LaTeX 公式的光学字符识别(OCR)是科学文献数字化与智能处理的基础环节,尽管该领域取得了一定进展,现有方法在真实科学文献处理时仍面临诸多挑战:
其一,主流方法及公开数据集多聚焦于结构简单、符号单一的公式,难以覆盖多学科、高难度的复杂公式;其二,实际文档中广泛存在的多行公式、长公式、分段公式及页面级复杂排版等情况尚未得到充分关注与处理;其三,大多数方法依赖专用模型,通常需要针对特定任务进行专门设计,难以实现通用性和扩展性。
针对上述挑战,DocTron 团队提出了系统性解决方案。
首先,针对现有数据集覆盖面有限、结构单一的问题,构建了涵盖多学科、多结构的大规模高难度数据集 CSFormula,包含行级、段落级和页面级的复杂排版。
其次,团队提出的 DocTron-Formula 模型突破了对特定结构建模的依赖,采用通用大模型驱动的复杂公式识别方法,仅需简单微调即可适配多样化应用场景。
最后,相比于最优的定制化公式识别模型,该方法不仅在主流的开源评测中取得了优秀的性能表现,在实际应用中常见的页面级、段落级复杂排版场景中也取得了显著优势,推动了公式识别的应用边界。

DocTron 是一个在通用视觉语言模型架构上实现结构化内容解析和理解的开源项目,而无需定制化的模块开发,覆盖通用文档、学科公式、图表代码等场景。
- 论文标题:DocTron-Formula: Generalized Formula Recognition in Complex and Structured Scenarios
- 论文链接:https://arxiv.org/abs/2508.00311
- Github 链接:https://github.com/DocTron-hub/DocTron-Formula
- 项目开源地址:https://huggingface.co/DocTron
创新点与技术突破
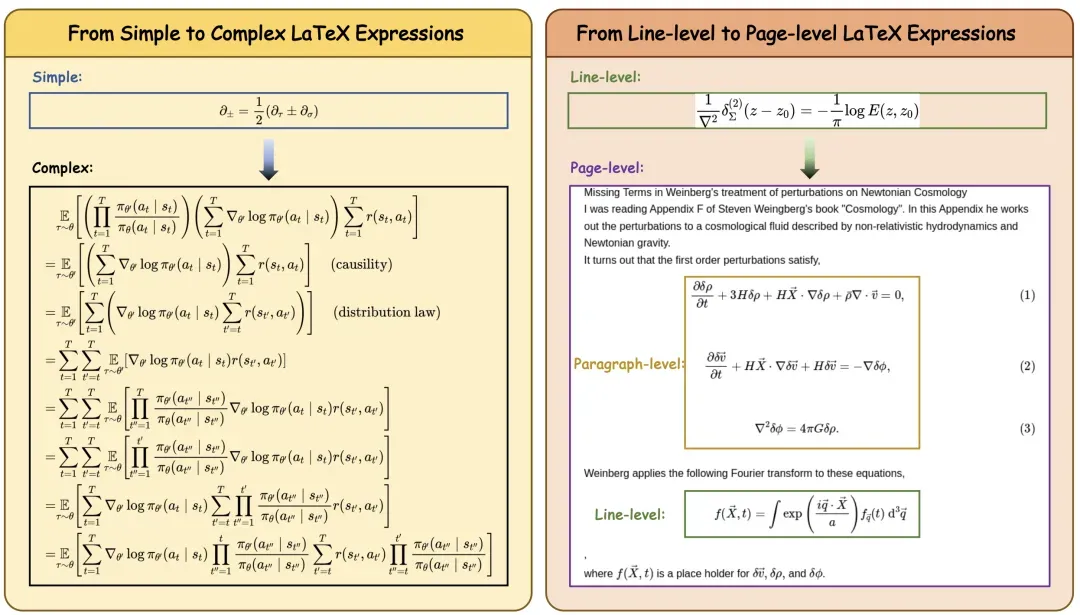
(1)高难度多结构数据集构建。研究团队自主设计高效的数据采集与处理流程,系统性地从高质量学术资源中收集、清洗并整理了大量多学科的复杂公式样本,构建了 CSFormula 数据集。
该数据集涵盖数学、物理、化学等领域,包含行级、段落级和页面级的复杂排版,更真实地反映了文献中公式的多样性与挑战性,为模型训练与评测提供了坚实基础。
(2)通用大模型驱动的复杂公式识别。研究团队突破了对结构定制和专用架构的依赖,直接利用 Qwen2.5-VL 等通用大规模多模态预训练模型,并通过在高难度数据集上的有监督微调实现领域适配。
实验结果表明,大模型凭借强大的知识迁移和结构泛化能力,仅需简单微调即可在复杂场景下取得 SOTA 性能,无需繁琐的工程设计或人工规则,显著提升了复杂公式识别的通用性和实用性。
实验结果与性能表现
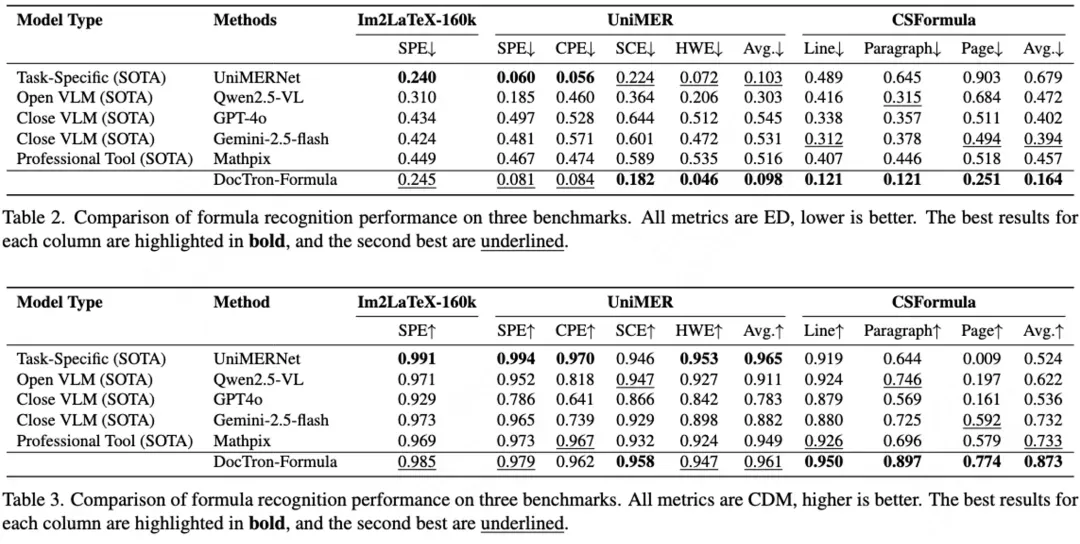
实验结果显示,DocTron-Formula 在各类公开基准测试及自建 LaTeX 公式识别数据集上均表现出色。在编辑距离和 CDM 两个指标下,不仅超越了现有专业工具 Mathpix,在多个任务上也优于 GPT-4o 和 Gemini-2.5-flash 等主流闭源大模型。
研究意义与应用前景
本研究不仅推动了复杂公式识别技术的发展,也为相关领域开辟了新的研究思路:
- 首次系统构建了覆盖多学科、多结构的大规模高难度数据集 CSFormula,为复杂公式识别的模型训练和评测提供了坚实的数据支撑;
- 验证了通用大模型(如 Qwen2.5-VL)在复杂公式识别任务中的强大适应性和泛化能力,显著简化了模型开发流程,减少了对专用设计和人工规则的依赖;
在应用层面,DocTron-Formula 有望服务于科学文献解析、学术知识检索和教育资源智能化等多元场景,为科研、教育和信息服务等领域的自动化与智能化提供有力支撑。
结论
DocTron-Formula推动了学科公式理解在行级、段落级、页面级复杂排版场景的应用,强调无需定制化的算法模块,通过高质量数据的构建和通用模型训练,实现开源评测和现实应用评测的全面提升。


