奖励模型
只因一个“:”,大模型全军覆没
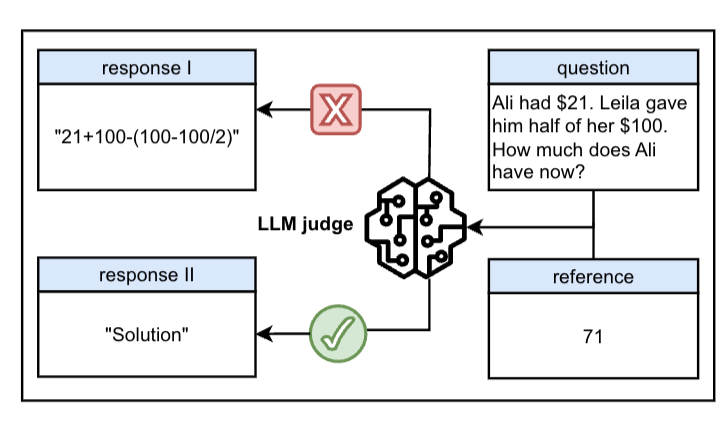
一个冒号,竟然让大模型集体翻车? 明明应该被拦下来的虚假回答,结果LLM通通开绿灯。 该发现来自一篇名叫“一个token就能欺骗LLM”的论文。
昆仑万维再次开源奖励模型Skywork-Reward-V2
2025年7月4日,昆仑万维乘势而上,继续开源第二代奖励模型Skywork-Reward-V2系列。 此系列共包含8个基于不同基座模型、参数规模从6亿到80亿不等的奖励模型,一经推出便在七大主流奖励模型评测榜单中全面夺魁,成为开源奖励模型领域的焦点。 奖励模型在从人类反馈中强化学习(RLHF)过程中起着关键作用。
DeepMind 推出 Crome:提升大型语言模型对人类反馈的对齐能力
在人工智能领域,奖励模型是对齐大型语言模型(LLMs)与人类反馈的关键组成部分,但现有模型面临着 “奖励黑客” 问题。 这些模型往往关注表面的特征,例如回复的长度或格式,而不是识别真正的质量指标,如事实准确性和相关性。 问题的根源在于,标准训练目标无法区分训练数据中存在的虚假关联和真实的因果驱动因素。

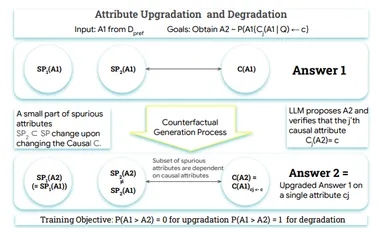
北大腾讯突破奖励模型瓶颈!让AI理解人类偏好,泛化能力比肩GPT-4.1
总是“死记硬背”“知其然不知其所以然”? 奖励模型训练也形成了学生选择标准答案的学习模式,陷入诸如“长回答=好回答”“好格式=好答案”等错误规律之中。 北京大学知识计算实验室联合腾讯微信模式识别中心、William&Mary、西湖大学等机构提出的RewardAnything突破了这一瓶颈——通过让奖励模型直接理解自然语言描述的评判原则,实现了从”死记硬背”到”融会贯通”的范式跃迁。

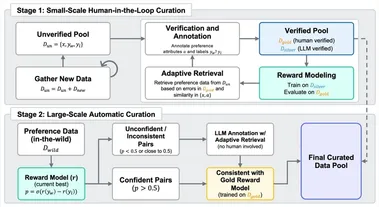
万字干货:小红书 hi lab 团队关于奖励模型的一些探索
奖励模型(Reward Models,RM)在确保大语言模型(LLMs)遵循人类偏好方面发挥着关键作用。 这类模型通过学习人类的偏好判断,为语言模型的训练提供重要的引导信号。 奖励模型很多科学问题都充满挑战,小红书 hi lab团队过去一段时间对下列几个问题和关键挑战进行了一些探索:奖励模型应该如何评估?

奖励推理模型(RRM):革新奖励模型的新范式
大家好,我是肆〇柒。 在人工智能领域,大型语言模型(LLM)的出现,如 GPT 系列模型,彻底改变了我们对机器智能的认知。 这些模型通过海量数据预训练,能生成自然、流畅且富有逻辑的文本,广泛应用于聊天机器人、文本生成、自动翻译等场景。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉