综合的 LGS 分数处于当前最优水平,同时全局图像质量保持良好。特别是在稠密布局场景下(远超训练时≤10 个实例的密度),InstanceAssemble 依然能够精确地将每个目标生成在指定位置,并正确呈现其语义属性,验证了模型的强泛化能力。
而对比方法在相同条件下往往出现漏生成、位置紊乱或风格不一致的问题,定性结果同样佐证了这一点。
此外,得益于 LoRA 轻量架构,InstanceAssemble 相较其他有训练方法在参数开销和推理耗时上更具优势,在效率与效果之间取得了良好平衡。

应用
InstanceAssemble 的设计在兼顾性能的同时,非常注重兼容扩展性。由于采用 LoRA 作为插件式适配,研究者和从业者可以方便地为模型引入不同风格迁移能力。例如,将经过特定画风微调的 LoRA 模块(如油画风格、3d 风格等)加载到 InstanceAssemble 中,模型即可在保持布局精准对齐的前提下,生成带有对应风格的图像。
这种对多种风格 LoRA 的高兼容性使得模型能够跨越不同域,进行跨风格、跨领域的布局图像创作。

综上所述,InstanceAssemble 通过其独特的架构和模块设计,实现了精细布局控制与高质量生成的有机结合,不仅在学术基准上取得领先表现,也展现出广阔的应用潜力。未来,随着更多样的 LoRA 模块和多模态信息融入,InstanceAssemble 可进一步拓展至智能排版、虚拟内容创作、数据增强等诸多领域,推动布局图像生成的发展和落地应用。
最后,小红书智能创作团队正在火热招人中!小红书智能创作团队以 AI 及多媒体技术为核心,主要负责小红书发布侧的产品研发,并向公司内部各业务线(社区守护、社交、直播、电商、商业化广告)提供业界领先的内容创作、内容理解、互动体验等技术能力及解决方案。团队技术方向涵盖多模态 AIGC 、计算机视觉、语言语音、编辑渲染、算法工程等。
本篇工作着手于图像可控生成,主要应用在小红书文字发布等功能的图像素材生产中。
团队最近两年累积发表了 30 余篇相关领域顶会 or 顶刊论文,在技术上有 InstantID、Storymaker、FireRedTTS、FireRedASR 等知名技术开源代表作,在业务上也做出了语音评论、文字功能等爆款功能。
长期欢迎优秀校招、社招、实习生的加入,Let‘s work together!有意向的同学请联系 [email protected]