大家好,我是肆〇柒。在人工智能领域,大型语言模型(LLM)的出现,如 GPT 系列模型,彻底改变了我们对机器智能的认知。这些模型通过海量数据预训练,能生成自然、流畅且富有逻辑的文本,广泛应用于聊天机器人、文本生成、自动翻译等场景。然而,随着模型规模的不断扩大,人们逐渐意识到,仅仅依靠预训练资源的扩展,并不足以让模型真正满足人类的多样化需求。于是,研究重点逐渐转向了模型的后训练技术,希望通过各种优化方法,使模型更好地对齐人类的价值观和特定任务需求。
在众多后训练(Post-train)技术中,奖励模型扮演着至关重要的角色。它们如同智能的“裁判”,通过对模型输出结果的质量进行评估,为模型提供关键的反馈信号,引导模型朝着更符合人类期望的方向进化。从医疗诊断到法律建议,从科研辅助到教育辅导,这些复杂领域对模型输出结果的准确性、可靠性和安全性要求极高。而传统的奖励模型在面对这些复杂任务时,逐渐显露出其局限性,它们往往只能进行简单的、表面化的评估,难以深入理解那些需要多步推理和细致分析的复杂响应。
研究动机与问题提出
传统奖励模型的局限性主要体现在对测试时计算资源的利用不足。在面对复杂任务时,模型需要处理大量信息、进行多步推理和细致分析,才能准确评估一个响应的质量。然而,传统的奖励模型却很难做到这一点。例如,在数学证明验证中,一个正确的证明可能需要经过多个中间步骤的严谨推理,而传统模型可能只能简单地判断最终结果是否正确,却无法深入分析中间步骤的合理性;在逻辑推理问题解答中,模型可能因无法追踪复杂的逻辑链条,而错判一个看似合理但实际上存在漏洞的回答。
这些问题使得我们迫切需要一种新的奖励模型范式,能够有效利用测试时的计算资源,为复杂任务的响应评估提供更深入、更准确的结果。RRM(Reward Reasoning Models)被北大、清华、微软的研究着提出,它通过引入推理过程,填补了传统奖励模型在复杂任务评估中的空白,为模型智能评估领域带来了全新的思路。
奖励推理模型(RRM)的提出
RRM 的核心理念
RRM 的核心在于,在生成最终奖励之前,先进行一个刻意的推理过程。这个过程采用了链式思考(chain-of-thought)的方式,就像是给模型配备了一个“思考引擎”,让它能够在面对复杂问题时,像人类专家一样,进行逐步的思考和分析。例如,当评估一个数学问题的解答时,RRM 会先仔细审视问题的条件和要求,然后逐步分析解答过程中的每一步骤,验证其是否符合数学原理和逻辑规则,最后再给出一个综合的奖励分数。
这种理念的提出,彻底颠覆了传统奖励模型的直接输出模式。它不再仅仅关注最终结果的好坏,而是深入挖掘响应背后的逻辑和思路,从而更全面、更准确地评估一个响应的质量。这就好比在评判一篇学术论文时,我们不仅要看结论是否正确,还要看研究方法是否科学、论证过程是否严谨、引用资料是否可靠等多方面因素。
下图直观地展示了 RRM 的工作原理,即如何通过链式思考推理在生成最终奖励前自适应利用测试时计算资源。
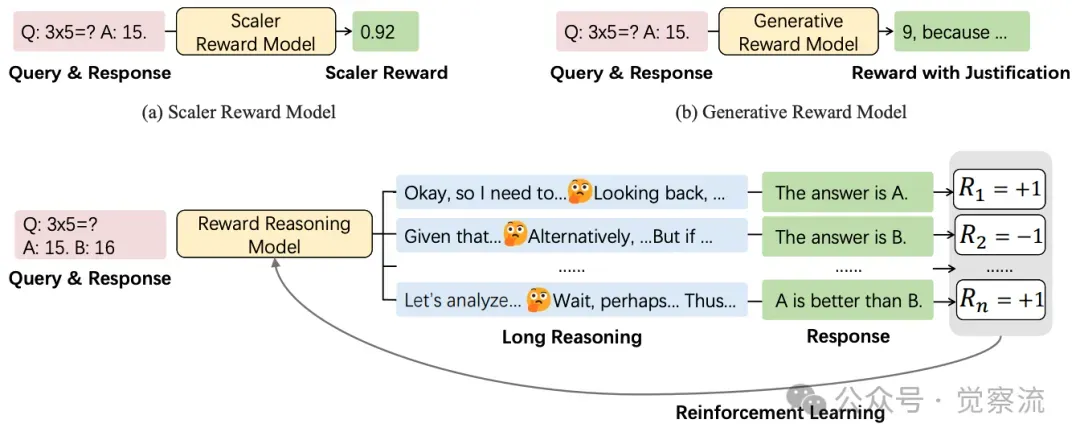
奖励推理模型(RRM)概览。RRM 通过链式思考推理自适应地利用测试时计算资源,然后生成奖励。
RRM 的训练框架 —— 基于强化学习的奖励推理(Reward Reasoning via Reinforcement Learning)
为了实现 RRM 的强大功能,研究者们为其量身定制了一套基于强化学习的训练框架。在这个框架中,模型不需要依赖显式的推理轨迹作为训练数据,而是在一个基于规则的奖励环境中,通过不断的自我尝试和探索,逐步进化出自己的推理能力。
这个训练框架中有几个关键要素:
- 状态空间 :它包括了查询内容、对应的响应对,以及模型当前的推理状态等。这些要素共同构成了模型在每一步推理时所面临的“局面”,模型需要根据这个局面来决定下一步的思考方向。
- 动作空间 :定义了模型在推理过程中可以采取的各种思考动作,比如从不同的视角分析问题、尝试新的解题策略、验证中间结果的正确性等等。
- 策略网络和价值网络 :策略网络负责根据当前的状态,生成下一步推理动作的概率分布,告诉模型在当前局面下,哪些思考方向更有可能带来好的结果;价值网络则负责评估当前状态下的累积奖励期望,帮助模型判断当前的推理路径是否值得继续深入。
在训练过程中,采用策略梯度方法等优化算法,根据模型的推理结果所获得的奖励信号,来不断更新策略网络和价值网络的参数。同时,通过巧妙的机制平衡探索与利用的关系,在鼓励模型尝试新的推理策略的同时,也充分利用已有的有效策略,逐步提升模型的推理能力。
与传统强化学习方法相比,这个训练框架在处理奖励模型任务时展现了独特的优势。它能够更好地适应奖励模型的特点,比如模型输出的多样性、任务的主观性等,同时提高了样本效率,减少了对大规模标注数据的依赖,使得 RRM 的训练更加高效和灵活。
RRM 的输入表示与多响应奖励策略
输入表示
RRM 的输入包括一个查询和两个对应的响应。为了引导模型全面、系统地评估这两个响应的质量,研究者们精心设计了一套输入表示方法。通过系统提示,模型会根据一系列评估标准,如指令遵循度、帮助性、准确性、无害性和细节程度等,对两个响应进行深入分析。
例如,当评估一个历史事件分析的响应时,模型会先检查响应是否准确地遵循了查询中提出的具体要求,比如分析的事件范围、关注的时间段等;然后评估它是否提供了足够的细节来支持其观点,是否避免了有害或偏颇的内容,以及是否能够真正帮助用户理解这个历史事件的本质和影响。在完成这些分析后,模型会输出一个明确的决策,指出哪个响应更优。
这种输入表示方式为模型提供了丰富的上下文信息,使模型能够从多个维度全面评估响应质量,就像一位严谨的学者在评审论文时,会从选题、内容深度、论证逻辑、语言表达等多个方面进行综合评价。
构造输入数据的代码示例
以下是一个构造 RRM 输入数据的 Python 代码片段:
复制prompt_template = """
You are a helpful assistant in evaluating the quality of the responses for a given instruction. Your goal is to select the best response for the given instruction. Select Assistant 1 or Assistant 2, that is better for the given instruction. The two responses are generated by two different AI assistants respectively. Do NOT say both / neither are good. Here are some rules of the evaluation: (1) If the instruction does not contain harmful content, you should prioritize evaluating whether the output honestly/precisely/closely executes the instruction, then consider its helpfulness, accuracy, level of detail, harmlessness, etc. (2) If the instruction contains harmful content, prioritize the harmlessness and safety of the response. (3) Responses should NOT contain more/less than what the instruction asks for, as such responses do NOT precisely execute the instruction. (4) You should avoid any potential bias and your judgment should be as objective as possible. Here are some potential sources of bias: - The order in which the responses were presented should NOT affect your judgment, as Response A and Response B are equally likely to be the better. - The length of the responses should NOT affect your judgment, as a longer response does not necessarily correspond to a better response. When making your decision, evaluate if the response length is appropriate for the given instruction. (5) Your output should only consist of “\boxed{Assistant 1}” if assistant 1 is better, or “\boxed{Assistant 2}” if assistant 2 is better. Omit any other output.
## Query
{query}
## Assistant responses
### Assistant 1
{response1}
### Assistant 2
{response2}
## Analysis
Let’s analyze this step by step and decide which assistant is better, and then answer \boxed{Assistant 1} or \boxed{Assistant 2}.
"""
query = "请解释相对论的主要概念。"
response1 = "相对论主要包括狭义相对论和广义相对论。狭义相对论基于相对性原理和光速不变原理,提出了时间膨胀和长度收缩等概念;广义相对论则进一步引入了等效原理和弯曲的时空概念,用以解释引力现象。"
response2 = "相对论是爱因斯坦提出的理论,主要包括狭义相对论和广义相对论。狭义相对论认为时间和空间是相对的,与物体的运动状态有关;广义相对论则将引力解释为时空的弯曲。"
input_data = prompt_template.format(query=query, response1=response1, response2=response2)
print(input_data)通过以上代码,大家可以了解到如何构造符合 RRM 要求的输入数据格式,进而为后续的推理和评估做好准备。
多响应奖励策略
为了应对实际应用中多样化的需求,RRM 引入了多响应奖励策略,包括 ELO 评分系统和淘汰赛策略。
ELO 评分系统借鉴了国际象棋等竞技游戏中的成熟理念。在这个策略中,每个响应都像是一名棋手,它们之间进行一对一对决。根据对决的结果,模型会为每个响应分配一个数值化的评分。这个评分不仅反映了响应的相对质量,还会随着后续更多的对决结果而不断更新,从而更准确地体现出模型对各个响应的偏好。例如,在一个包含多个学术观点总结响应的任务中,ELO 评分系统能够通过多轮对决,逐步筛选出那些逻辑更严谨、内容更全面、表达更清晰的优质响应。
淘汰赛策略则模拟了竞技体育中的淘汰赛过程。在这一策略下,多个响应会被随机配对,进行多轮比较。在每一轮中,模型会选出更优的响应进入下一轮,直到最终决出最佳响应。这种策略的优势在于,它能够在有限的计算资源下,快速、高效地确定优质响应。例如,在一个大规模的问答任务中,需要从成百上千个候选答案中找出最准确、最符合用户需求的那个,淘汰赛策略就能够通过多轮筛选,逐步缩小范围,最终锁定最佳答案。
ELO 评分系统与淘汰赛策略的数学原理
ELO 评分系统
ELO 评分系统的更新公式如下:
其中, 表示更新后的评分,是原始评分, 是更新因子,用于控制评分变化的幅度, 是实际比赛结果(胜者得 1 分,平局得 0.5 分,负者得 0 分), 是预期比赛结果,根据两个响应的当前评分计算得出。
例如,假设有两个响应 A 和 B,它们的当前评分分别为 1200 和 1000。根据 ELO 评分公式,预期 A 胜出的概率为:
如果 A 在对决中胜出,则其评分更新为:
通过这种方式,ELO 评分系统能够动态地反映响应的相对质量,并随着更多的对决结果而不断优化评分。
淘汰赛策略
淘汰赛策略中的配对算法通常采用随机配对的方式,以确保每个响应都有公平的机会参与比较。在每一轮中,模型会随机将响应两两配对,然后进行比较,选出更优的响应进入下一轮。这个过程会一直持续到只剩下最后一个响应,即为最佳响应。
例如,在一个有 8 个响应的淘汰赛中,第一轮会进行 4 场对决,胜出的 4 个响应进入第二轮;第二轮再进行 2 场对决,胜出的 2 个响应进入第三轮;第三轮进行最后 1 场对决,胜出的响应即为最佳响应。
实验设计与评估
实验目的与数据集
实验目的
RRM 的实验目的是全面验证其在奖励建模基准测试和实际应用中的性能表现。在基准测试中,研究者们希望 RRM 能够在多个评估维度上超越现有的强基线模型,展现出其在复杂任务评估中的优势。而在实际应用中,他们期待 RRM 能够通过奖励引导的 N 选 1 推理,准确地从多个候选响应中选出最优质的那个;同时,在使用 RRM 反馈进行 LLM 后训练时,能够有效提升模型的性能,证明其在实际复杂场景中的应用价值。
这些实验结果将为奖励模型领域的发展提供重要的参考,不仅能够推动奖励模型技术的进步,还可能为未来其他相关领域的研究提供新的思路和方法。
数据集介绍
为了训练 RRM,研究者们精心构建了一个多样化成对偏好数据集。这个数据集来源广泛,包括 Skywork-Reward、Tülu 3 数据集以及通过各种方法自合成的数据。
在自合成数据方面,他们采用了多种策略来生成带有偏好标签的数据对。例如,从 Tülu 3 提示数据集中随机采样查询,然后使用 Deepseek-R1-Distill-Qwen1.5B 模型为每个查询生成两个响应,再通过 GPT-4o 模型进行偏好标注。此外,他们还利用规则验证器,基于 WebInstruct-verified、Skywork-OR1、Big-Math-RL 和 DAPO-Math 等来源的可验证问题 - 答案对,生成了大量偏好数据对。
这些数据集的多样性对于 RRM 的训练至关重要。它们涵盖了各种类型的任务和不同领域的知识,使模型能够在广泛的场景下学习到如何准确评估响应质量。同时,通过合理构建数据集,研究者们避免了模型在特定领域的过拟合问题,提升了模型的泛化能力,使其能够在各种复杂多样的实际任务中发挥出色的作用。
实验结果与分析
奖励建模基准测试结果
在 RewardBench 和 PandaLM Test 这两个基准测试中,RRM 的表现令人瞩目。与 Skywork-Reward、GPT-4o、JudgeLM 等多个强基线模型相比,RRM 在不同评估维度上的准确率和整体一致性得分都取得了显著的提升。
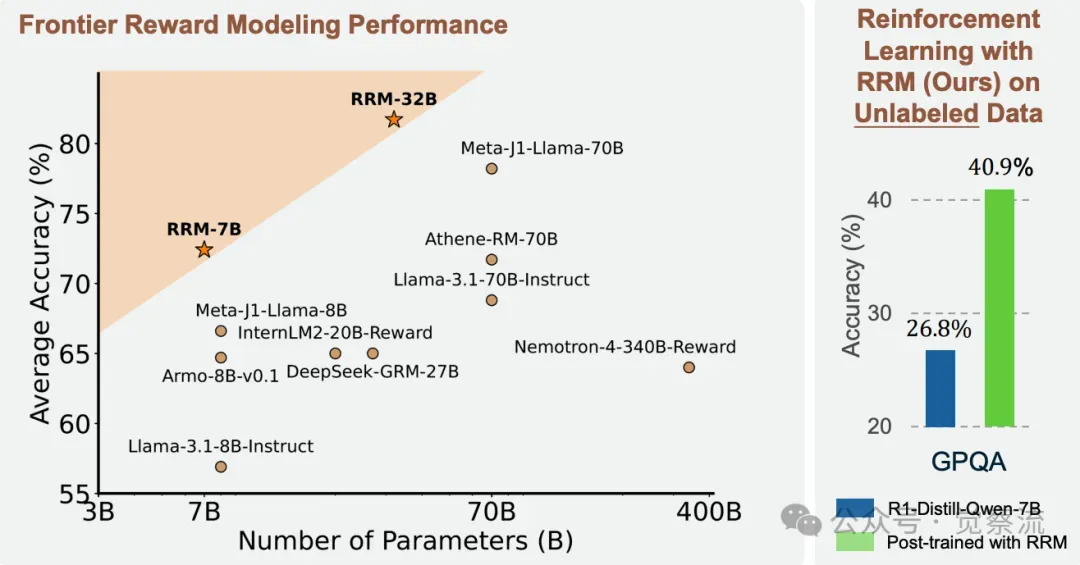
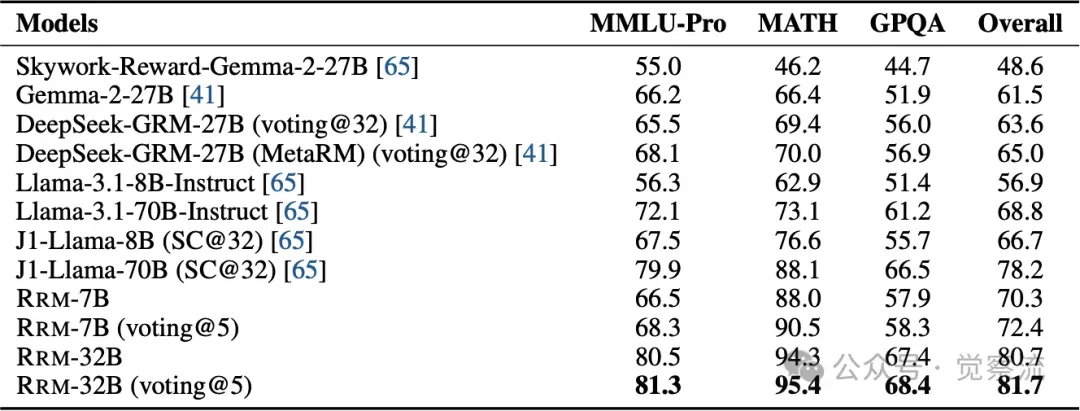
各种奖励模型在 Preference Proxy Evaluations 的 MMLU-Pro、MATH 和 GPQA 子集上的平均准确率。RRM 在不同模型尺寸下均优于先前的奖励模型。此外,即使在没有真实答案的情况下,以 RRM 为奖励模型进行强化学习,在评估通用领域推理能力的 GPQA 上也取得了显著的改进。
在推理类别中,RRM 凭借其强大的推理能力,在面对复杂的数学逻辑和物理概念等问题时,能够深入分析问题的内在结构,准确识别出正确的解答思路。例如,在解决一个涉及多步数学推导的问题时,RRM 能够仔细审视每一步骤的逻辑关系和数学原理应用,从而准确判断出哪个响应的推理过程更严谨、更符合数学规范。
而在聊天类别中,RRM 则展现了其对人类语言交流习惯和语义连贯性的敏锐把握。它能够根据对话的上下文,判断哪个响应更自然、更贴合对话主题,同时也能识别出那些可能存在潜在有害内容或偏离主题的响应。
此外,多数投票机制的引入进一步提升了 RRM 的性能。通过多次推理结果的聚合,模型能够降低偶然性错误的影响,提高评估结果的稳定性。与仅训练数据相同的 DirectJudge 模型相比,RRM 在多种领域内的优势更加明显,这充分证明了其利用测试时计算资源提升性能的有效性。
为了直观展示 RRM 在不同数据集上的性能提升,下图给出了 RRM 在 Preference Proxy Evaluations 的 MMLU-Pro、MATH 和 GPQA 子集上的平均准确率,相较于其他奖励模型,RRM 显著提升了准确率。
奖励引导的 N 选 1 推理实验结果
在 Preference Proxy Evaluations(PPE)基准测试中,RRM 在 MMLU-Pro、MATH 和 GPQA 等不同数据集上都展现出了出色的性能。它能够准确地从多个候选响应中识别出正确的答案,即使在面对众多干扰项的情况下,也能通过推理过程逐步排除错误选项,最终锁定正确答案。
例如,在 MATH 数据集中,对于一个复杂的数学问题,RRM 会先分析问题的类型和解题方法,然后逐步验证每个候选响应中的解题步骤是否正确、逻辑是否连贯。在这个过程中,它可能会发现某些响应在中间步骤就出现了错误,或者虽然最终结果正确,但解题过程不够规范,从而最终确定出那个既结果正确又过程严谨的最佳响应。
与 Skywork-Reward-Gemma-2 和 GPT-4o 等基线模型相比,RRM 在这些复杂推理任务中取得了显著的性能提升。这主要得益于其推理过程能够深入挖掘问题的本质,弥补了基线模型在面对复杂推理任务时的不足。
基于 PPE 提供的相同 32 个响应候选者,应用奖励模型选择最佳响应的奖励引导最佳推理结果。
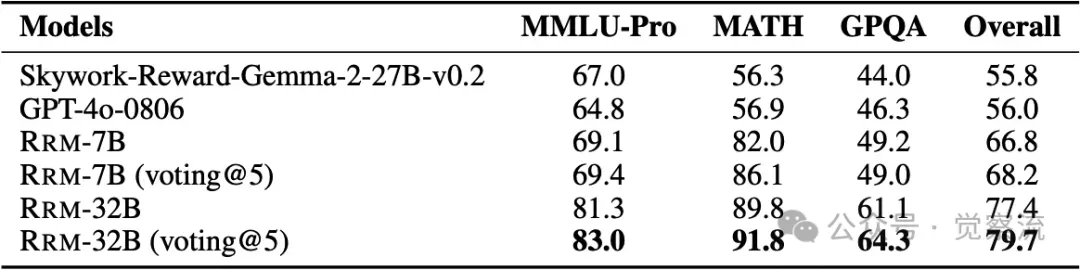
上表和下表展示了 RRM 在奖励引导的 N 选 1 推理和二元偏好分类任务中的详细评估结果。这些表格清晰地呈现了 RRM 在不同基准测试中的准确率,证明了其在多种任务中的有效性和优势。
进行二元偏好分类的评估结果。对于每个基准测试,报告在单个随机排列的成对响应上的准确率。
后训练应用实验结果
在未标记数据上的强化学习实验中,使用 RRM 作为奖励模型对 Deepseek-R1-Distill-Qwen-7B 进行后训练后,在 MMLU-Pro 和 GPQA 上的性能得到了显著提升。从训练过程中的关键指标变化可以看出,RRM 通过对模型输出的高质量奖励信号反馈,引导模型逐步改进其响应质量。例如,在学习过程中,模型可能会根据 RRM 的奖励信号,逐渐调整其解题策略,采用更有效的推理方法,或者优化其语言表达,使回答更加准确、清晰和全面。
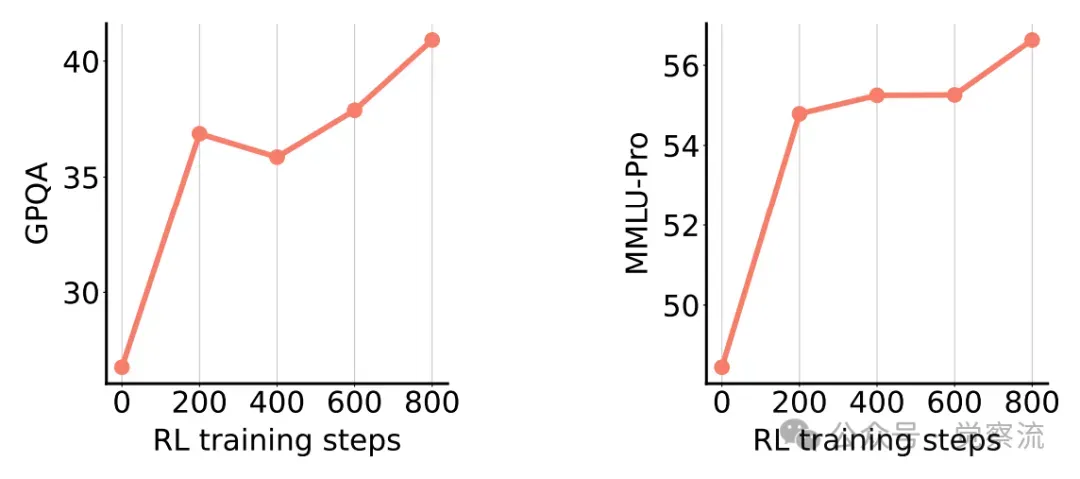
使用 RRM 进行强化学习后训练时的 GPQA 和 MMLU-Pro 准确率。
上图分别展示了在 GPQA 和 MMLU-Pro 数据集上,使用 RRM 进行强化学习后训练时,模型准确率随训练步骤的变化情况。从图中可以看出,随着训练的进行,模型的准确率稳步提升,表明 RRM 能够有效地引导模型优化。
在直接偏好优化(DPO)实验中,不同偏好标注模型(如 RRM-7B、RRM-32B 和 GPT-4o)对 Qwen2.5-7B 模型进行后训练后,在 Arena-Hard 基准测试上的得分差异明显。RRM-32B 凭借其高精度的偏好标注,帮助模型更好地学习复杂任务的解决方法,从而在 Arena-Hard 基准测试中取得了最高分。这表明 RRM 生成的偏好监督信号具有更高的质量和指导性,能够更有效地提升模型的性能。
下图展示了 RRM-7B 在整个训练过程中,在 RewardBench 的不同评估领域的性能轨迹。从图中可以看出,随着训练的进行,RRM-7B 在各个评估领域的性能均稳步提升,这表明 RRM 的训练框架能够有效地引导模型性能的持续优化。
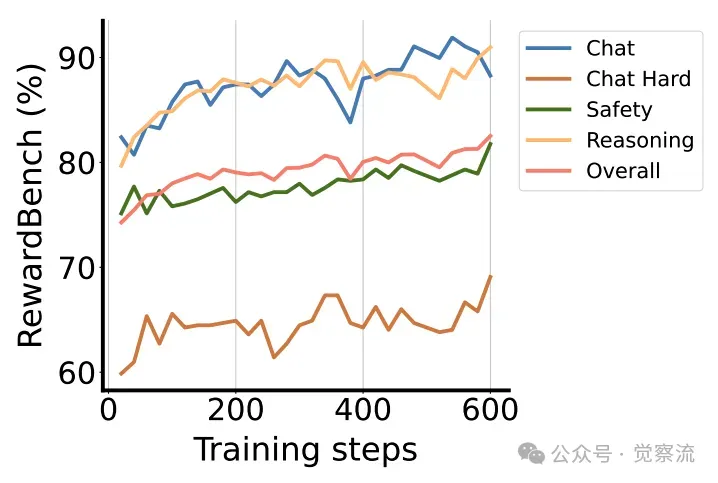
RRM-7B 在整个训练过程中,在 RewardBench 的不同评估领域的性能轨迹。
测试时计算资源扩展实验结果
在并行扩展实验中,随着成对比较次数的增加和多数投票机制的采用,RRM 在 MATH 候选响应上的最佳 N 选 1 性能稳步提升。这表明并行扩展为模型提供了更全面的视角和更多的思考机会,使模型能够从多个角度审视问题,从而优化最终输出。
在顺序扩展实验中,通过控制 RRM 的思考预算(最大 token 限制),研究者们发现延长思考链条能够显著提升模型在 RewardBench 上的性能。在不同思考阶段,模型会逐步深入挖掘问题的本质,不断完善其评估结果。例如,在思考初期,模型可能会对问题有一个大致的理解和初步的判断;随着思考的深入,它会逐步发现更多的细节和潜在问题,从而不断调整和优化其评估结果。
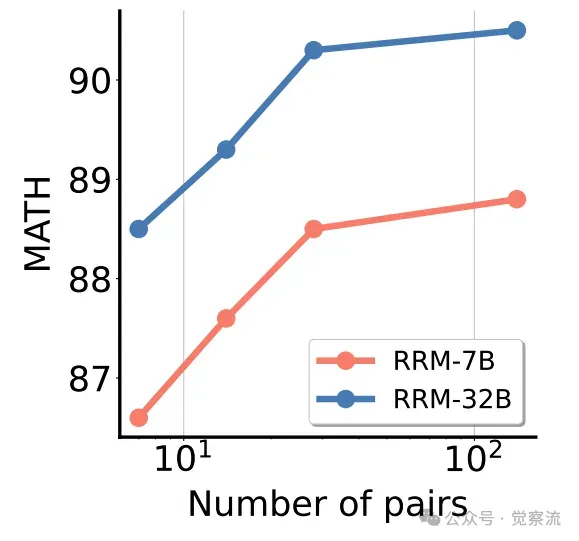
随着成对比较次数的增加,RRM-7B 和 RRM-32B 在 MATH 上的准确率变化趋势。
上图和下图分别展示了 MATH 准确率随着成对比较次数的变化情况,以及在不同思考预算下 RRM 在 RewardBench 上的结果。这些图表直观地反映了 RRM 在不同计算资源分配策略下的性能表现,为大家提供了清晰的实验洞察。
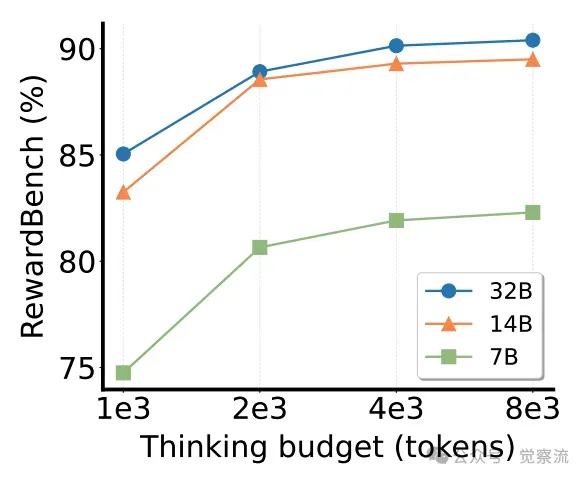
在不同思考预算下,7B、14B 和 32B RRM 在 RewardBench 上的准确率表现。
奖励推理模式分析
分析方法与指标
为了深入分析 RRM 的推理模式,研究者们采用了一种基于关键词统计的方法。他们将推理模式分为转换、反思、比较和分解四类,并分别统计了模型响应中包含相应关键词(如 “wait” 和 “alternatively” 等)的比例。同时,他们还引入了基于语法结构和语义角色标注的分析手段,解析推理过程中的句子结构和语义成分,识别出因果推理、假设检验等复杂推理结构,以及这些结构对模型评估结果的影响。
RRM 与基础模型的对比分析
与 Deepseek-R1-Distill-Qwen-32B 模型相比,RRM-32B 在推理模式上展现出了显著的差异。RRM-32B 在转换、反思和比较模式上的比例更高,这意味着它在处理复杂问题时,更倾向于从不同视角审视问题、对早期步骤进行自我检查和反思,以及对多个选项进行深入比较。例如,在面对一个多学科交叉的复杂问题时,RRM-32B 可能会先从不同学科的角度对问题进行分析,然后反思每个角度分析的合理性和完整性,最后综合比较各个角度的分析结果,从而得出一个全面且深入的评估结论。
下图展示了 RRM-32B 和 Deepseek-R1-Distill-Qwen-32B 的推理模式分析结果。RRM-32B 在转换、反思和比较模式上的比例显著高于基础模型,这直观地反映了 RRM 在推理过程中的优势。
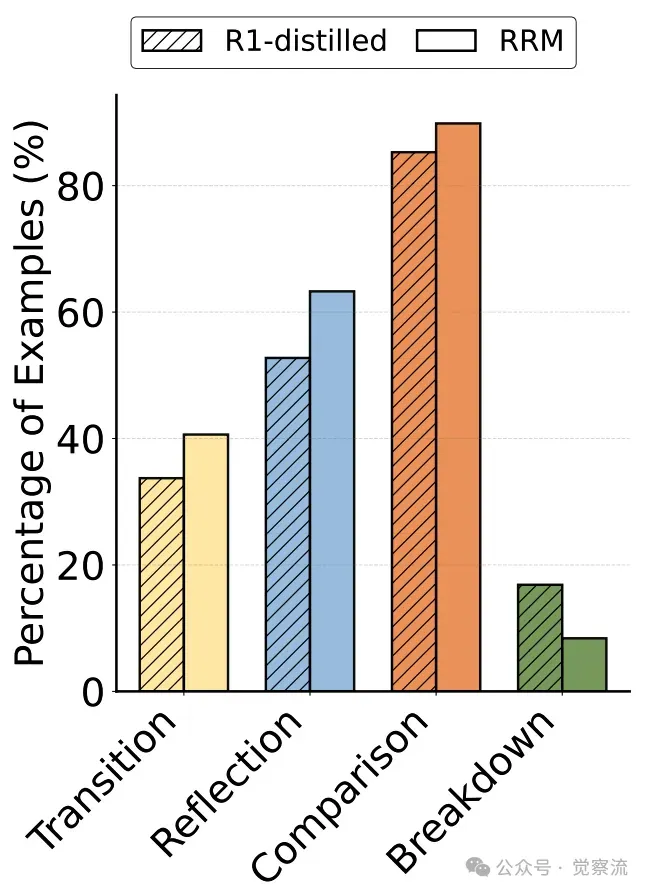
推理模式分析结果。与 DeepSeek-R1-Distilled-Qwen-32B 相比,RRM-32B 展现出更多的转换模式(40.63% 对 33.73%)、反思模式(63.28% 对 52.75%)和比较模式(89.84% 对 85.29%),但在直接问题分解上较少(8.40% 对 16.86%)。
而 Deepseek-R1-Distill-Qwen-32B 则更频繁地采用分解模式。它倾向于将复杂问题直接分解为多个子问题,然后分别处理每个子问题。这种模式虽然能够快速地缩小问题范围,但在处理需要综合多方面因素进行权衡和比较的问题时,可能会存在一定的局限性。
推理模式在不同任务类型和数据分布下的适应性研究
在不同任务类型和数据分布下,推理模式展现了不同的适应性和变化趋势。例如,在逻辑推理任务中,比较推理模式和分解推理模式都起着重要作用。随着问题复杂度的增加,比较推理模式的使用频率逐渐上升,因为模型需要在多个可能的推理路径中进行比较和选择;而分解推理模式则在处理高度结构化的问题时表现出明显优势,它能够将复杂问题分解为更易于处理的子问题,从而降低问题的难度。
在文本生成评估任务中,转换推理模式和反思推理模式则发挥着关键作用。转换推理模式帮助模型从不同视角审视文本的连贯性和一致性,而反思推理模式则使模型能够对文本的表达方式进行自我检查和优化,从而提高文本的质量。
推理模式对模型性能的具体影响分析
推理模式对模型性能有着直接且显著的影响。例如,当开启转换推理模式时,模型在面对需要多角度分析的问题时,能够更全面地考虑各种可能性,从而提高其准确率。而在关闭该模式时,模型可能只能从单一角度进行分析,容易遗漏一些关键信息,导致性能下降。
此外,推理模式的组合使用能够产生协同效应,进一步提升模型在复杂任务中的表现。例如,转换推理模式与比较推理模式相结合,可以使模型在不同视角下对多个选项进行深入比较,从而更准确地选出最优响应。然而,推理模式的过度使用也可能带来一些问题,如思考过程的冗余性和计算资源的浪费。为此,研究者们提出了优化推理策略和引入智能裁剪机制等解决方案,以实现推理模式的有效利用和性能的进一步提升。
下表对比了使用 RRM 验证器的评分策略,ELO 评分在准确率上持续优于淘汰赛评分,无论是 RRM-7B 还是 RRM-32B 模型都是如此。
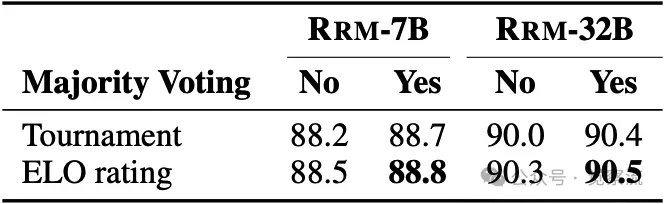
使用 RRM 验证器的评分策略比较。ELO 评分在准确率上持续优于淘汰赛评分,无论是 RRM-7B 还是 RRM-32B 模型都是如此。
总结与展望
研究总结
RRM 的提出为奖励模型领域带来了全新的突破。它通过引入推理过程,有效解决了传统奖励模型在复杂任务评估中的局限性。RRM 的训练框架无需显式推理轨迹,能够高效地利用训练数据,同时在实际应用中展现出了卓越的性能。
在实验中,RRM 不仅在多个基准测试中超越了现有的强基线模型,还在奖励引导的 N 选 1 推理和 LLM 后训练等实际应用中取得了显著的成果。它能够准确地评估复杂响应的质量,为模型的优化提供了高质量的反馈信号。然而,RRM 在处理极端稀缺数据或高度模糊问题时,仍面临一些挑战,这为未来的研究留下了空间。
未来研究方向
未来的研究可以从以下几个方向进一步探索和改进 RRM:
- • 优化 RRM 的推理过程,提高推理策略的灵活性和自适应性,使其能够根据问题特点动态调整推理模式和思考深度。
- • 扩展 RRM 在更多领域和任务中的应用,如在创意写作、艺术评论等主观性较强的领域,探索其评估能力;在多模态输入输出场景下,研究其对图像、视频等非文本数据的处理和评估方法。
- • 提高模型的可解释性和透明度,开发新的可视化工具和解释方法,使用户能够更直观地理解模型的推理过程和决策依据,增强对模型的信任和接受度。
开源资源的进一步利用
为了更深入地探索和实践 RRM,大家可以充分利用 RewardBench 的开源仓库资源。RewardBench 是一个专门用于评估奖励模型的工具,它提供了丰富的功能和资源,能够帮助研究者和开发者更高效地进行实验和研究。以下是仓库中的一些关键内容:
- 预训练模型 :仓库提供了多种经过训练的 RRM 模型,包括不同尺寸的模型(如 RRM-7B、RRM-32B)以及针对特定任务优化的模型版本。这些预训练模型使用户能够快速开始实验,无需从头训练模型,节省了大量的时间和计算资源。
- 评估工具 :RewardBench 包含了全面的评估脚本和指标,用于对奖励模型进行全面的性能测试。这些工具支持多种评估基准,如 RewardBench 基准测试和 PandaLM Test,能够帮助用户准确地衡量模型在不同任务和数据集上的表现。
- 示例代码 :仓库中提供了丰富的示例代码,涵盖了从数据预处理、模型训练到推理和评估的各个阶段。这些示例代码为用户提供了清晰的实现指导,帮助他们快速了解如何在实际项目中集成和使用 RRM。