这篇论文的作者来自伊利诺伊大学香槟分校(UIUC)张令明老师团队,包括:杨晨源,四年级博士生,研究方向是基于 AI 大模型的软件系统可靠性保障;赵子杰,四年级博士生,研究方向是模糊测试等软件工程技术与 AI 大模型的结合;谢子晨,科研实习生,目前为弗吉尼亚大学一年级博士生;李皓宇,科研实习生,目前为 UIUC 一年级博士生。张令明老师现任 UIUC 计算机系副教授,主要从事软件工程、机器学习、代码大模型的相关研究。
想象一下,大语言模型不仅能生成代码,还能通过静态分析看代码找漏洞:在千万行的 Linux 内核代码中挖出 92 个长期潜伏的真实缺陷 —— 这也可能是 LLM 首次在 Linux 内核中发现如此多的实际漏洞。最近的报道指出,OpenAI 的 o3 模型已经在 Linux 内核中发现了一个零日漏洞;而本文的 KNighter 更进一步,通过自动生成静态分析检查器,把模型的洞察沉淀为工程可用、用户可见的逻辑规则,实现了规模化的软件漏铜、缺陷挖掘。
一句话亮点:别再让大模型直接扫几千万行代码了 —— 让它从历史修复补丁学模式、再自动合成静态分析检查器。KNighter 把 LLM 的归纳能力沉淀为可编译、可维护、可解释的规则实现,在 Linux 内核中挖出 92 个长期潜伏漏洞。这一次,大模型是编译器能用、工程师能复用的缺陷检查器作者。

- 论文标题:KNighter: Transforming Static Analysis with LLM-Synthesized Checkers
- 论文地址:https://arxiv.org/pdf/2503.09002
- 开源链接:https://github.com/ise-uiuc/KNighter
- 发表会议:SOSP 2025
背景与痛点
静态分析可以在不运行程序的情况下遍历所有可能的代码路径,是系统级软件缺陷检测的利器。然而传统的静态分析器需要专家手工编写规则,耗时费力、扩展难、维护成本高,往往只能覆盖有限的预定义模式。
直接让大语言模型扫描庞大工程(如 Linux 内核)听起来很酷,但现实并不友好:需要将成千上万行代码塞进有限的上下文,还要承受显著的计算成本和幻觉风险。
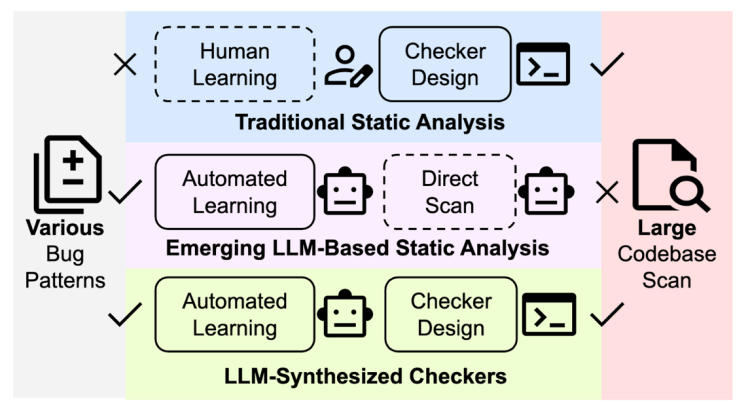
核心洞察
KNighter 的关键转变是:「不让大模型直接下结论,而是让它生成能够自动判定缺陷的检查器。」
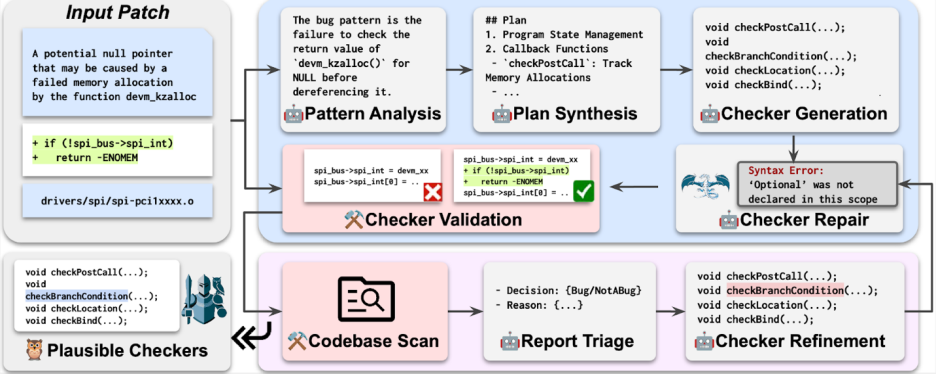
补丁蒸馏:利用开源项目过往的修复补丁,提炼出缺陷模式与修复意图,作为教科书。
多阶段合成:将 “写一个静态分析检查器” 拆解成可控的小任务,先让模型分析漏洞缺陷模式和程序状态,再指导它生成包含状态建模、回调挂载与告警触发等代码的检查器框架,最终得到可编译的 C++ 检查器。
正确性验证与自动化精炼:在原始补丁上回放检查器,确认能在修复前报警、修复后消警,并通过迭代优化降低误报。
规模化运行:合成好的检查器可直接接入 CI 流水线,在全库范围长期服役,并随着新补丁不断迭代升级。
神经符号的新范式
许多此前的「AI + 程序分析」工作把模型当作标注器或辅助工具:模型预测一些可疑 API、source–sink 组合,再由专家写规则补齐。然而 KNighter 走了一步更大胆的路 —— 让大模型直接生成结构化的检查器代码。
在这个范式中,模型负责归纳跨项目、跨语境的缺陷模式和修复意图;静态分析器框架负责编译、类型检查和路径覆盖。二者的结合带来了几大好处:
- 可落地:合成出来的检查器是真正的代码,可以进版本库、进 CI,拥有明确的状态转移和告警逻辑,便于代码审查与演进。
- 稳定可追溯:告警伴随可解释的状态机与触发点,方便开发者定位根因。
- 复用与组合:不同检查器像乐高模块,可以针对资源管理、错误传播、并发协议等不同缺陷协议组合使用。
实验与影响
研究团队在 Linux 内核上验证了 KNighter 的效果。将历史补丁作为训练源,模型合成的检查器成功挖掘出 92 个长期潜伏的漏洞,其中 77 个已被维护者确认,57 个已修复,30 个获得了 CVE 编号。这些漏洞平均潜伏时间超过 4 年,可见其难以通过现有工具发现。
相较于直接让 LLM「扫代码」,这种方法成本更低,稳定性更高:一次合成的检查器可以长期复用,其运行成本接近传统静态分析;每个告警都附带精确的状态机和触发点,便于评审与补丁制作;当新的缺陷补丁出现时,只需再合成新的检查器即可增量升级。

落地建议
- 接入补丁流:企业 / 社区可以在每次合并修复补丁时,自动触发 KNighter 的模式挖掘和检查器生成,逐步积累规则库。
- 从高风险场景起步:先针对资源释放、错误传播、并发锁等高危缺陷生成种子检查器,再逐步扩展到其他子系统。
- 与现有工具联动:将合成的检查器与抽象解释、约束求解等形式化技术结合,可以进一步压缩误报。
结语
大模型的推理能力正在快速进化,但真正的工业落地需要可维护、可审计的软件产品。KNighter 展示了一条朴素却强大的路径:让修复补丁成为老师,让大模型写出能长期服役的静态检查器。我们相信,在这个新的范式下,AI 静态分析将真正具备规模化、可追溯、可维护的工业生命力,也将为大模型驱动的软件开发提供强有力的质量保证。
我们团队正在开发更强大的大模型漏洞检测解决方案,敬请期待。也欢迎感兴趣的同学加入我们的团队!


