今天凌晨,微软在官网分享了自研的三大创新算法,以帮助大模型增强其推理能力。
无论你是小参数或者是大参数模型玩家,都能从rStar-Math、LIPS 、CPL这三大算法获益,突破推理瓶颈,极大增强模型的数学推理和思考链的能力。
rStar-Math
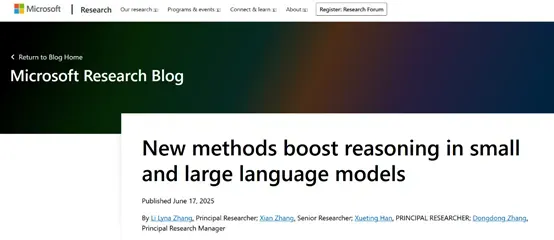
rStar-Math算法主要通过蒙特卡洛树搜索(MCTS)实现深度思考。MCTS 是一种用于决策过程的搜索算法,通过模拟多个可能的路径来评估每个步骤的价值。在rStar-Math算法中,MCTS 被用来生成高质量的推理轨迹,并通过一个基于SLM的奖励模型进行评估。
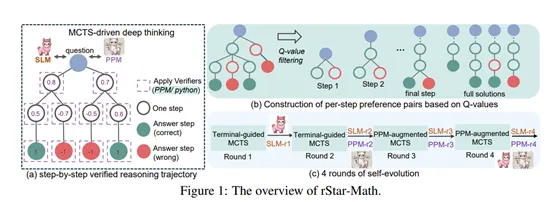
在传统的推理方法中,语言模型生成的自然语言推理轨迹往往存在错误或不相关的内容,尤其是在复杂的数学问题中。为了解决这一问题,rStar-Math 引入了代码增强的CoT方法。大模型在生成每个推理步骤时,会同时生成对应的 Python 代码。
这些代码不仅用于验证推理步骤的正确性,还能够通过执行结果来筛选出高质量的生成内容。只有那些 Python 代码能够成功执行的生成内容才会被保留,从而确保中间步骤的正确性。

此外,传统的奖励模型训练中,直接使用 Q 值作为奖励标签是一种常见的方法,但这种方法存在明显的局限性。Q 值虽然能够反映步骤的整体质量,但它们带有噪声,无法精确地评估每个步骤的优劣。
为了解决这一难题,rStar-Math 提出了一种新的训练方法,通过构建基于 Q 值的正负偏好对来训练PPM。对于每个推理步骤,模型会选择 Q 值最高的两个步骤作为正样本,选择 Q 值最低的两个步骤作为负样本。
通过这种方式,PPM 能够学习到如何区分高质量和低质量的推理步骤,从而提供更准确的奖励信号。这种方法避免了直接使用 Q 值作为奖励标签的噪声问题,显著提高了奖励模型的精度和可靠性。
论文地址:https://arxiv.org/pdf/2501.04519
rStar-Math的自我进化方法也是其核心优势之一。通过四轮自我进化,策略模型和PPM 从头开始逐步构建,生成的训练数据质量不断提高,覆盖的问题难度也逐渐增加。
在每一轮中,使用最新的策略模型和 PPM进行MCTS,生成高质量的推理轨迹,并用这些轨迹训练更强的策略模型和PPM。
LIPS
LIPS算法主要用于增强数学推理,其核心思想是将数学证明过程中的策略分为缩放和重写两大类。缩放策略通过符号工具实现,利用有限的不等式引理库对当前目标进行细化,而重写策略则由大模型负责生成,通过等价变换将问题转化为更易于解决的形式。
在缩放策略方面,LIPS算法通过符号工具实现,利用有限的不等式引理库对当前目标进行细化。例如,通过AM-GM不等式,算术平均数大于等于几何平均数对目标中的某些项进行缩放。但缩放策略可能会引入无效的子目标,所以需要通过符号工具如SMT求解器检查反例,从而过滤掉无效的缩放策略。
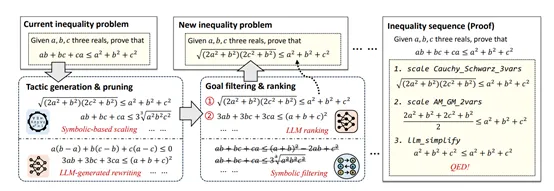
在重写策略方面,LIPS算法由大模型负责生成,通过设计一系列提示引导大模型对当前目标进行等价变换。例如,通过简化、重新排列或消去分母等操作将目标转化为更易于处理的形式。由于重写策略的空间是无限的,大模型的数学直觉在这里发挥了关键作用,能够从大量可能的变换中筛选出最有希望的策略。

在目标过滤与排序方面,LIPS算法采用了两个阶段:符号过滤和神经排序。缩放和重写策略生成的新目标集合需要进一步筛选和排序,以确定最有希望的证明路径。首先,通过符号过滤阶段,利用不等式的齐次性和解耦性来评估每个目标的潜力。
论文地址:https://arxiv.org/pdf/2502.13834
齐次性表示不等式两边的次数相同,而解耦性则衡量不等式中混合变量项的数量。通过这些指标,可以快速排除那些不太可能被证明的目标。其次,在神经排序阶段,对于经过符号过滤后的前k个目标,利用大模型进行最终排序。
CPL
传统的强化学习方法虽然在特定任务上取得了进展,但在跨任务泛化方面存在不足。此外,大模型的推理空间是无限的,这使得在其中寻找有效的推理路径变得极为困难。
例如,在数学问题解决中,模型需要在众多可能的解题步骤中找到最优路径,而在代码生成任务中,模型需要在复杂的逻辑结构中进行有效的探索。

为了解决这些难题,微软提出了CPL算法,一种基于关键计划步骤学习的方法,旨在通过在高层次抽象计划空间中进行搜索,提升模型的泛化能力和推理性能。
在CPL算法中,计划空间搜索是第一步,也是至关重要的一步。与传统的解决方案搜索不同,计划空间搜索关注的是高层次的抽象计划,而不是具体的解决方案。
例如,在解决一个数学问题时,模型首先会生成一个逐步解决问题的计划,而不是直接生成具体的数学公式。这种计划可以包括确定需要应用哪些知识、如何分解问题等抽象思维步骤。通过这种方式,模型能够学习到更通用的、与任务无关的技能,从而提高其在不同任务中的泛化能力。
在生成了多样化的计划步骤后,CPL的第二步是通过Step-APO学习关键计划步骤。Step-APO是基于Direct Preference Optimization(DPO)的一种改进方法,它通过引入优势估计来优化步骤偏好。
Step-APO利用MCTS过程中获得的优势估计,为每一对步骤偏好赋予不同的权重,从而让模型能够更有效地识别出哪些步骤对推理能力的提升更为关键。
论文地址:https://arxiv.org/pdf/2409.08642
例如,在一个复杂的推理任务中,模型可能会发现某些步骤虽然在表面上看起来合理,但实际上对最终结果的贡献较小,而Step-APO能够帮助模型识别并强化那些真正重要的步骤。


