众所周知,检索增强生成(RAG)技术已在大语言模型(LLM)应用中证明了其巨大价值,通过从外部知识库检索相关文本信息,显著提升了模型回复的准确性、时效性和可追溯性。然而,我们所感知和理解的世界并非只由文本构成:大量的现实信息和复杂语境,深刻地蕴含在图像、图表、视频等视觉内容之中。传统的 RAG 模型难以直接“看”懂并利用这些丰富的视觉信息。
如何打破文本的局限,让 RAG 系统也能像人类一样,同时结合文字和图像来理解世界、回答问题、生成内容呢?视觉 RAG 模型 (Vision RAG Models) 正是在这一前沿探索中应运而生的关键技术,代表了 RAG 能力向多模态领域的自然扩展,旨在构建能够无缝处理和推理图文混合信息的智能化应用。
这项技术涉及哪些核心原理?它与传统的文本 RAG 有何本质区别?能为我们开启哪些新的应用场景?面对这一正在快速发展并充满潜力的领域,对 Vision RAG 模型的认知,又了解多少呢……

一、什么是 Vision RAG 模型 ?
2010 年代末,随着深度学习和 Transformer 架构的成熟,视觉语言模型(如 CLIP 和 LLaVA)开始崭露头角,能够将图像与文本进行跨模态关联。2020 年代初,多模态 AI 的研究热潮推动了 RAG 技术的演进,催生了 Vision RAG 的概念。
然而,尤其在 2023-2025 年间,随着大模型(如 GPT-4V 和 Gemini)的视觉能力增强,以及企业对智能文档处理的迫切需求,Vision RAG 迅速成为学术界和产业界的热点,旨在解决跨模态数据检索与生成的核心挑战,引领 AI 向更智能、更具包容性的方向迈进。
那么,什么是 Vision RAG ?
Vision RAG(视觉检索增强生成)是一种高度先进的 AI 流水线技术,突破性地扩展了传统检索增强生成(RAG)系统的能力,不仅能够高效处理文本数据,还能无缝解析文档中的视觉内容,如图像、图表、图形等,尤其适用于 PDF 等复杂格式的文档。
与传统 RAG 系统主要聚焦于文本检索和生成不同,Vision RAG 巧妙整合了前沿的视觉语言模型(Vision-Language Models, VLMs),通过对视觉数据的精准索引、智能化检索以及深度处理,为用户带来前所未有的多模态信息整合体验。无论是回答涉及图像内容的复杂问题,还是从图表中提取关键见解,Vision RAG 都能提供更加全面、准确且富有上下文的解决方案,堪称多模态智能领域的巅峰之作。
作为一种革新性的 AI 技术,Vision RAG 凭借其卓越的功能,为多模态数据处理树立了新的标杆。以下是其令人瞩目的核心特性,具体可参考:
1. 多模态检索与生成,全面解锁信息潜力:
Vision RAG 能够无缝处理文档中的文本和视觉内容,包括图像、表格、图示等复杂元素。这不仅使其能够回答传统文本相关的问题,还能精准解析视觉信息,并生成基于多源数据的综合性回答。无论是从一张产品图片中提取细节,还是从财务报表中解读关键数据,Vision RAG 为用户提供了超越单一文本处理的强大能力,真正实现了信息的全方位挖掘与利用。
2. 直接视觉嵌入,语义保真再升级:
相较于传统的光学字符识别(OCR)技术或繁琐的手动解析方式,Vision RAG 采用先进的视觉语言模型(Vision-Language Models, VLMs)直接进行视觉嵌入。这种方法保留了图像与文本之间的语义关联和上下文信息,确保了检索结果的准确性与理解的深度。无论是复杂场景的图像分析,还是跨模态内容的语义匹配,Vision RAG 都能以其卓越的嵌入技术,为用户带来前所未有的智能体验。
3. 跨模态统一搜索,打造无缝信息桥梁:
Vision RAG 独创性地在单一向量空间内实现了跨文本和视觉模态的统一搜索与检索。这种创新设计能够捕捉混合模态内容的语义联系,从而支持更智能、更高效的查询体验。无论是搜索包含图表的技术文档,还是查询带图片的学术论文,Vision RAG 都能以流畅的语义衔接,提供一站式的检索解决方案,极大提升了信息获取的便捷性与精确性。
4. 自然交互支持,赋能人性化对话:
得益于上述特性,Vision RAG 使用户能够以自然语言提出问题,并从文本和视觉来源中无缝整合答案。这种多模态协同能力支持了更为直观、灵活的交互方式。无论是普通用户通过语音询问图片内容,还是专业人员分析多模态报告,Vision RAG 都为用户与 AI 系统之间的沟通架起了桥梁,开启了更加人性化、智能化的应用新篇章。
二、如何驾驭 Vision RAG 模型?localGPT-vision 功能解析
众所周知,在现代智能化工作流程中,集成 Vision RAG 功能已成为提升效率与准确性的关键一步。
为此,本文将为大家推荐 “localGPT-vision”,这是一款专为多模态数据处理量身打造的先进 Vision RAG 模型,完美融合了视觉理解与检索增强生成技术,为用户提供无与伦比的文档处理体验。无论是处理复杂的业务报告、扫描的 PDF 文件,还是丰富的图像内容,localGPT-vision 都能助力轻松实现智能化分析与生成。
那么,什么是 localGPT-Vision ?
通常而言,localGPT-Vision 是一款功能卓越的端到端视觉检索增强生成(Retrieval-Augmented Generation, RAG)系统,重新定义了多模态数据处理的边界。
与传统 RAG 模型依赖光学字符识别(OCR)技术的局限性不同,localGPT-Vision 凭借其创新设计,直接处理视觉文档数据,包括扫描的 PDF 文件、图像、图表等复杂内容。这种直接的视觉处理能力不仅消除了 OCR 带来的误差,还通过保留原始数据的语义完整性,显著提升了检索和生成的精度与效率。无论是从图像中提取关键信息,还是生成基于视觉内容的自然语言回答,localGPT-Vision 都能为用户带来流畅、智能的交互体验。
目前,该系统支持以下领先的视觉语言模型(Vision-Language Models, VLMs),为多样化应用场景提供了强大支持:
- Qwen2-VL-7B-Instruct:一款高效的指令优化视觉模型,适合实时交互任务。
- LLAMA-3.2-11B-Vision:强大的多模态语言模型,擅长处理复杂视觉数据。
- Pixtral-12B-2409:高性能视觉模型,优化了图像解析能力。
- Molmo-8B-O-0924:轻量化设计,适合资源受限环境下的视觉任务。
- Google Gemini:谷歌开发的跨模态巨型模型,兼具速度与精度。
- OpenAI GPT-4o:OpenAI 的旗舰多模态模型,引领视觉生成潮流。
- LLAMA-32 with Ollama:结合本地部署的灵活性,增强视觉推理能力。
凭借这些顶级模型的加持,localGPT-Vision 不仅适用于学术研究和企业文档管理,还能在智能客服、医疗影像分析等领域大展身手,为用户开启多模态智能应用的新篇章。
三、localGPT-Vision 架构实现深度解析
作为一种创新的 Vision RAG 实现范式,localGPT-Vision打破了传统 RAG 仅限于处理文本的局限,旨在赋予大型语言模型(LLMs)理解并利用图像和文档视觉信息的能力。其系统架构设计精巧,通过将视觉理解能力无缝融入到信息检索和答案生成流程中,提供了处理图文混合信息的强大能力。
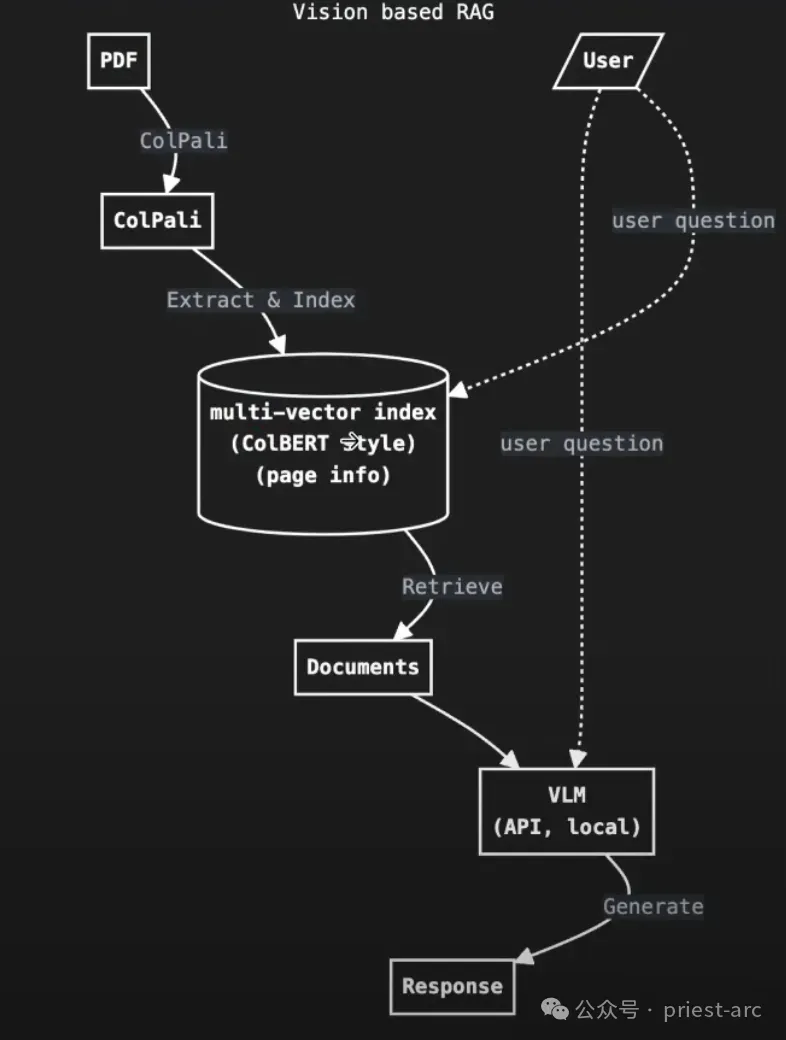
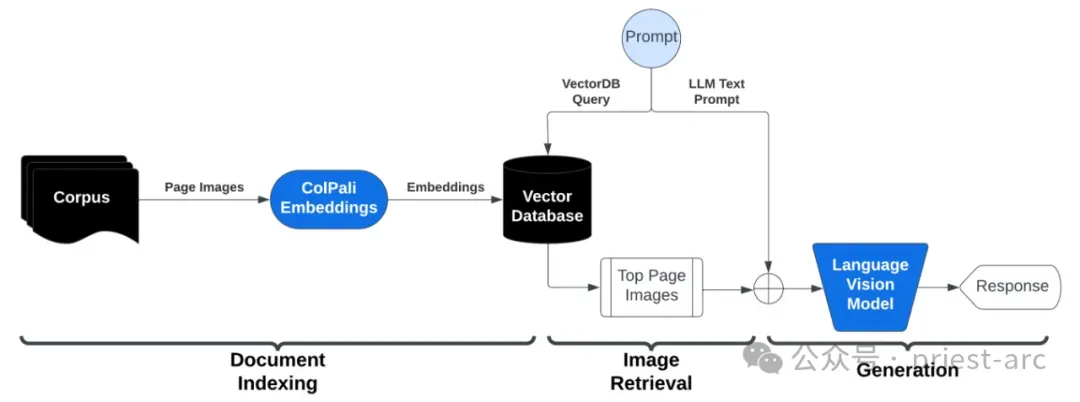
1. 视觉文档检索模块 (Visual Document Retrieval)
此模块作为 localGPT-Vision 能够“看”懂文档并基于此进行检索的基础,通过先进的视觉编码技术(视觉编码器 Colqwen 和 ColPali),将文档的视觉信息转化为可供检索的数值表示。
这些编码器的独特之处在于,设计目标是纯粹通过处理文档页面的图像表示来理解文档的语义和内容。这意味着编码器分析的是页面的像素信息,包括文字的形状、大小、位置、布局,以及图表、图像等视觉元素,从中提取高级视觉特征,形成对整个页面视觉语义的理解,而并非依赖于传统的 OCR (光学字符识别) 来提取原始文本。
2. 响应生成模块 (Response Generation)
此模块是 Vision RAG 的最终阶段,基于视觉语言模型 (Vision Language Models - VLM)负责将检索到的视觉信息与用户查询结合起来,生成最终的可读答案。与传统的仅处理文本的 LLM 不同,VLM 是一种经过训练,能够同时接收和理解图像和文本作为输入的模型。
因此,从宏观角度而言,整个流程的工作机制是先通过视觉文档检索模块高效地找出与用户查询相关的文档视觉信息,再由响应生成模块中的视觉语言模型根据这些视觉内容(以及原始查询)生成最终响应。
四、Vision RAG 模型应用场景解析
基于上述所述,Vision RAG 模型凭借其理解和整合图文信息的能力,在多个行业和应用领域展现出巨大的潜力和价值,开启了人工智能应用的新边界:
1. 医疗影像智能化分析 (Medical Imaging):
在此领域中,Vision RAG 能够革命性地提升诊断与分析的精准度,无缝整合并深度分析患者的医学扫描影像(如 CT, MRI, X光片)和相关的文本病历、检查报告、基因数据、医学文献。通过同时理解视觉病灶和文本临床信息,Vision RAG 可以为医生提供更全面、更智能的辅助诊断信息、风险评估和知识支持,有望实现更早期、更准确、更个体化的诊断和治疗方案制定。
2. 增强型文档搜索与内容总结 (Document Search):
对于包含复杂图表、流程图、公式、代码片段、图片等视觉元素的专业文档(如技术手册、财报、研究论文、合同),传统文本 RAG 能力有限。Vision RAG 能够同时看懂”并理解这些视觉内容及其伴随的文本。它能基于用户的自然语言查询,智能地检索图文混合的关键信息,并生成更全面、更准确、更忠实于原文原貌(包括视觉信息)的摘要、问答或报告,极大地提升了从复杂文档中获取知识和洞察的效率。
3. 智能化客户支持与问题诊断 (Customer Support):
在客户服务场景,用户常常通过上传产品照片、设备故障截图、环境图片或手写问题描述来寻求帮助。Vision RAG 能够理解这些用户提交的多种模态信息,并将其与产品知识库、故障排查手册、历史解决方案文本相结合。通过图文联合检索与理解,系统能够更快速、更准确地诊断用户遇到的问题,并提供基于图片和文本上下文的详细解决方案或操作步骤,极大地提升客户支持的效率、准确性和用户体验。
4. 个性化智能教育辅导 (Education):
在教育领域,Vision RAG 能够赋能更具互动性和个性化的学习体验。它能够理解包含图表、公式、插图、代码示例的学习材料或学生提交的作业图片,并结合教学文本和知识库。针对学生的具体问题,Vision RAG 可以生成同时引用并解释图表和文本的详细说明,帮助学生更好地理解抽象概念、解决难题,实现千人千面的智能答疑辅导和知识点串联。
5. 智能化电子商务体验 (E-commerce):
电商平台的核心在于产品的展示和推荐。Vision RAG 能够联合分析产品的高质量图片和详细的文本描述(包括用户评论),从而更全面、更深入地理解产品的特性、风格、材质、适用场景和潜在卖点。这有助于生成更精准、更能触达消费者需求的个性化产品推荐,支持基于图像的商品搜索,甚至可以根据用户上传的图片推荐相似或搭配的商品,显著提升用户购物体验和平台的转化率。
综上所述,Vision RAG 模型的出现,代表着人工智能在理解和生成复杂多模态数据知识的能力上迈出了具有里程碑意义的一步。它打破了长期以来 AI 对文本信息的过度依赖,开始真正地整合并理解来自视觉世界和文本世界的丰富信息,实现了跨模态的知识融合与推理。
Happy Coding ~
Reference :[1] https://github.com/PromtEngineer/localGPT-Vision
Adiós !


