奖励模型(Reward Models,RM)在确保大语言模型(LLMs)遵循人类偏好方面发挥着关键作用。这类模型通过学习人类的偏好判断,为语言模型的训练提供重要的引导信号。
奖励模型很多科学问题都充满挑战,小红书 hi lab团队过去一段时间对下列几个问题和关键挑战进行了一些探索:
- 奖励模型应该如何评估?如何获取效果、robustness都足够好的reward model ?(ICLR 2025 Spotlight)
- 如何构建可泛化的多模态RM?解决多模态RM倾向于学习纯文本捷径的问题。(ICML 2025)
- 如何面向中文场景构建大规模、高质量的中文偏好数据集和评测基准?(ACL 2025)
- 偏好预训练提升LLM推理偏好能力的可扩展方法;如何构建自我批评的生成式奖励模型提升大语言模型推理能力?(ACL 2025 Findings)
- Self Rewarding方式构建自评估框架让大语言模型主动探索知识边界并自我纠正幻觉行为。(ACL 2025 Findings)
01、Reward Model 应该如何评估?
论文标题:
Rethinking Reward Model Evaluation: Are We Barking up the Wrong Tree?
论文地址:
https://arxiv.org/abs/2410.05584
收录情况:
ICLR 2025 Spotlight
1.1 问题背景
在RLHF框架中,奖励模型(Reward Model,RM)通过学习人类偏好判断来为模型优化提供关键的引导信号,对确保模型行为符合人类期望起着至关重要的作用。然而,构建一个能够完全捕捉人类偏好的奖励模型是极具挑战性的。由于人类偏好的复杂性和多样性,奖励模型往往只能作为理想偏好的不完美代理。这种不完美性可能导致模型在针对奖励模型优化时出现过度优化问题,即模型可能会过分迎合奖励模型的偏差而偏离真实的人类偏好,这种现象可以被视为 Goodhart's law 在强化学习中的体现。
鉴于奖励模型的不完美性难以完全避免,准确评估奖励模型的质量以预测其在实际应用中可能造成的负面影响就显得尤为重要。目前,业界主要采用两种评估方法:一是直接评估优化后的策略表现,二是计算模型在固定数据集上的准确率。前者虽然能够反映最终效果,但难以区分性能问题是源于策略优化过程还是奖励学习过程;后者则存在评估指标是否能准确预测优化后策略表现的问题。因此,我们需要更加深入的关注这些问题:
(1)如何更好地评估奖励模型?
(2)准确率指标与下游策略性能之间存在怎样的关系?
(3)我们能否建立更有效的评估方法来预测和防范模型过度优化的风险?
1.2 实验设置

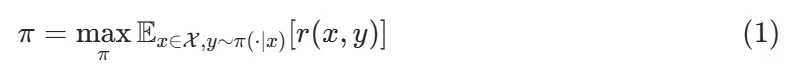
RLHF工作流程为:(1)在偏好数据集上训练代理奖励模型;(2)评估代理奖励模型与目标函数的误差;(3)基于代理奖励模型优化策略;(4)在测试集上评估策略效果。


1.3 实验结果
1)准确率与策略损失的相关性分析
目前研究普遍通过在固定测试集上计算准确率来评估奖励模型误差。我们的实验结果揭示了:奖励模型的评估准确率与策略损失之间存在正相关关系,但即使具有相似准确率的模型,其优化得到的策略也可能表现出显著不同的损失水平。通过计算准确率与NDR之间的相关性,我们发现准确率与策略损失确实存在正向关联,但在相似准确率范围内,策略损失可能出现较大波动。值得注意的是,在Best-of-N采样方法中,准确率与策略损失的相关性普遍强于PPO算法,这符合预期,因为BoN是更局部化且稳定的优化算法。
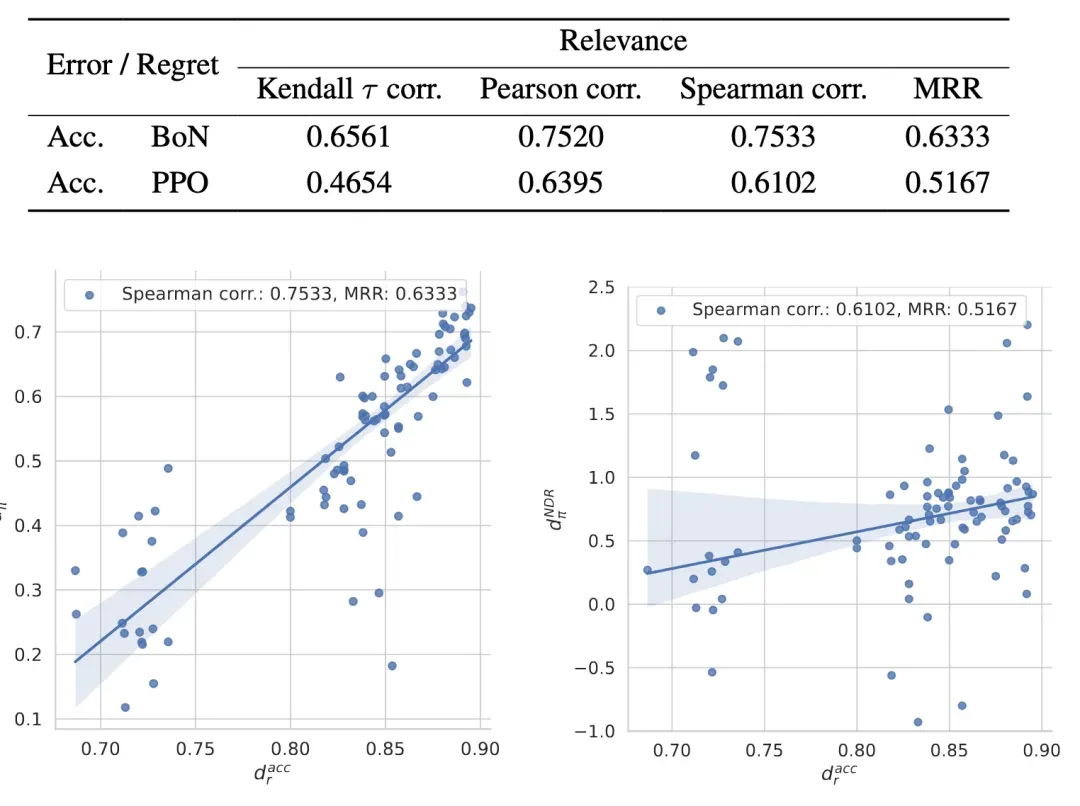
2)提升准确率预测能力的优化策略
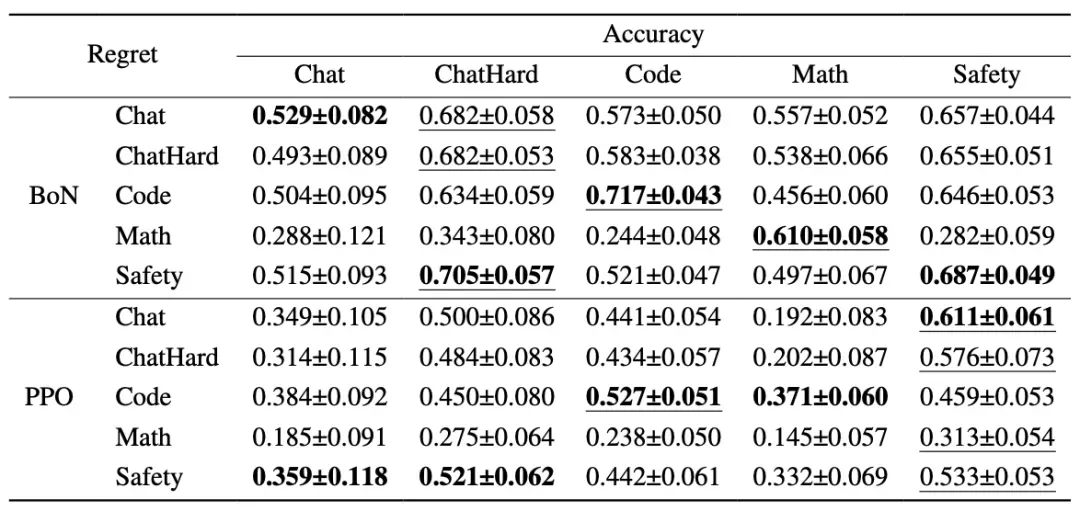
回复分布的影响 我们构建了仅包含来自单一下游模型回复的测试数据集。发现回复的质量排序对相关性的影响比采样模型更显著。进一步分析不同质量区间的回复发现:BoN中,选用中等质量区间(排名5-10)正例和较低质量区间(排名15-20)负例能获得更高相关性;PPO中,高质量区间(排名1-5)正例和中等质量区间(排名10-15)负例组合效果更好。
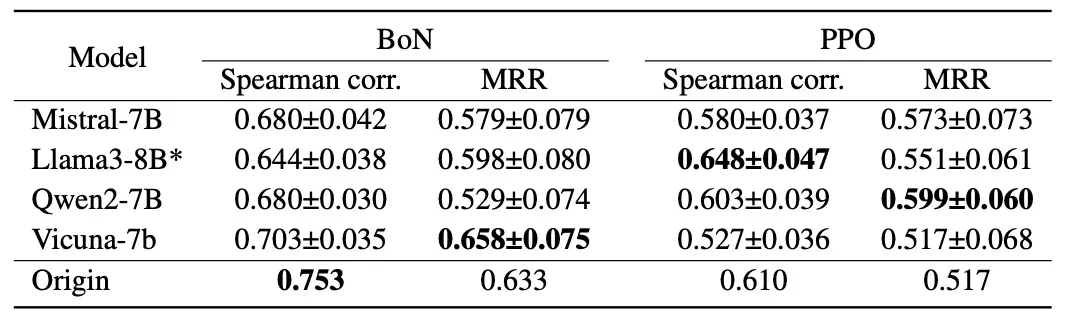
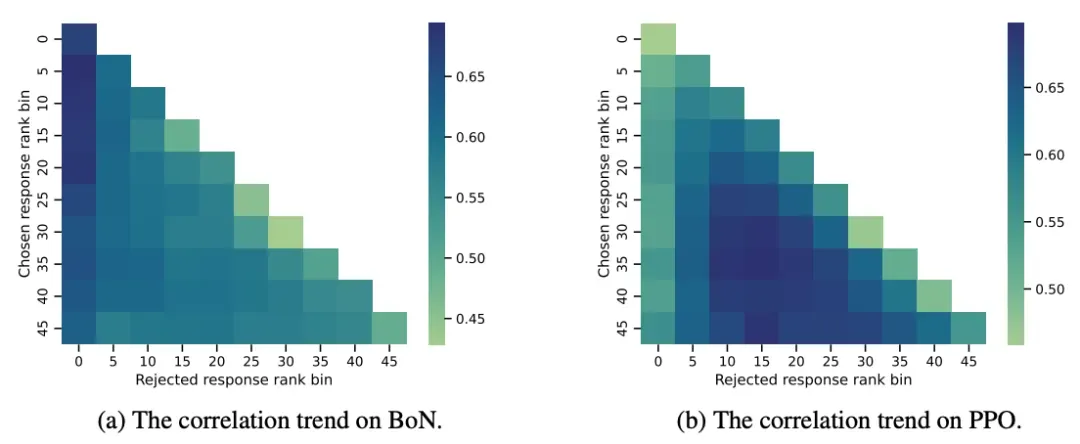
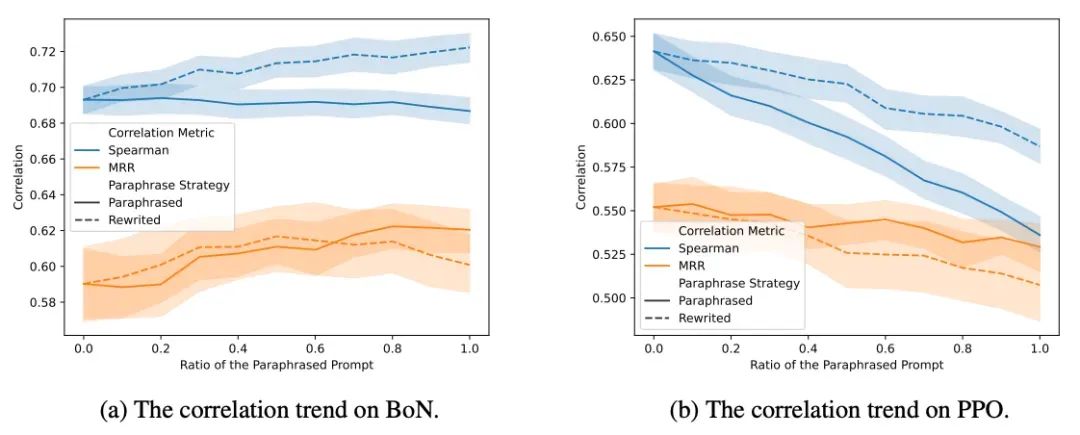
提示分布的影响 通过RewardBench原有分类构建不同类别测试集,发现BoN设置下各类别的准确率与对应类别策略损失相关性更强。例如,Code类别相关性达到0.717。PPO设置中这种对应关系不明显。使用不同改写策略探索提示语义影响发现,BoN对提示表达变化敏感度较低,而PPO随改写比例增加相关性持续下降。
优化策略的探索 为提升准确率的预测能力,我们首先探索了增加每个提示的回复数量(从2个增加到5个)的策略,并评估了不同评估指标的效果。实验结果表明,在包含更多回复的数据集上,各类指标普遍实现了更高的相关性。其中相关系数表现最突出,在BoN和PPO设置下分别达到0.677和0.688。
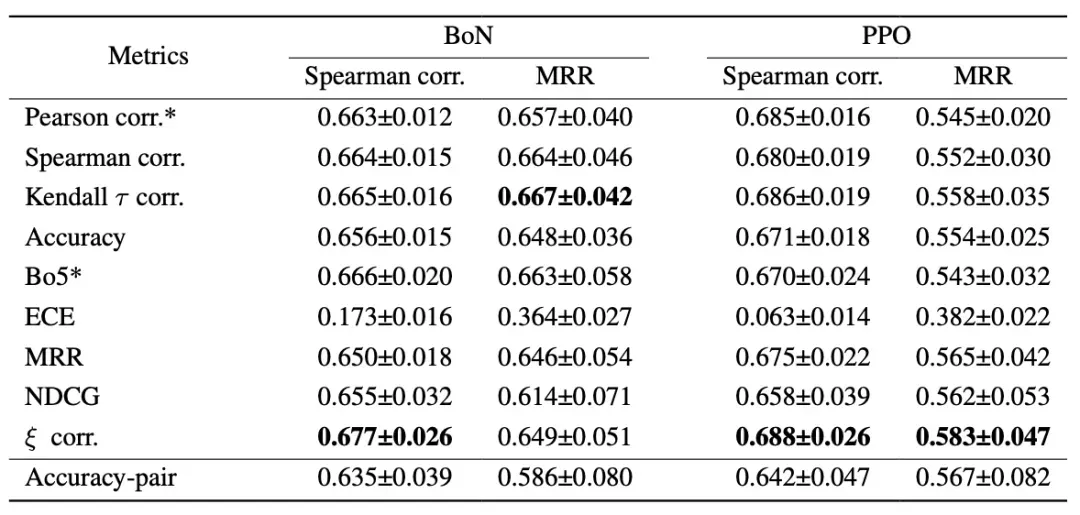
我们进一步在不同约束条件下验证这一策略:
- 在固定样本量情况下,增加回复数量比增加提示数量更有效,当样本量较小时每个提示收集3-4个回复可获得最佳性价比。
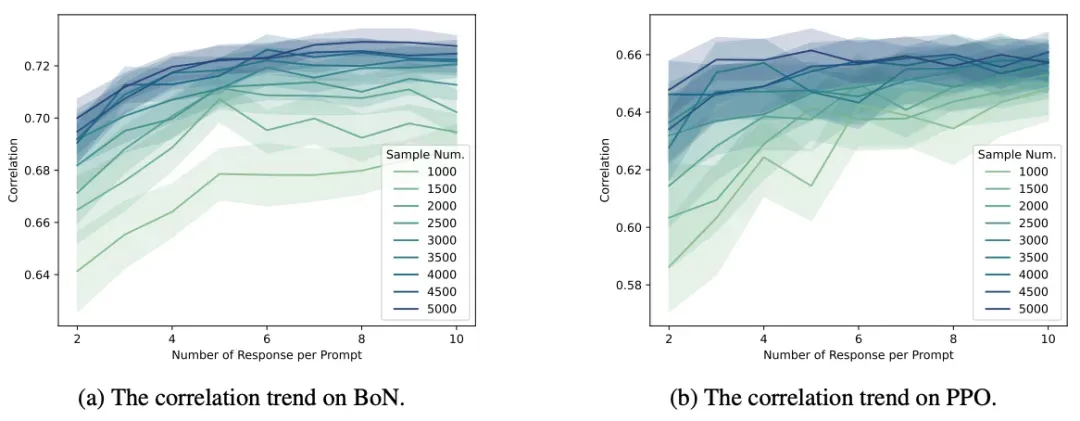
- 考虑标注成本时,BoN设置下增加回复数量仍有优势但收益递减,而PPO设置下收益不显著,这为实际应用中的数据收集策略提供了重要的成本效益参考。
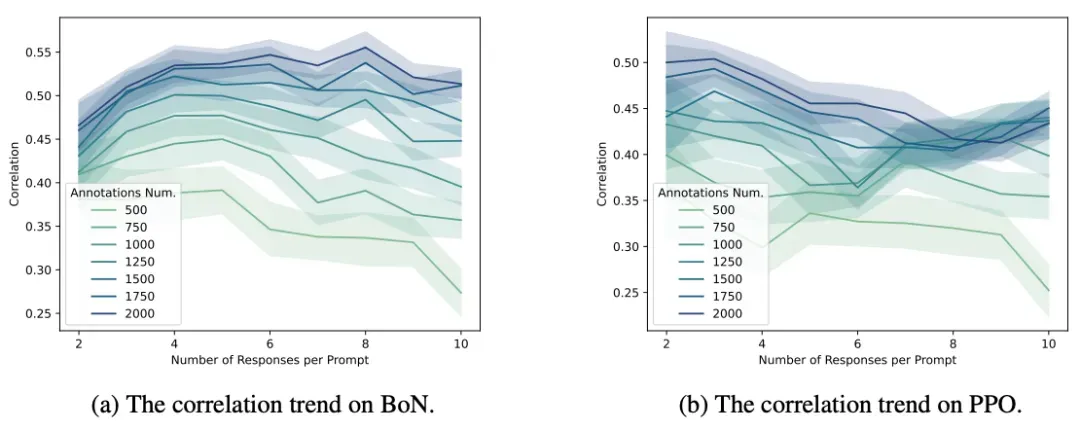
3)奖励模型误差与策略损失的关系

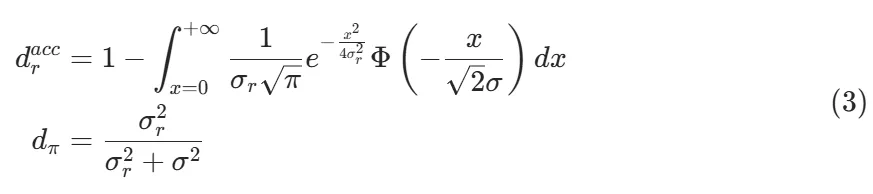

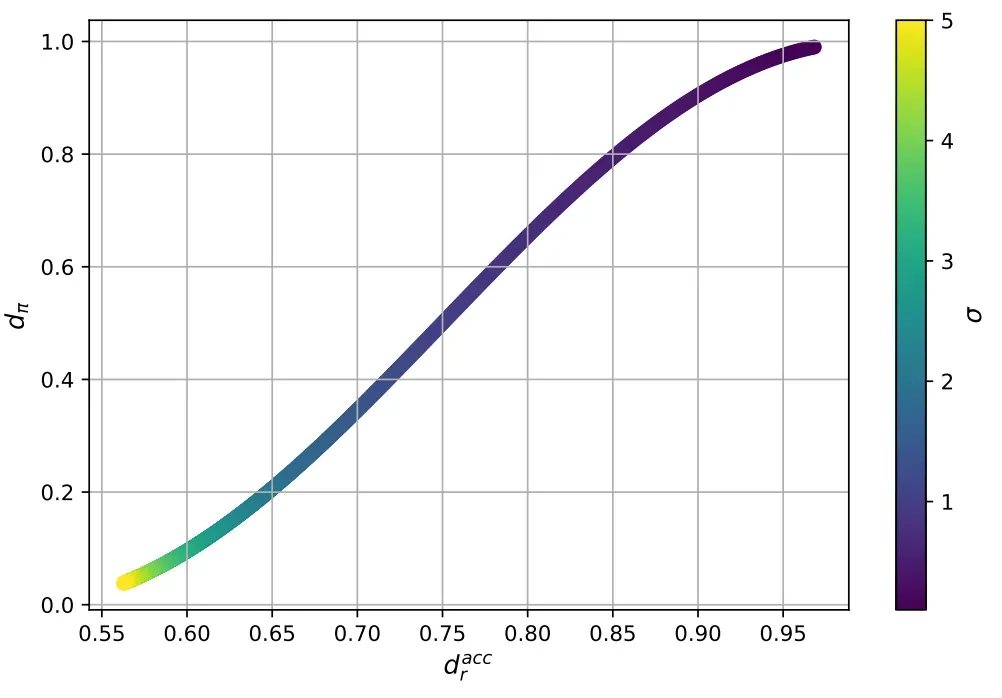
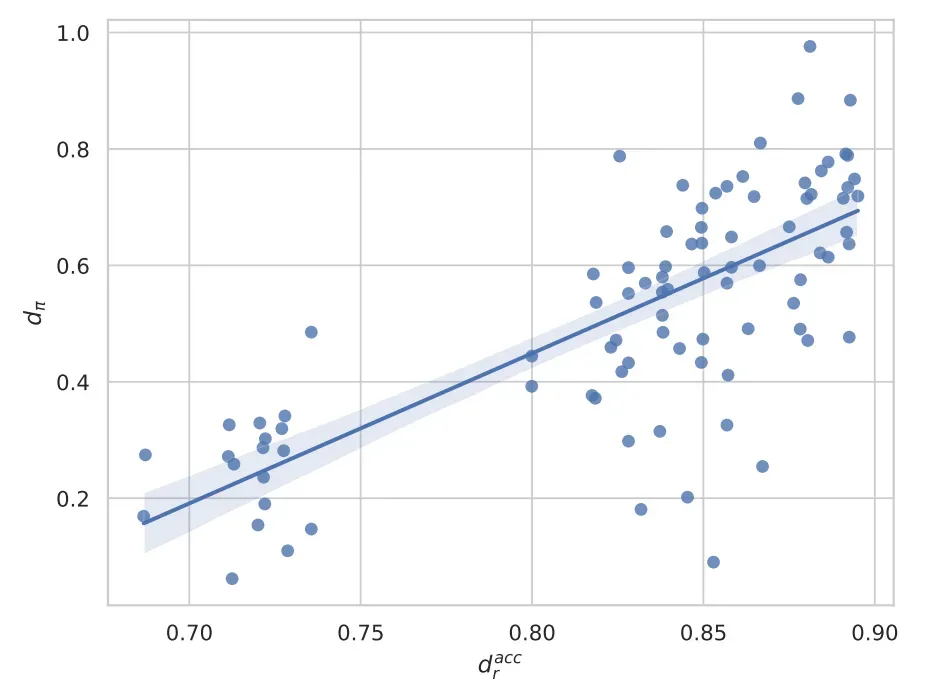
通过分析不同奖励模型组合的优化动态,我们发现即使具有相似准确率的模型对也可能表现出不同的过度优化现象,这表明仅依靠准确率可能无法充分预测潜在的过度优化风险,需要开发更全面的评估框架。
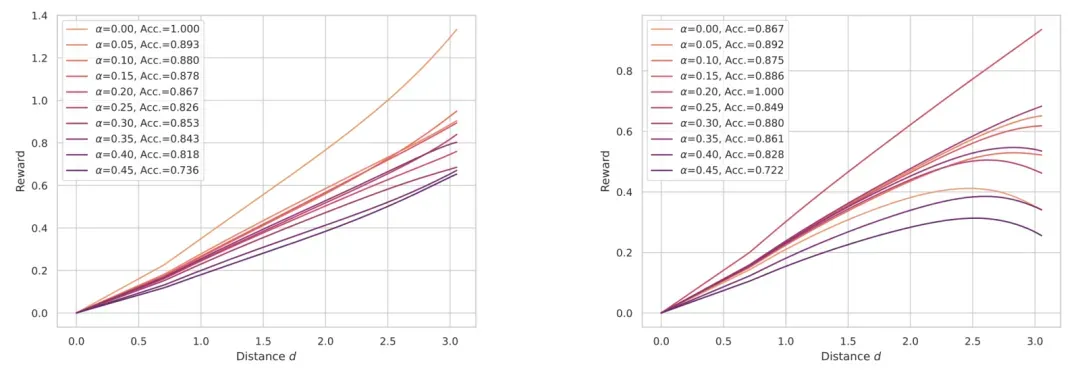
1.4 总结
研究发现,虽然奖励模型的准确率与策略性能存在弱正相关关系,但具有相似准确率的奖励模型可能产生表现差异显著的策略,这表明单一准确率指标无法完整反映奖励模型的实际效果。进一步研究表明,准确率的度量方式会显著影响其对策略性能的预测能力。更重要的是,我们发现仅依靠准确率指标难以充分反映奖励模型可能存在的过度优化现象。基于以上发现,我们建议在评估奖励模型性能时采取更谨慎的态度,不应过分依赖准确率这一单一指标。同时,我们的研究凸显了开发更全面、更可靠的奖励模型评估方法的重要性,这对提升大语言模型的对齐效果具有重要意义。
02、构建可泛化的多模态RM
论文标题:
The Devil Is in the Details: Tackling Unimodal Spurious Correlations for Generalizable Multimodal Reward Models
论文地址:
https://arxiv.org/abs/2503.03122
收录情况:
ICML 2025
2.1 问题背景
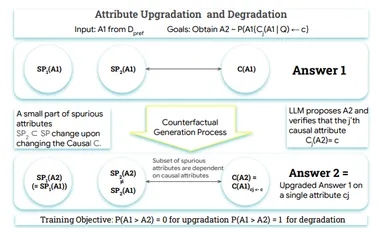
随着 LLMs 越来越多地以多模态的方式感知世界,例如处理图像、文本和语音等多种类型的数据,多模态奖励模型(Multimodal Reward Models, MM-RMs)应运而生,成为解决多模态任务中对齐问题的重要工具。尽管多模态奖励模型在捕捉人类偏好上具有关键意义,关于其泛化能力的研究却仍然处于空白。泛化能力是指模型在未见过的数据上保持性能的能力,这对于 MM-RMs 的实用性至关重要。如果一个 MM-RM 在训练数据上表现良好,但在分布外(o.o.d.)数据上无法泛化,那么它可能会导致模型在实际应用中产生与人类意图不一致的输出,甚至出现奖励黑客(Reward Hacking)的问题。因此,理解与提高 MM-RMs 的泛化能力对确保其在现实世界中的鲁棒性而言至关重要。
我们发现了一个值得关注的现象:现有的 MM-RMs 在多模态数据的训练过程中往往会过度依赖单模态的虚假关联(Unimodal Spurious Correlations)。具体来说,这些模型倾向于学习纯文本捷径(Text-only Shortcuts),而忽视了视觉或其他模态的信息。这种现象在训练数据中可能表现良好,但在分布外数据上则会失效,从而严重影响多模态奖励模型的泛化能力。这一现象促使我们思考:如何衡量 MM-RMs 的泛化性能,并且量化单模态虚假关联对其泛化表现的影响?我们能否建立更加有效的多模态奖励模型构建方法,从而缓解 MM-RMs 中的单模态虚假关联,进而提升其泛化性能?在本研究中,我们系统性地探讨了上述问题,并提出了一种针对单模态虚假相关性的解决方案,构建了一个更具鲁棒性的多模态奖励建模框架。
2.2 泛化挑战

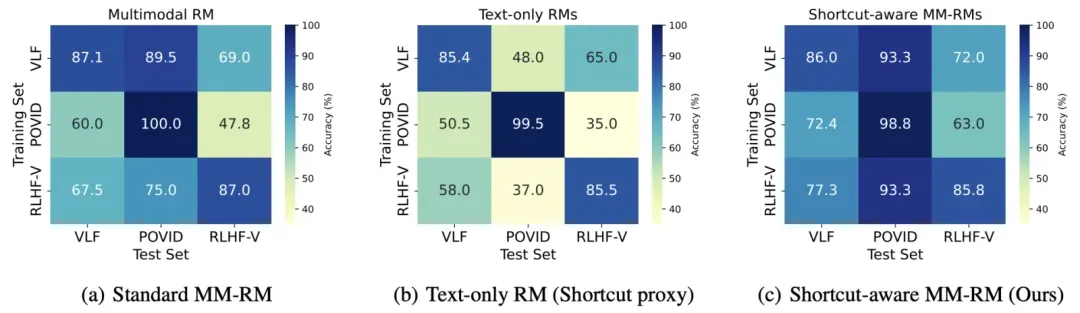
在明确了多模态奖励模型的泛化性能以后,我们进一步分析了纯文本捷径(Text-only Shortcuts)作为 MM-RMs 构建过程中一种不容忽视的虚假关联,并得出一系列洞察性的见解。首先,现有的多模态偏好数据集不可避免地存在纯文本捷径,这些捷径仅在其对应的分布中有效。具体来说,基于纯文本训练以及纯文本测试的设置,我们得出了纯文本奖励模型(Text-only RM)的泛化矩阵(如图1(b)所示)。与标准的多模态奖励模型相比,Text-only RM 在所有数据的 i.i.d. 场景下实现了相当的准确率,然而却在 o.o.d. 场景下严重失效。其次,即使在多模态偏好环境中进行训练,MM-RMs 仍然会利用单模态虚假关联。我们在训练和测试过程中交替使用多模态和纯文本模式,检查奖励模型在 i.i.d. 条件下的性能。我们发现即使在纯文本测试中,在多模态偏好数据上训练的模型仍然能够实现相当的 i.i.d. 性能,这表明它们所学到的相关性中存在纯文本捷径。
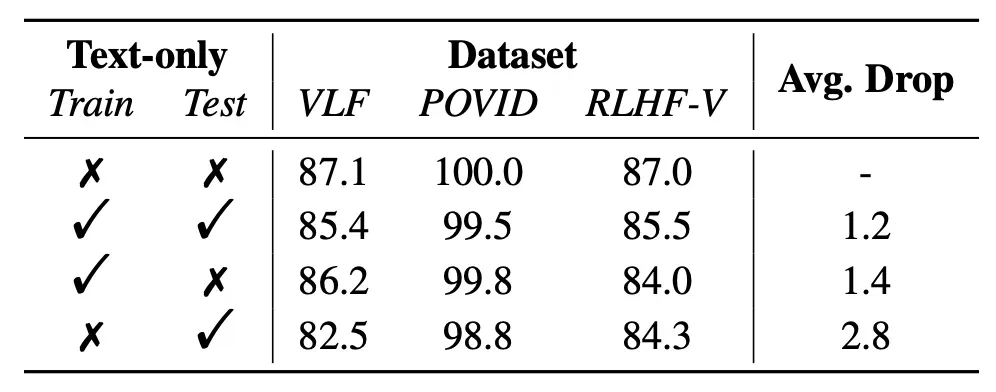
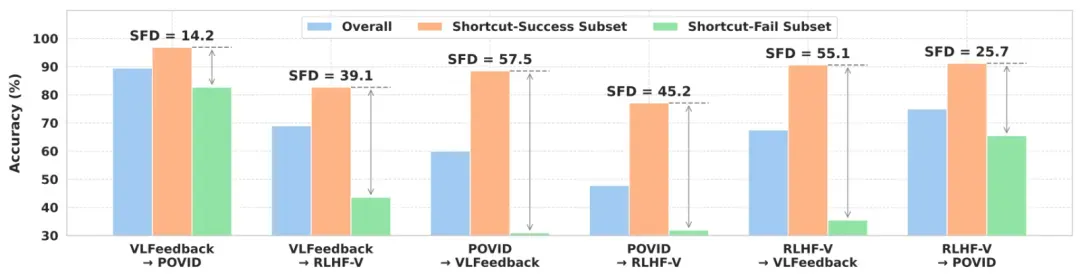
为了系统地检验纯文本捷径对 MM-RMs 泛化能力的影响,我们提出了捷径失效退化(Shortcut-Failure Degradation, SFD)指标,该指标量化了当单模态虚假相关性未能泛化到 o.o.d. 数据时 MM-RMs 的性能下降程度。我们观察到,MM-RMs 的泛化能力受到单模态虚假相关性的严重限制。具体来说,在不同的分布外情景中,MM-RMs 的 SFD 值范围从 14.2 到 57.5,平均值为 39.5。这表明 MM-RMs 的奖励过程主要受纯文本捷径的支配,当这些捷径未能泛化到 o.o.d. 数据时,尤其是在需要真正多模态理解的情景中,模型表现出显著的性能下降。
2.3 方法介绍
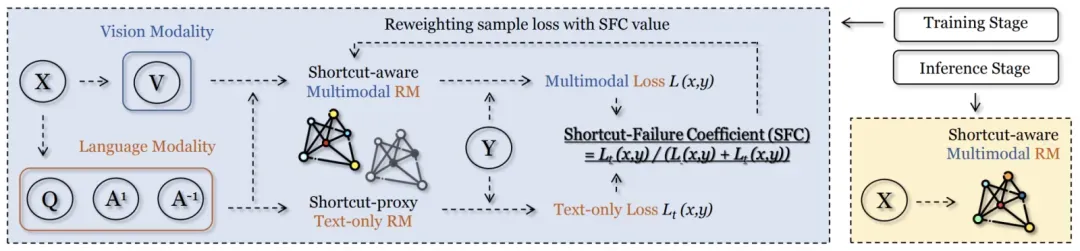
基于对单模态虚假关联的洞察,我们提出了一种更加鲁棒的多模态奖励模型学习算法,能够在任何有偏数据集上学习可泛化的 MM-RM。具体来说,该方法的核心在于识别并突出单模态捷径失效的场景,在此基础上实现训练分布的迁移。为了实现这一目标,我们在训练阶段提出了一个双分支架构。每个分支都使用相同初始化的奖励模型,但它们在模态处理上有所不同:主分支在标准的多模态偏好数据上进行训练,作为我们的捷径感知的多模态奖励模型(Shortcut-aware MM-RM);辅助分支则在移除了图像模态的偏好数据上进行训练,作为纯文本捷径的代理。为了量化并利用这两个分支之间的差异,我们引入了单模态虚假关联系数(Shortcut-Failure Coefficient, SFC)。该指标从样本层面衡量辅助分支(单模态捷径代理)对总训练目标损失的贡献比例,从而表明单模态虚假相关性在多大程度上未能捕捉完整的偏好模式。基于单模态虚假关联系数,我们将主分支的损失函数重新表述为捷径感知(shortcut-aware)的形式,其中 SFC 值仅作为加权系数。
本质上,该训练范式利用 SFC 值动态地重新加权训练分布中的样本:具有较高 SFC 值的样本表明纯文本分支难以建模偏好,这意味着多模态融合对于鲁棒学习至关重要,因此会获得更高的权重;相反,具有较低 SFC 值的样本表明纯文本分支可以轻松区分它们,从而获得较低的权重。我们将这种加权机制视为一种适应性方法,将训练数据分布转向那些多模态理解至关重要的环境。在完成捷径感知的模型训练后,我们可以简单地移除辅助分支,因为该分支仅在训练期间作为纯文本捷径的代理。在推理阶段,我们只需要部署主分支,这意味着推理过程与标准多模态奖励模型完全相同,没有任何额外开销。
2.4 实验结果
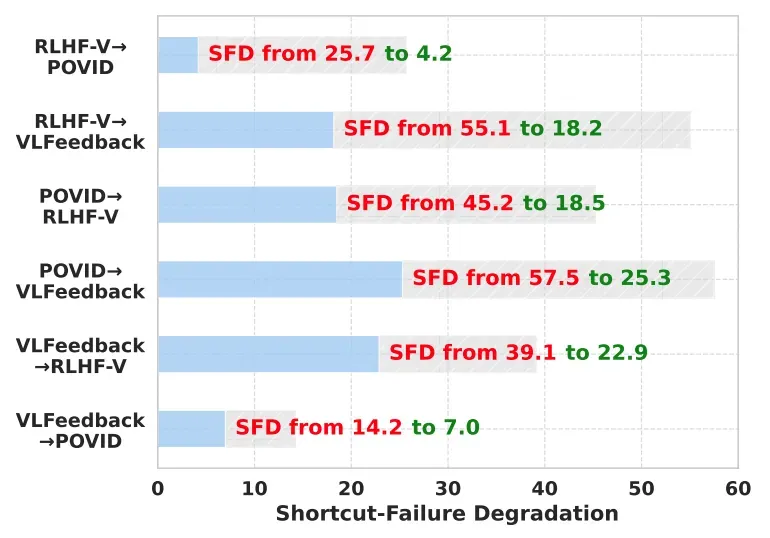
我们提出的捷径感知的多模态奖励模型(Shortcut-aware MM-RMs)在跨分布转移测试中取得泛化性能的显著提升,如图1(c)所示。与标准多模态奖励模型相比,Shortcut-aware MM-RMs 在六个 o.o.d. 场景下的平均准确率从 68.1 提高到 78.5。进一步地,我们分析了捷径失效退化指标的变化。Shortcut-aware MM-RMs 在所有 o.o.d. 场景中均展现出稳健的鲁棒性提升,与标准 MM-RMs 相比,SFD 值显著降低。这表明捷径感知模型较少依赖纯文本捷径进行奖励评分,并且在单模态虚假关联无法泛化的情景中能够做出更准确的判断。
我们进一步在下游任务中验证模型的真实性能,采用最佳候选选择(Best-of-N, BoN)策略。该过程涉及从 InternVL2-8B 为每对图像-查询生成 64 个候选回答,多个多模态奖励模型随后对这些候选回答进行评分,得分最高的回答被选中用于下游基准评估。Shortcut-aware MM-RMs 在所有基准测试中均展现出显著的 Best-of-64 性能提升,突显了该算法强大的泛化能力和实际应用价值。我们还发现,捷径感知的多模态奖励模型展现出了更好的可扩展性,在面对奖励过度优化(Reward Overoptimization)时具有更强的鲁棒性。
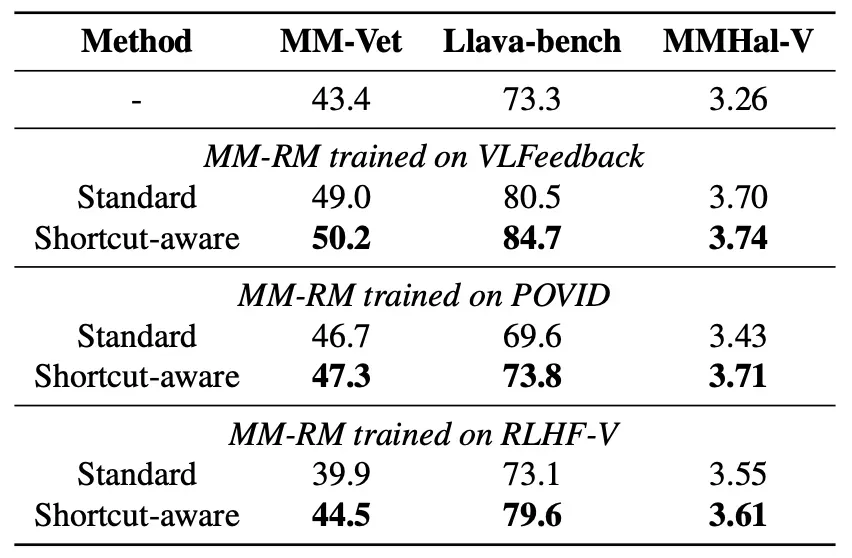
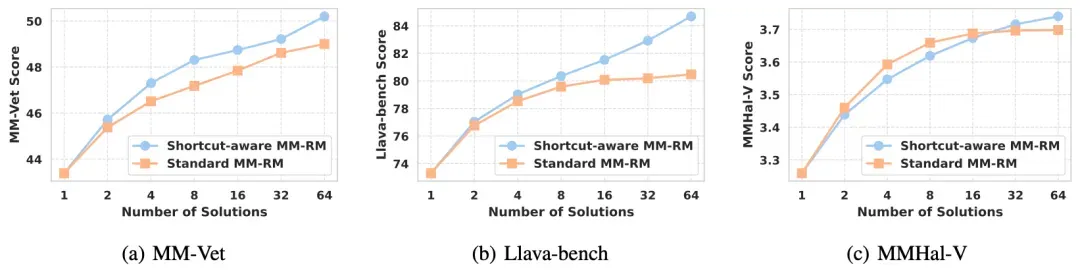
2.5 总结
本研究解决了多模态奖励模型(MM-RMs)面临的一个关键挑战:单模态虚假关联对其泛化能力的限制。我们的跨分布实验揭示了 MM-RMs 在同分布(i.i.d.)和分布外(o.o.d.)情景之间的显著性能差异。此外,我们发现即使在多模态训练环境中,MM-RMs 仍然能够利用多模态偏好数据集中存在的纯文本捷径,这对其泛化能力产生了负面影响。为了克服这一局限性,我们提出了一种捷径感知(Shortcut-aware)的多模态奖励模型学习算法,该算法通过动态识别并强调单模态捷径失效的样本,显著增强了它们的泛化能力和实际应用的有效性。
03、从零构建中文奖励模型
论文标题:
Cheems: A Practical Guidance for Building and Evaluating Chinese Reward Models from Scratch
论文地址:
https://arxiv.org/abs/2502.17173
收录情况:
ACL 2025 Main
3.1 问题背景
随着大语言模型快速发展,确保模型安全性、可靠性和价值观一致性成为关键挑战。模型可能产生有害内容、难以准确理解用户意图、在特定场景下表现不稳定。为应对这些挑战,奖励模型作为对齐优化的核心组件发挥关键作用,主要通过两种方式:一是在训练中提供奖励信号指导参数优化,通过RLHF过程调整模型行为;二是在生成阶段直接干预输出,确保内容符合人类期望。然而,中文奖励模型发展面临显著挑战。首先是数据缺乏,缺少大规模、高质量的中文偏好数据集和评测基准。其次是标注质量问题,现有模型主要依赖AI合成数据,存在不一致性,难以准确反映真实人类偏好和文化差异。为解决这些问题,我们构建了CheemsBench全人工标注的中文评测基准和CheemsPreference大规模中文偏好数据集。这两个数据集通过人工监督,能更准确地捕捉真实的人类价值观,为中文奖励模型发展提供重要支撑。
3.2 中文奖励模型基准测试
为了全面评估中文奖励模型的性能,我们构建了CheemsBench基准测试集。该基准具有两个主要特点:一是覆盖范围广,整合多样化的提示和采样模型,确保评估涵盖各种场景;二是标注质量高,通过多轮人工三元比较和冲突解决算法,得出可靠的偏好排序。
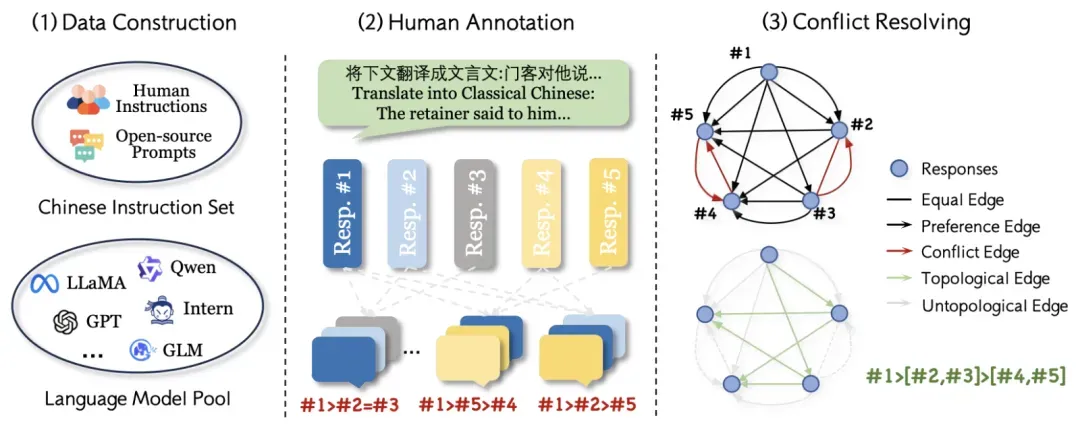
提示收集方面,我们从多个开源数据集中采样中文提示,包括Humaneval-XL(代码生成)、MathOctopus(数学推理)、GAOKAO-Bench(高考题目)、HalluQA(幻觉检测)等,并额外收集真实用户指令用于分布外评估。最终从开源数据集选取1,146个提示,从人工指令选取1,346个提示。
回复收集方面,我们为每个提示从不同模型中采样5个回复,采样模型包括开源模型(Qwen2、LLaMA-3、InternLM2等)和闭源模型(GPT-4、GPT-3.5、Claude-3等),确保质量和分布多样性。针对部分开源模型中文能力受限可能出现的乱码,人工标注者会在标注过程中剔除无意义内容但保留不影响语义的轻微混杂。
数据标注依赖人工判断以捕捉人类偏好。对于每个提示的5个回复,我们拆分为5个标注任务,每个任务包含对3个相邻回复的偏好比较,由不同标注者独立完成。为解决标注冲突问题,我们将标注结果转换为有向偏好图,使用深度优先搜索识别冲突并合并为更大节点,重复此过程直到无冲突,最后通过拓扑排序得到部分排序结果。
最后,在CheemsBench上,我们采用准确率和完全匹配率两个指标全面评估奖励模型性能。
3.3 中文偏好数据
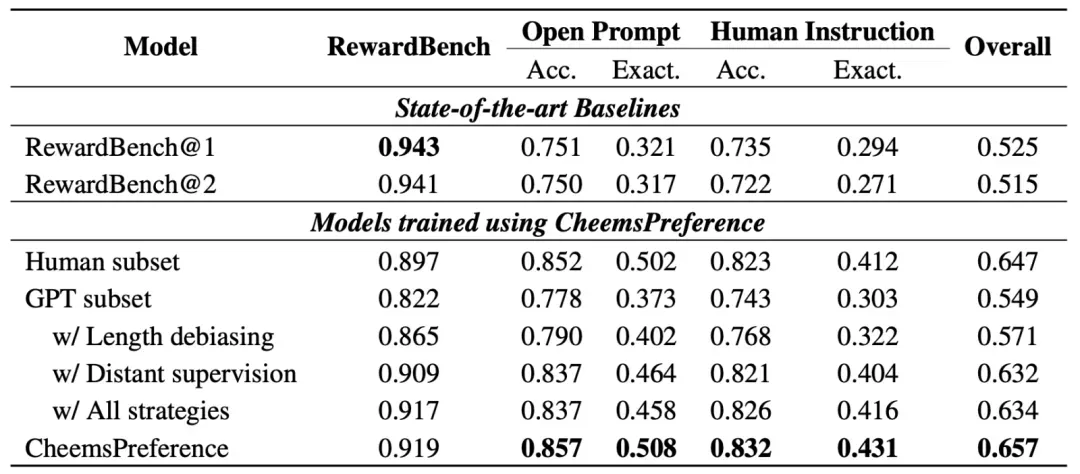
为了支持中文奖励模型训练,我们构建了CheemsPreference偏好数据集。该数据集具有两个主要特点:一是规模大且多样化,包含2.7万条真实人工指令,采用多层分类体系,每个提示从多个模型采样多个回复;二是标注质量高,通过结合人工标注和GPT-4标注的远程监督算法建立可靠的偏好排序。
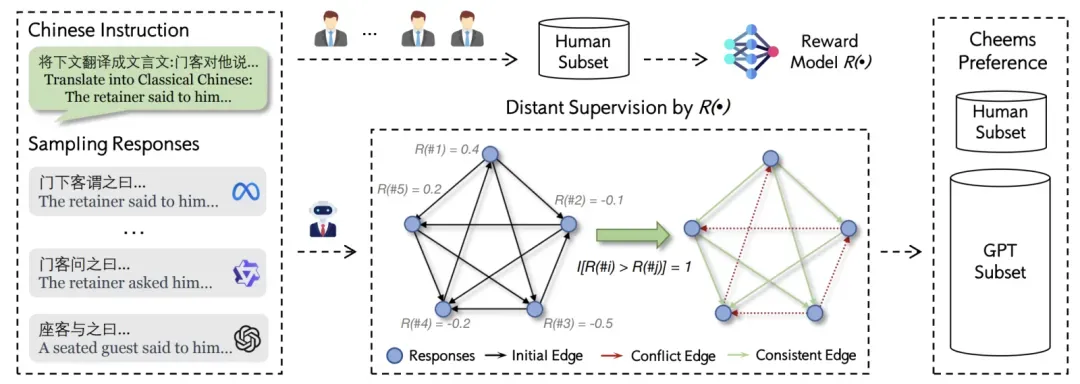
指令收集方面,我们收集了27,861条真实人工指令,并开发了包含8个主要类别和数十个细分类别的全面分类体系,确保指令的多样性和覆盖面。
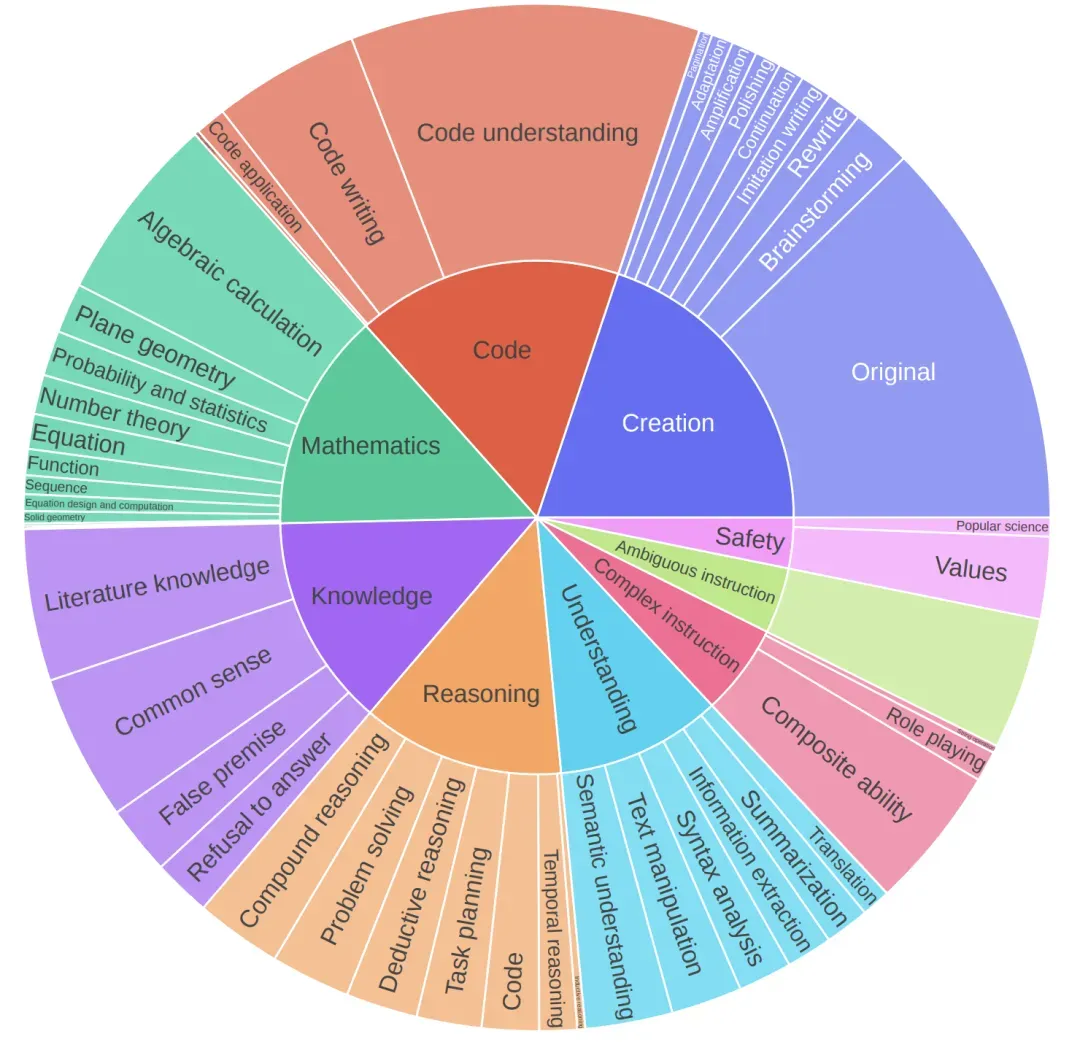
回复采样方面,我们从广泛的模型中采样回复,包括开源模型(Qwen2/2.5系列、LLaMA-3系列、InternLM2、GLM4等)和闭源模型(GPT-4系列、Claude-3等)。为保证回复质量,我们实施基于规则的方法检测异常长度或包含过多非中文符号的回复。虽然这种方法在数学或代码相关提示时准确率可能较低,但我们优先考虑高召回率以过滤更多低质量回复。最终每个提示平均获得5个以上回复。
偏好标注方面,考虑到人工标注成本高昂而GPT标注存在不一致性,我们采用了远程监督策略。首先由人工标注者标注小规模数据子集,然后使用GPT-4o标注更大规模数据集,对N个回复进行成对比较,并随机排列回复顺序以减少位置偏差。接着使用在人工标注数据上训练的奖励模型过滤GPT标注,建立一致的偏好顺序。最后采用长度去偏后处理策略,通过下采样平衡数据集。
3.4 实验结果
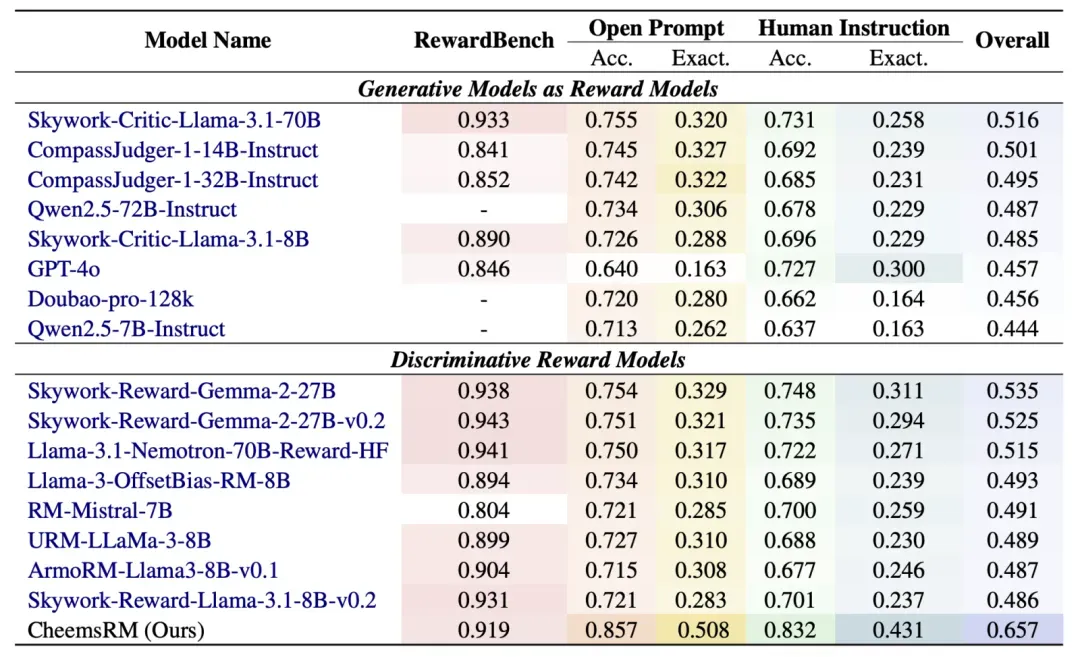
基准测试评估
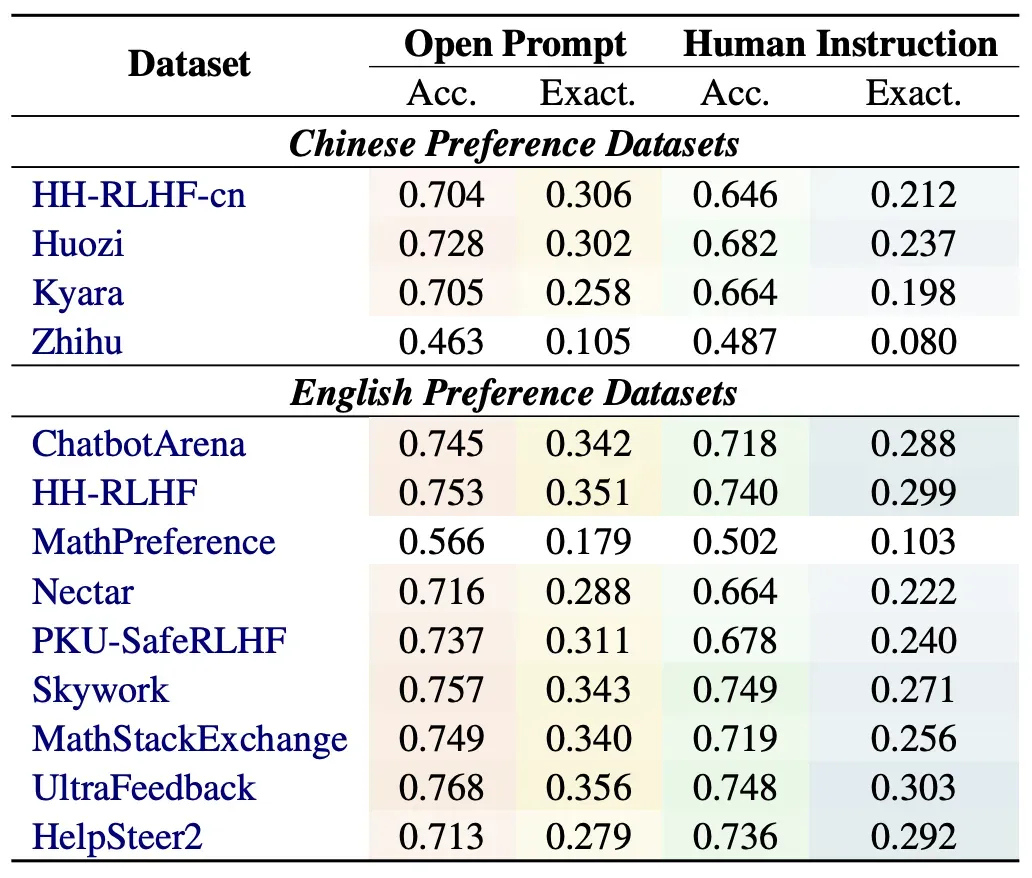
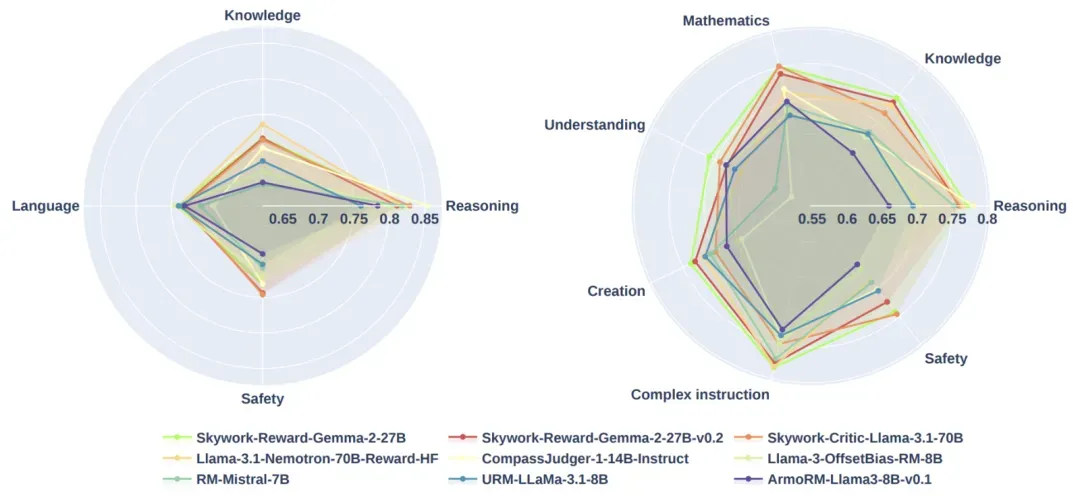
我们在CheemsBench上评估了当前主流的奖励模型,实验结果揭示了几个重要发现:首先,主流模型在中文场景下性能显著下降,表明中文奖励模型仍有很大提升空间;其次,模型在开源提示上的表现优于人工指令,因为人工指令更具分布外特性;第三,对于答案相对确定的提示,奖励模型能更准确地评估回复质量,在"推理"类任务上表现较好,但在"理解"等其他类别上存在明显不足。此外,我们评估了各种中英文偏好数据集的表现,结果显示中文数据集中"活字"数据集表现最佳,英文数据集中"Ultrafeedback"领先,但整体而言中英文数据集之间存在明显差距,凸显了构建更好的中文偏好数据集的必要性。
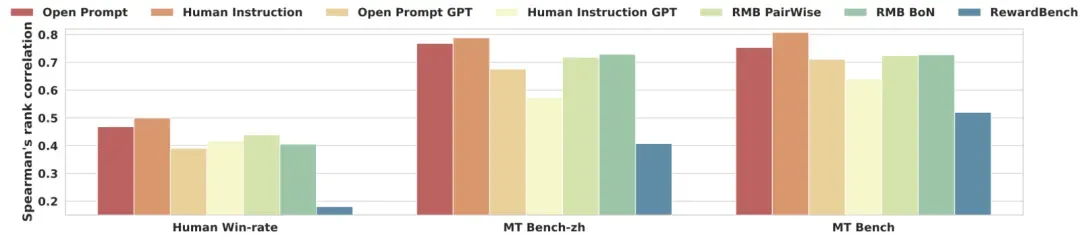
下游任务相关性
为探究CheemsBench与下游任务的相关性,我们在人类胜率、MT-bench-zh和MT-bench三个任务上采用Best-of-32采样策略进行验证。实验结果表明:一是我们的基准测试与下游任务表现出更强的相关性,在中英文任务中都得到验证;二是GPT标注的基准测试显示出次优的相关性,强调了人工判断在实现更好下游任务泛化性方面的重要性。
数据集构建消融实验
我们通过消融实验评估了数据集构建策略的有效性,主要发现包括:一是单独使用人工或GPT子集都不够理想,GPT子集难以完全捕捉人类偏好,而人工子集由于规模限制影响分布外性能;二是长度去偏策略能提升性能;三是远程监督策略显著改善了性能,突显了引入人工监督的重要性;四是结合所有策略能获得最佳效果。
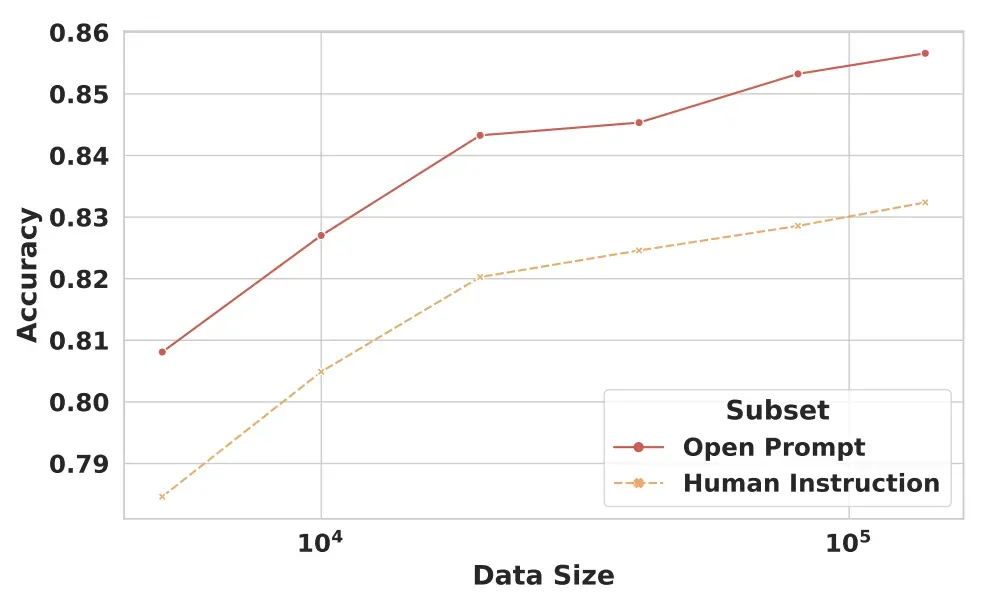
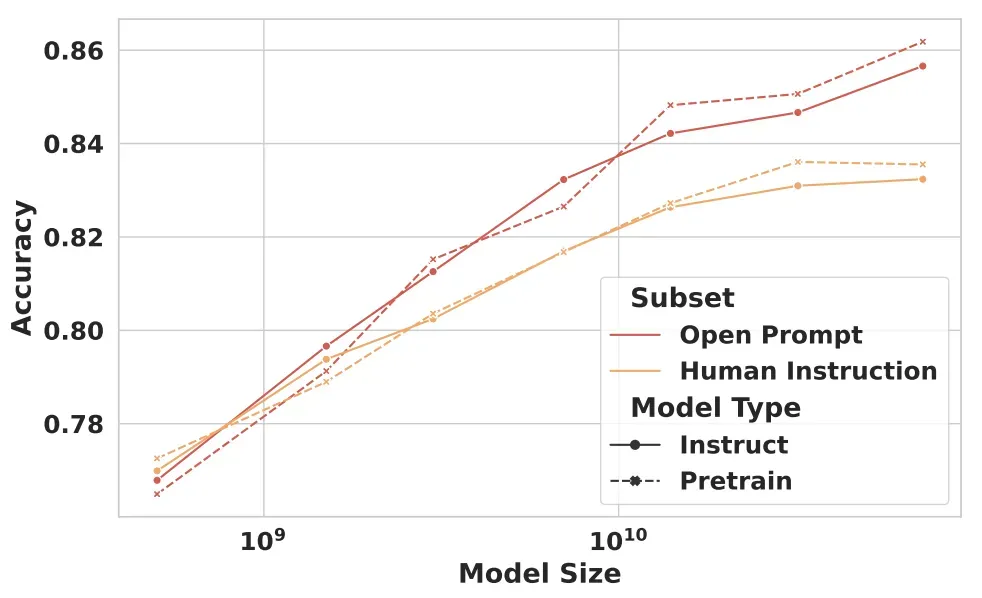
规模化趋势
我们研究了数据量和模型规模对性能的影响,发现:一是随着训练数据量增加,奖励模型在开源提示和人工指令子集上的性能都有提升,验证了远程监督方法的潜力;二是将模型规模从0.5B增加到72B能显著提升性能,表明更大模型能更有效地捕捉复杂的偏好模式。此外,从预训练模型或指令模型开始训练并无显著差异。
3.5 总结
本研究针对中文奖励模型开发中的关键问题,提供了两个重要贡献:第一,我们构建了CheemsBench评测基准,这是一个全面的中文奖励模型评估体系。第二,我们创建了CheemsPreference高质量中文偏好数据集,为模型训练提供了可靠的数据基础。基于这些资源,我们对中文奖励模型的发展现状进行了系统评估。结果显示,尽管现有模型在部分任务上表现良好,但整体上仍存在较大改进空间。同时,我们的实验证实了数据集构建中采用的远程监督和长度去偏等策略确实有效。这项工作的意义在于:一方面缩小了中英文奖励模型之间的性能差距,另一方面为后续研究提供了坚实基础。通过开放这些研究资源,我们希望吸引更多研究者投入中文大模型对齐研究,共同推动该领域的进步。
04、生成奖励模型Critic-Cot
论文标题:
Critic-CoT: Boosting the Reasoning Abilities of Large Language Model via Chain-of-Thought Critic
论文地址:
https://arxiv.org/pdf/2408.16326
收录情况:
ACL 2025 Findings
4.1 问题背景
随着大语言模型的快速发展,提升其推理能力成为实现更智能可靠AI系统的关键挑战。从认知角度看,人类推理过程涉及持续的反思和修正,这启发了在大语言模型推理过程中集成自我批判(self-critic)机制的研究。相比依赖外部反馈的传统批判方法,自我批判仅依靠模型内部能力,能够减少人工标注的高昂成本。然而,当前的自我批判方法面临显著挑战。首先,现有批判方法过于简化,通常仅依赖基础提示来直接指出错误,缺乏逐步的思维链检查或训练过程,导致自我批判准确率相对较低。这些简单方法往往类似于System-1的直观"思考",而非更严格深思的System-2推理。其次,任务解决和自我批判能力都依赖于模型固有知识,但当前缺乏对这两种能力在大语言模型内部关联关系的深入探索,使得在自我批判框架内平衡这两种能力变得困难。
4.2 Critic-CoT框架
为解决上述问题,本文提出了Critic-CoT框架,旨在将大语言模型的批判范式从类似System-1的直觉"思考"推向类似System-2的深思"推理"。该框架包含两个核心模块:基于弱监督的自动训练和推理时的自我检查。整体框架和具体例子如图所示:
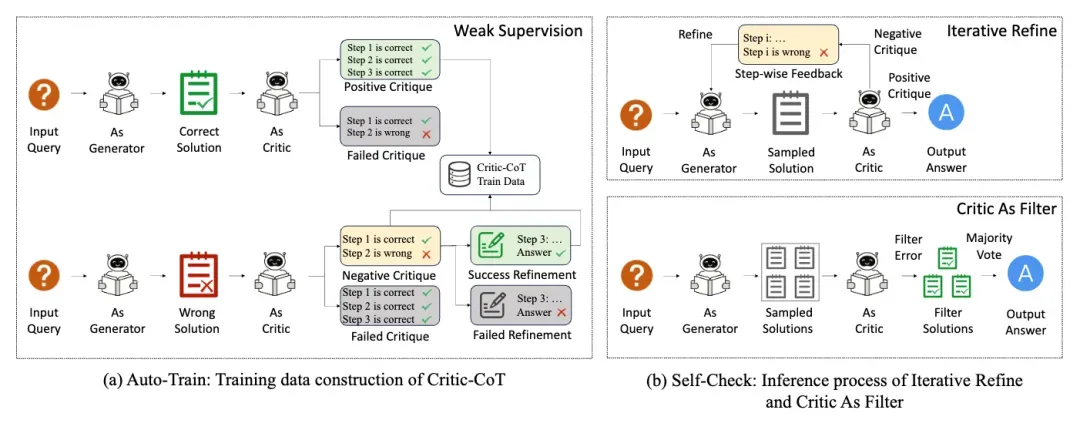

逐步思维链批判
采用逐步思维链批判方式,使批判-精化过程既可控又可形式化。给定问题和对应的黄金答案,将步尝试表示为,相应的批判表示为,其中步骤标签表示第步正确,表示错误。通过两个核心假设自动标注过程标签:(1)若最终答案错误,存在一个最早错误,通过精化可达到正确答案;(2)若最终答案正确,则所有中间步骤都正确。基于这些假设,系统能够自动识别有效的批判-精化数据对。
两阶段自动训练
第一阶段使用代表性指令跟随模型采样解决方案,利用GPT-4等先进模型作为批判模型,收集高质量批判数据构建模型基础批判能力。此过程将教师模型的Pass1@N指标蒸馏到学生模型的Top1@N中。第二阶段让学到的批判模型批判和精化自己的输出,进一步增强自我批判能力。结合两阶段数据训练最终的批判模型。
推理
推理阶段采用两种策略充分利用学到的批判和精化能力:
(1)迭代精化。由于单轮精化可能仍包含错误,采用迭代检查机制,一旦批判发现错误就重新精化,直到批判认为可信或达到最大重试次数;
(2)批判过滤。结合自一致性方法,利用批判能力过滤掉预测错误的答案。对多个尝试进行逐步标签检查,过滤出在某步检测到错误的尝试,最后对剩余结果进行多数投票。
该框架通过思维链批判实现了从System-1到System-2的转变,不仅提高了批判准确性,还通过弱监督方法减少了对人工标注的依赖。
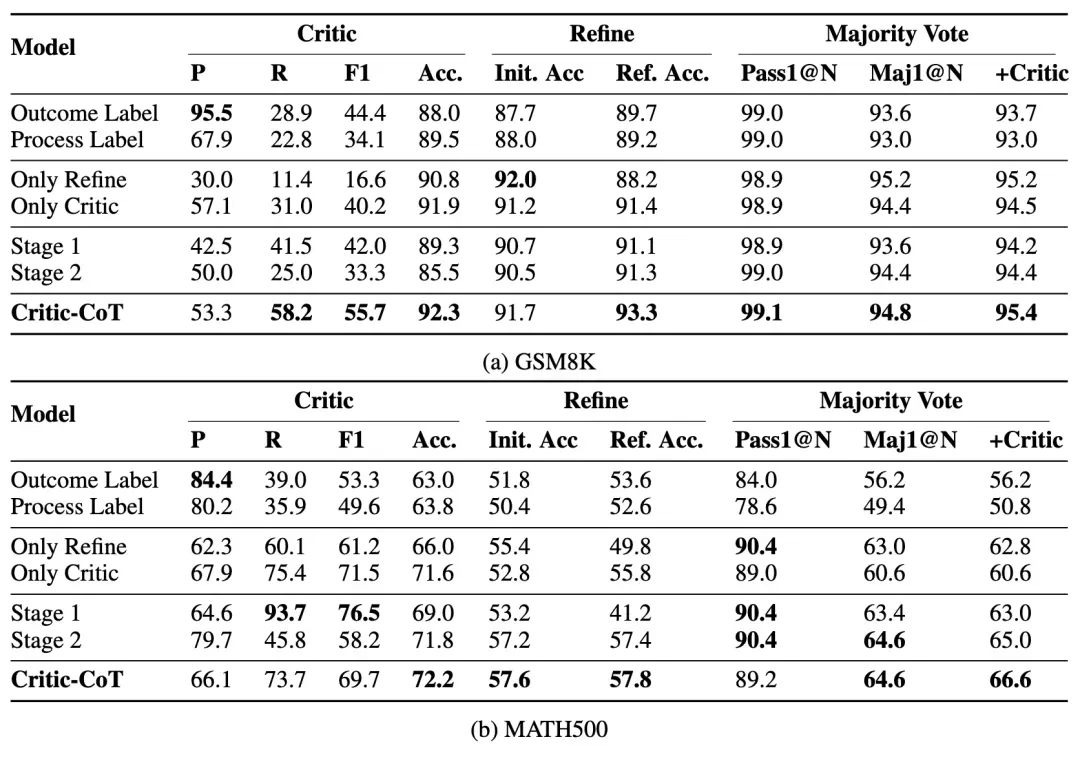
4.3 实验结果
主要性能提升
在GSM8K数据集上,训练模型的top-1准确率从89.6%提升至91.7%,迭代精化策略进一步提升至93.3%。结合批判过滤的Maj1@96方法达到最高准确率95.4%。在MATH数据集上:top-1准确率从51.0%提升至56.2%,迭代精化略微提升至56.6%,而批判过滤在Maj1@512上实现了从64.4%到66.4%的2.0%提升。
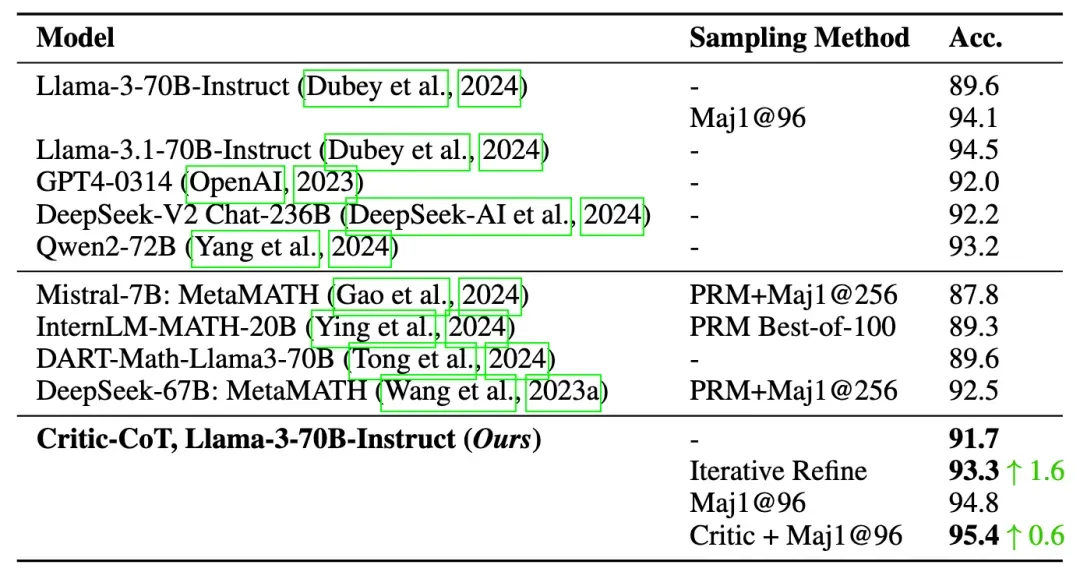
GSM8K上的结果
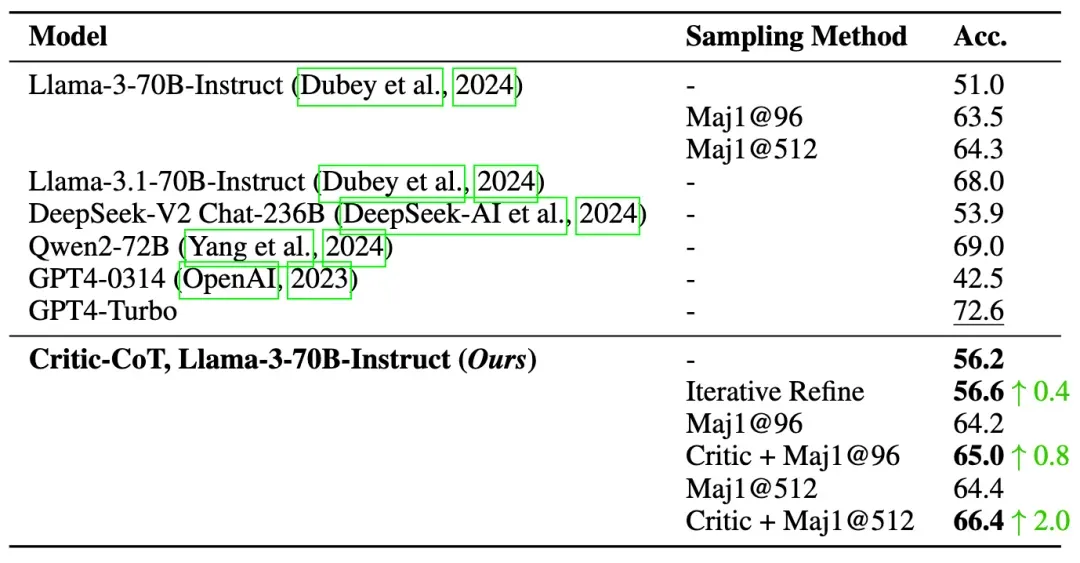
MATH上的结果
域外泛化能力
在StrategyQA和AGIEval数据集上的评估显示,批判模型在其他领域表现出良好的泛化能力,通过迭代精化和批判过滤策略均获得性能提升。
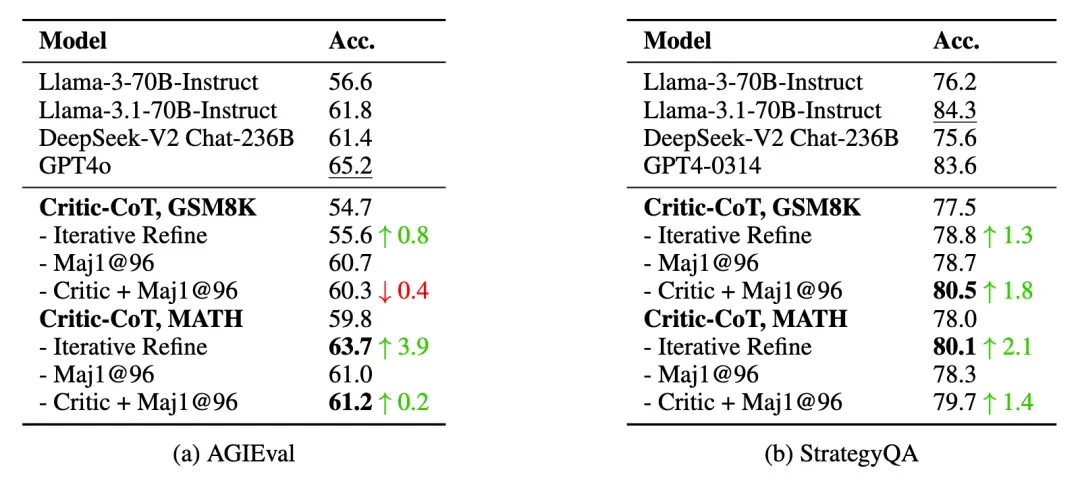
消融实验分析
实验验证了逐步思维链批判的必要性,移除思维链中间输出和逐步标签会负面影响召回指标。两阶段训练和批判-精化数据的结合对于提升模型性能都是必要的。
4.4 总结
本研究针对大语言模型自我批判能力的关键问题,提出了Critic-CoT框架,通过逐步思维链批判和弱监督数据构建,成功将模型的批判范式从System-1推向System-2。实验证明该方法能够有效提升模型在数学推理任务上的性能,更重要的是发现了批判能力与任务解决能力的相互促进关系。该框架通过弱监督方法显著降低了对大量人工标注的依赖,同时在域外数据集上展现出良好的泛化能力,验证了方法的鲁棒性。本工作为未来自我批判框架的设计和大语言模型向System-2推理的转变提供了重要启示,有望推动该领域的进一步发展。
05、CodePMP、
论文标题:
CodePMP: Scalable Preference Model Pretraining for Large Language Model Reasoning
论文地址:
https://arxiv.org/abs/2410.02229
5.1 问题背景
在LLM(大语言模型)的对齐训练中,尽管RLHF(基于人类反馈的强化学习)方法被证明是有效的,但它的效果依赖于RM(奖励模型)的能力。然而,训练RM需要高质量的偏好数据,在复杂推理领域(如数学和逻辑推理),这些数据的获取成本高昂且标注困难。此类偏好数据不仅需要多样化的prompt和响应,还需要准确的人类反馈。因此,提高复杂推理领域偏好数据的利用效率,即有限标注数据的情况下训练出更强大的RM,具有重要意义。
幸运的是,GitHub上有大量公开的源代码数据,经过筛选后可以获得高质量且规模庞大的代码片段。这些高质量代码片段不仅数量可观,而且具有丰富的多样性,可以用来反向生成多样化的code prompt(代码描述)。此外,CodeLLM(代码语言模型)已经得到了广泛关注和发展,最先进的CodeLLM可以根据code prompt生成对应的代码片段。基于此,提出了CodePMP方法——通过利用源代码数据,合成大量、多样的代码偏好数据,实现可扩展的偏好模型预训练,从而提高推理RM的微调样本效率,并最终提升LLM在推理任务上的表现。
5.2 方法介绍
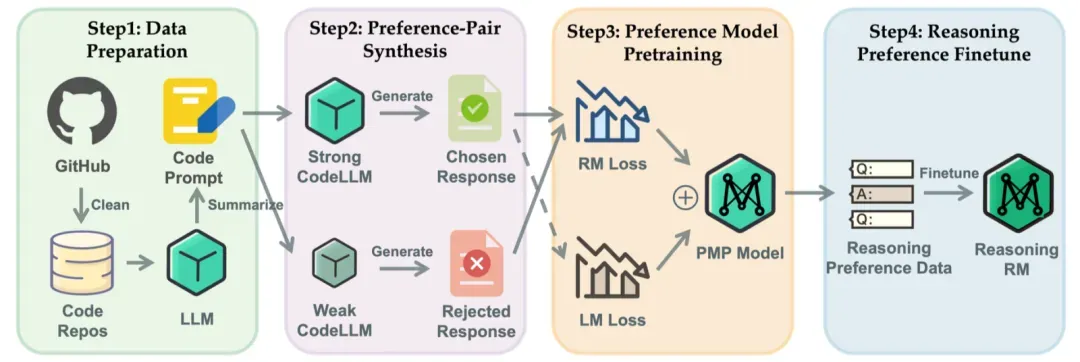
图1 CodePMP方法图
CodePMP方法的实现包括以下几个步骤:
- 查询生成:从GitHub中获取高质量代码片段,并生成相应的code prompt。
- 利用模型能力差异生成偏好数据:根据code prompt,分别使用强CodeLLM和弱CodeLLM生成对应的代码片段,并将两者组成 <chosen rejected> 偏好对。
- 损失函数设计:损失函数由两部分组成:基于 <chosen rejected> 偏好对计算的偏好损失(Pairwise Ranking Loss)和基于chosen响应计算的语言建模损失(LM Loss)。
- 偏好预训练:在此基础上,利用大量代码偏好数据对模型进行偏好预训练,从而提升模型在下游推理RM微调的样本效率。
伪代码如下图所示:

5.3 实验结果
我们设计了一系列实验来验证CodePMP的效果,同时涵盖了数学推理(GSM8K MATH)和逻辑推理。
1. RM准确率评测:
在数学推理和逻辑推理任务中,通过衡量奖励模型在区分测试集中chosen响应和rejected响应时的准确性,对比分别 经过CodePMP再微调RM 和 直接微调RM 的效果差别。实验结果显示,CodePMP给数学推理和逻辑推理的RM准确率带来了显著提升。
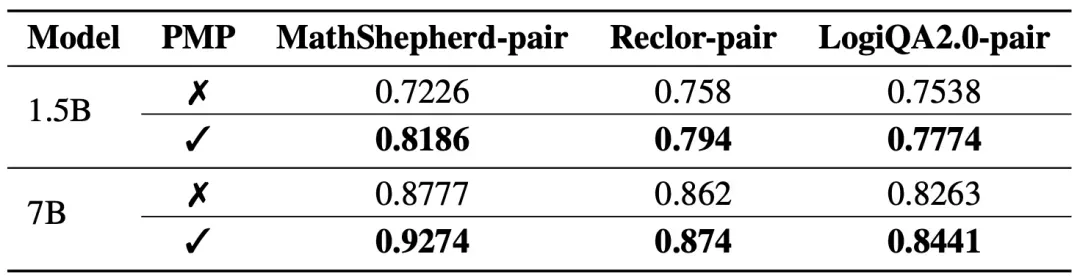
表1 RM准确率对比
2. Best-of-N(BoN)准确率评测:
通过为每个问题生成多个候选答案,并让RM选择最佳答案。在数学推理上,在候选答案数量增加到256的情况下,经过CodePMP再微调的RM仍然保持高的BoN准确率,而不使用CodePMP而直接微调的RM的BoN准确率则显著下降。在逻辑推理上,经过CodePMP再微调的RM也有着明显的优势。
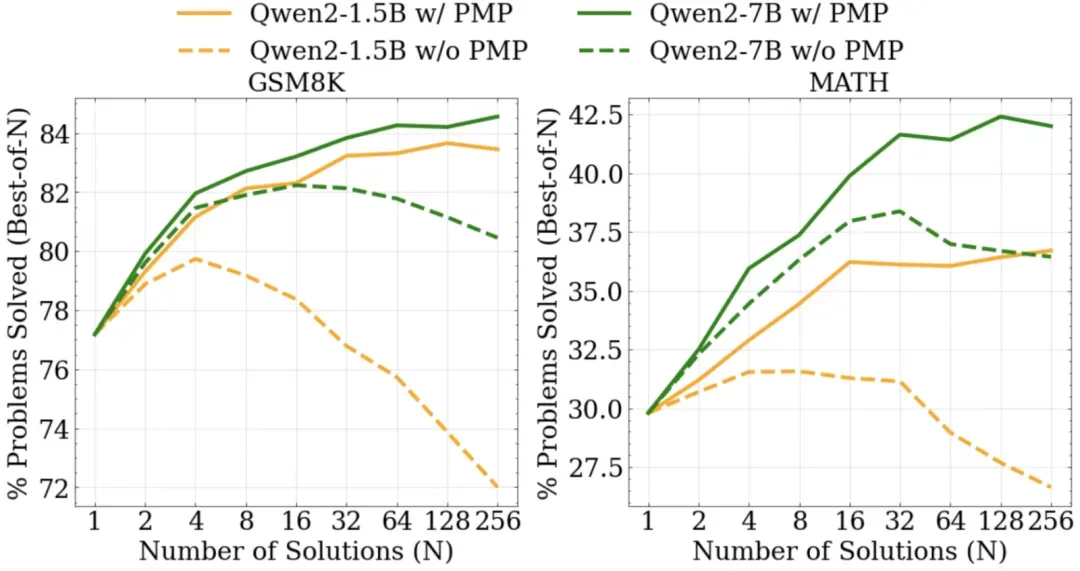
图2 数学领域Best-of-N准确率对比
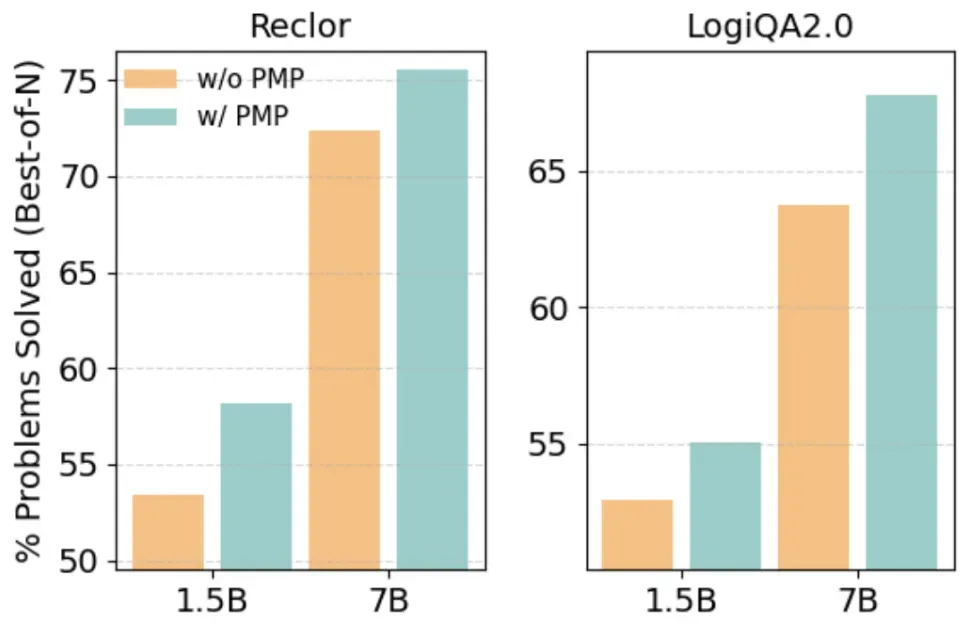
图3 推理领域Best-of-N(N=4)准确率对比
3. 样本效率实验:
在不同微调样本量下的模型效果对比。结果显示,使用CodePMP预训练的模型即使在微调样本量较少的情况下,也能达到或超过不使用CodePMP模型在大样本量下的表现,显著提高了推理RM微调的的样本效率。
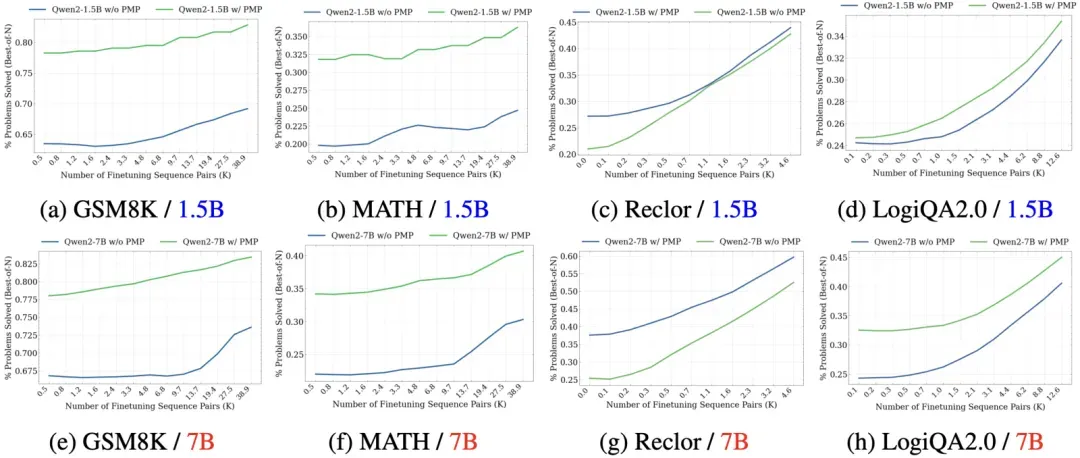
图4 不同微调样本量下的模型Best-of-N准确率对比
4. 扩展性测试:
分析了随着合成数据的增多,CodePMP方法带来的增益的变化趋势。实验表明,随着合成偏好对数量的增加,模型在推理偏好任务中的表现持续提升,且未出现效果减弱的迹象,展示了CodePMP方法的高度扩展性。
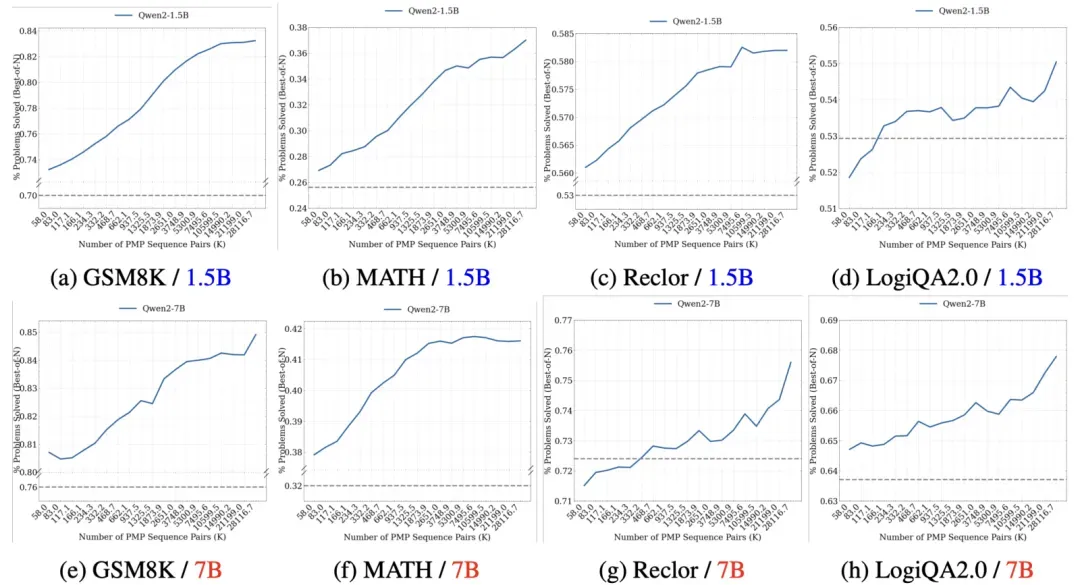
图5 经过不同规模数据的CodePMP后的模型Best-of-N准确率变化趋势。虚线是不经过CodePMP直接进行RM微调的表现。
5.4 总结
CodePMP展示了一种可扩展、性价比高的新方法,极大地提升了LLM在推理偏好任务中的表现,并减少了对高质量人工标注数据的依赖。未来,我们还将探索如何将更多的监督信号引入到偏好预训练中,进一步优化预训练中的偏好建模。
06、自对齐幻觉缓解方法(self rewarding)
论文标题:
On-Policy Self-Alignment with Fine-grained Knowledge Feedback for Hallucination Mitigation
论文地址:
https://arxiv.org/pdf/2406.12221
收录情况:
ACL 2025 Findings
6.1 问题背景
大语言模型在生成流畅合理回复的同时,偶尔会在回答中编造事实,这种现象被称为幻觉。幻觉的核心问题是模型生成内容与其内部知识之间的不匹配。这种不匹配主要表现为三种类型:(1)误导性回答:模型在其知识边界内错误回答问题;(2)鲁莽尝试:模型对超出其知识范围的查询进行回答;(3)回避式无知:模型尽管拥有相关知识却拒绝提供答案。现有的学习型方法面临几个关键挑战:首先,由于离策略数据采样导致分布偏移,产生次优模型;其次,粗粒度的实例级反馈无法精确定位幻觉,因为单个回答可能包含正确和错误的事实;最后,现有知识检测技术可能产生不一致结果,无法准确反映模型的知识边界。
6.2 RLFH框架
为解决上述问题,本文提出了强化学习幻觉缓解(RLFH)框架,这是一种在线策略自对齐方法,通过细粒度反馈实现幻觉缓解。该框架使大语言模型能够通过细粒度的在线策略反馈主动探索自身知识边界。其包含三个核心步骤:(1)从调优模型采样回复;(2)策略作为判断模型执行自评估收集细粒度知识反馈;(3)将语言形式反馈转换为token级密集奖励用于强化学习。
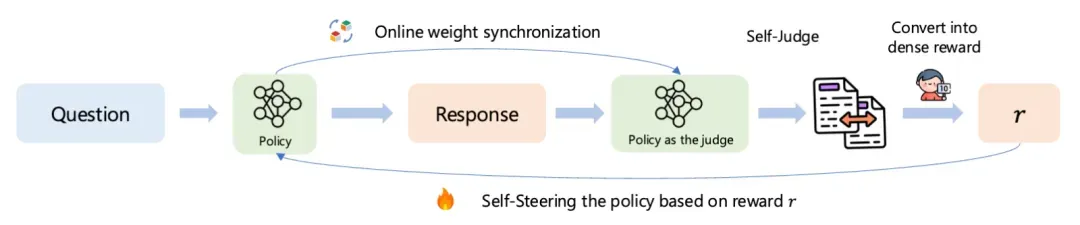
策略作为判断者的细粒度反馈
RLFH的核心创新是让策略作为自己的判断者,在语句级别提供关于真实性和信息量的细粒度反馈。
其包含如下三个步骤:
- 语句提取:策略模型首先将回复分解为原子事实语句。采用层次化方法,先将回答分解为句子,再从每个句子中提取有效的事实性语句。
- 事实验证:策略模型通过与外部知识源比较来评估提取的事实性语句的真实性。每个语句被分类为:(1)正确:有证据支持的正确语句;(2)含糊正确:具有不确定性的准确语句;(3)模糊:真实性不确定的语句;(4)含糊错误:具有不确定性的错误语句;(5)错误:被证据否定的语句。
- 信息量评估:策略模型进一步评估语句的信息量,采用五分制评分,从提供关键信息(+5)到包含最少相关细节(+1)。
基于token级奖励的在线策略优化
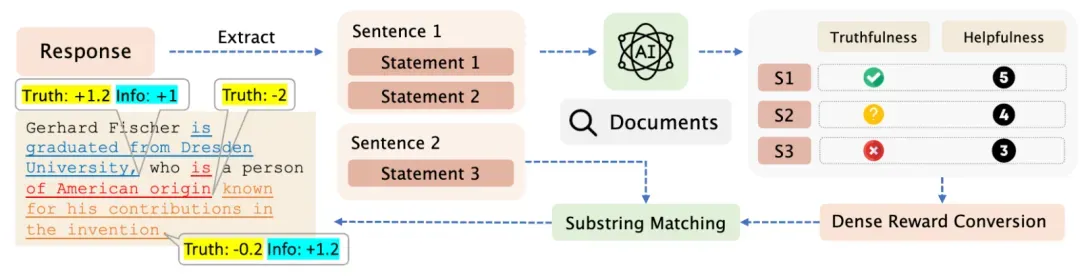
RLFH通过层次化结构和最长公共子序列算法将语句级评估映射回原始回答的token序列,为每个token分配相应的奖励值。
其中真实性奖励计算方式为,其中函数对正确语句给予正奖励,对错误语句给予负奖励;函数根据信息量调整奖励重要性;为平衡系数。
而信息量奖励计算方式为
其中为句子中语句总数,和构成最小奖励阈值,为信息量系数。对数函数确保奖励随语句数量和信息量增加,但增长率递减。
最后以上信息会通过最长公共子序列算法映射回原回复的token,将奖励值分配给对应的token位置,实现精确的token级反馈优化。
在线强化学习
在得到精确的奖励信号以后,即可使用近端策略优化(PPO)算法,通过最大化奖励期望来优化策略模型。
6.3 实验结果
主要实验
在HotpotQA、SQuADv2和Biography三个数据集上进行了全面评估,使用FactScore管道进行评估。实验结果显示,RLFH在所有数据集上都获得了最高的FactScore,证明了该方法在幻觉缓解方面的显著有效性。特别值得注意的是,尽管只在HotpotQA数据集上训练,该算法在两个域外数据集上都表现出改进的准确性,展现了良好的泛化能力。
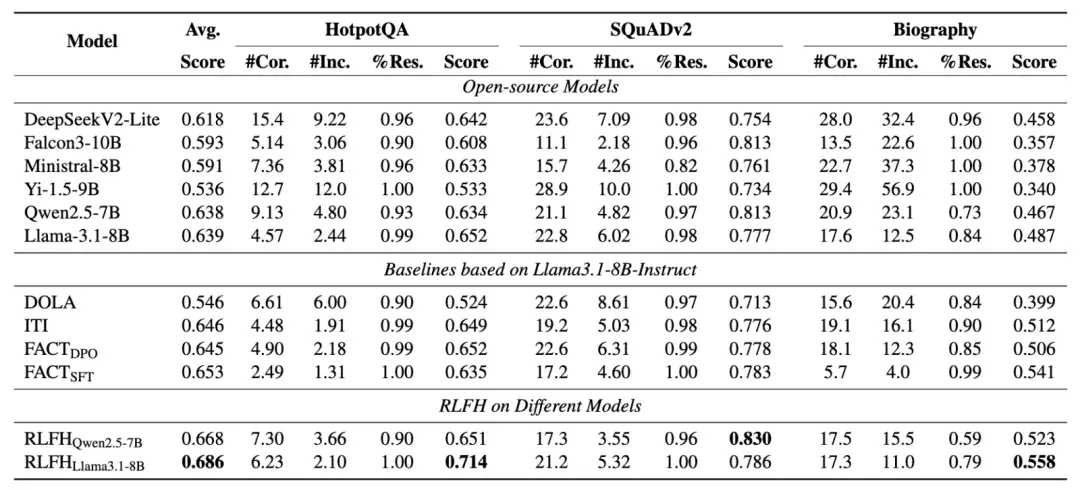
训练后的模型呈现出保守但准确的特点:回复比例有所下降但FactScore更高,在其能力范围内提供更准确的信息。上图比较了基础模型和RLFH调优模型的语句准确性与数量分布,显示联合分布向右下方向移动,表明模型生成回复更加保守但提高了信息可靠性。
详细分析结果
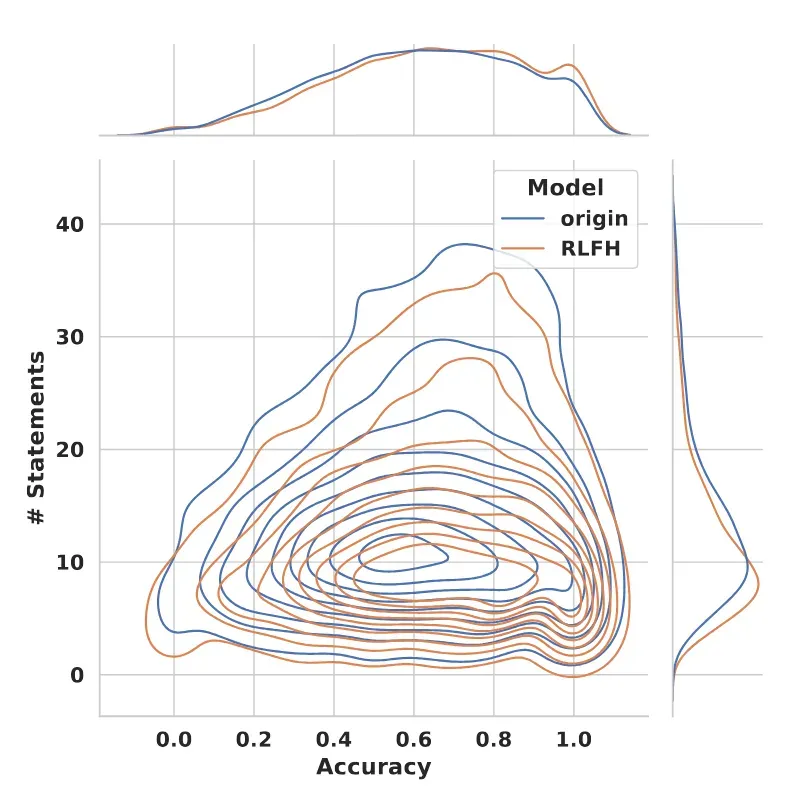
通过对不同真实性类别语句分布的分析发现,RLFH有效减少了错误和不可验证的语句。以下分别展示了正确语句、模糊语句和错误语句的分布变化。
进一步的,下图显示RLFH显著增加了高准确性回复的比例,减少了低准确性回复,特别是准确性超过0.7的回复有显著增加。同时,信息量分析表明模型在训练后能够提供更有价值的信息,下图显示回复分布向更高信息量方向移动,表明模型的回复通常在训练后提供更关键的信息,证明了该方法不仅提高了准确性,还保持了信息的有用性。
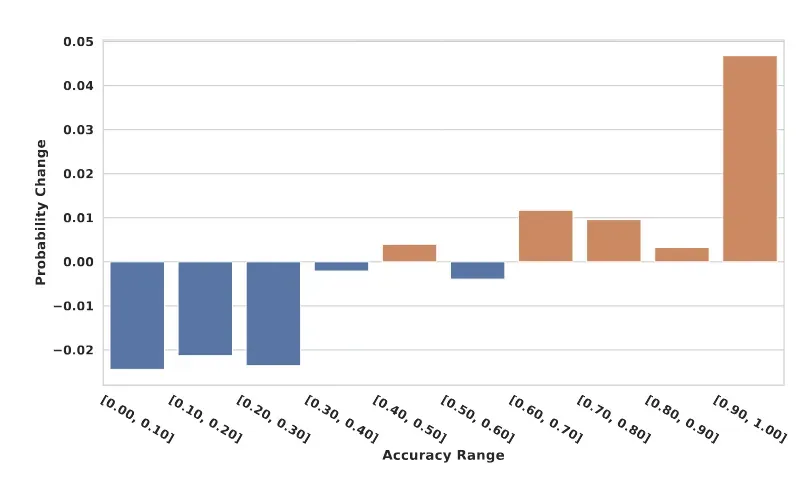
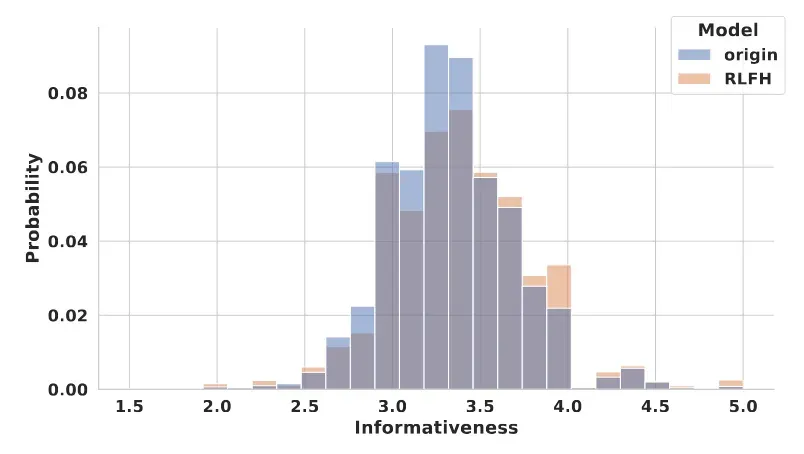
消融实验
为了深入理解RLFH各组件的贡献,进行了详细的消融实验分析。首先探究了奖励粒度对模型性能的影响,比较了响应级、句子级和语句级三种不同粒度的奖励信号。如下表所示,语句级奖励在所有设置中始终获得最高的FactScore,证明了细粒度反馈的重要性。这一结果表明,越精细的反馈信号越能帮助模型准确识别和纠正特定的错误内容。关于判断模型的选择,实验比较了在线策略设置与多种固定外部判断模型的效果。实验结果表明,让策略模型作为自己的判断者(在线策略方法)表现最优,同时消除了训练过程中对额外奖励模型的需求。这一发现不仅验证了自对齐方法的有效性,还显著降低了实际部署的复杂性和资源消耗。
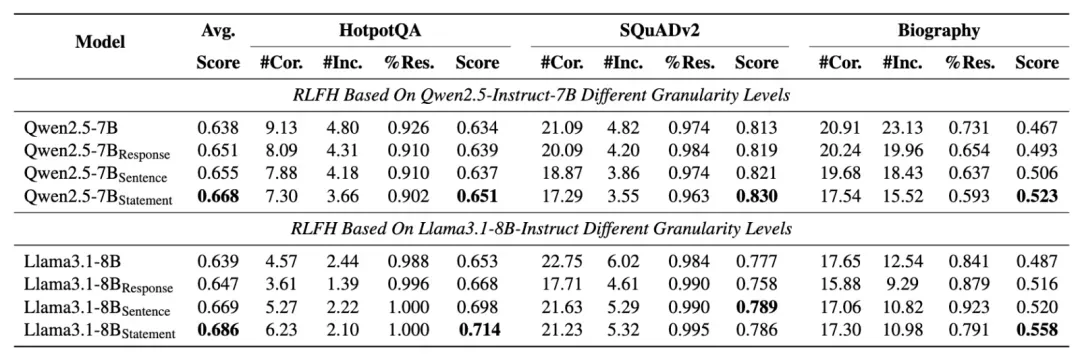
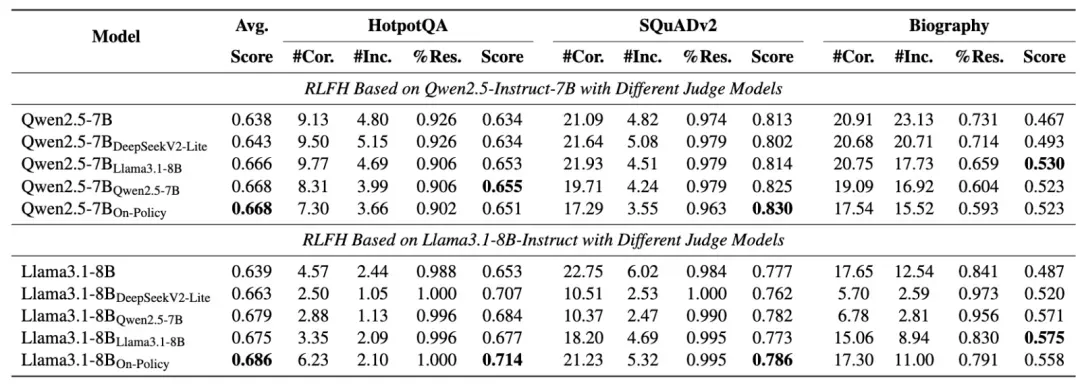
6.4 总结
本研究提出了RLFH,一种创新的在线策略自对齐方法,通过构建自评估框架让大语言模型主动探索知识边界并自我纠正幻觉行为。该方法的核心创新是策略模型作为自己的判断者,通过原子事实验证自动提供细粒度反馈,生成token级密集奖励信号用于在线强化学习优化,从而消除了对外部奖励模型的依赖。实验结果表明,该方法在多个基准数据集上显著提升了模型的事实准确性,为开发更可靠和自我感知的语言模型提供了重要基础,有助于减轻错误信息传播并保障模型在现实应用中的安全部署。
07、作者简介
温学儒
小红书 hi lab 团队算法实习生,现就读于中国科学院软件研究所中文信息处理实验室;主要研究方向为大语言模型对齐。
李梓超
小红书 hi lab 团队算法实习生,现就读于中国科学院软件研究所中文信息处理实验室;主要研究方向为大语言模型对齐、多模态对齐。
鱼汇沐
小红书 hi lab 团队算法实习生,现就读于中国科学院信息工程研究所,主要研究方向为大语言模型对齐和数据合成。
时墨
小红书 hi lab 团队算法工程师,主要研究方向为大语言模型对齐。
乘风
小红书 hi lab 团队算法工程师,主要研究方向为大语言模型预训练和对齐。
连轩
小红书 hi lab 团队算法工程师,主要研究方向为大语言模型对齐。