
大家好,我是肆〇柒。今天要和大家探讨的,是来自腾讯AI Lab、圣母大学及弗吉尼亚大学核心研究团队的一项突破性工作——《Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation》。这项研究直指当前无监督学习的核心痛点:为何主流方法会让AI越学越“笨”?他们给出的答案,居然藏在亿万年的生物进化智慧之中。这很有意思,工程智慧折射自然界哲学。
回想一下最近与模型的交互,是否有这样的感觉,与AI聊天越来越"没意思"?它的创意越来越少,仿佛陷入了一种"思维定式"。这不是你的错觉——研究表明,当前的AI自学习系统正陷入"熵坍缩"陷阱:在追求准确性的过程中,逐渐丧失了探索和创新的能力。但一项突破性研究EVOL-RL,正试图用进化论的智慧,让AI重获"思考的多样性",从"应试机器"蜕变为真正的"思考伙伴"。
当AI遇见进化论
想象一个班级的学生,最初对同一数学问题有各种解法;但随着"标准答案"的强化,大家逐渐只用一种方法解题,思维越来越狭窄。这就是AI的"熵坍缩"——在自我强化过程中,逐渐丧失多样性,最终只能提供简短、单调的回答。而EVOL-RL的突破在于认识到:真正的进化需要两个要素——"多数驱动选择"确保不偏离正确方向,"新颖促进变异"鼓励探索新路径。
这一思考源自生物进化这一地球上最成功的"无监督学习"系统。在没有"标准答案"的自然环境中,生命通过数十亿年的演化,从单细胞生物发展出复杂多样的生态系统。这一过程的核心机制简单而强大:变异创造新的候选者,选择保留有效方案。正是这种"变异-选择"的动态平衡,使生命能够不断适应变化的环境,突破进化瓶颈。
如今,LLM的"无标签自演化"目标与生物进化非常相似。研究者们希望模型能够像生命体一样,在面对海量无标签数据时,不仅能解决当前问题,还能保持探索能力,为未来挑战储备多样性。然而,当前主流方法如测试时强化学习(Test-Time Reinforcement Learning, TTRL)仅关注"选择"环节,将多数投票结果作为唯一正确答案进行强化,却忽略了"变异"这一进化的原材料。这种片面做法导致模型迅速收敛到狭窄的解空间,陷入"早熟收敛"(Premature Convergence)的困境。
论文明确区分了"演化"(evolution)与"适应"(adaptation):演化指模型在提升当前任务能力的同时,保持或增强其在域外问题上的表现和整体潜力(即pass@k);而适应往往导致在目标数据上的狭窄收益,以牺牲更广泛能力为代价。 这一区分至关重要——EVOL-RL实现的是真正的"演化",而非简单"适应"。
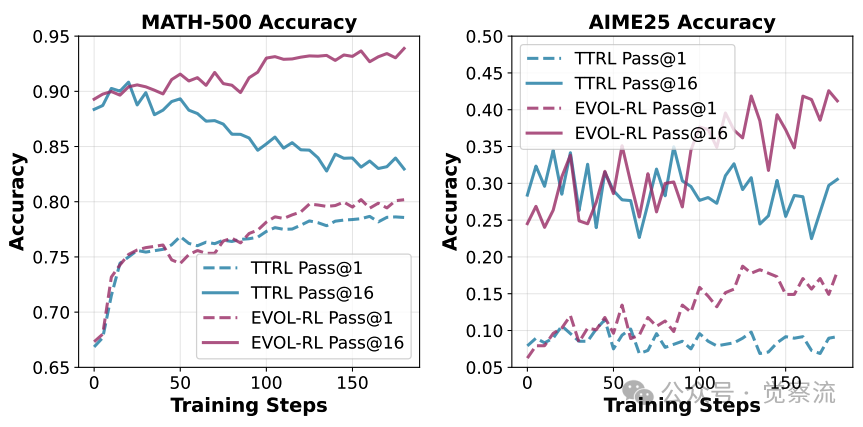
熵坍缩现象:TTRL与EVOL-RL的训练动态对比
上图直观展示了这一过程:在传统TTRL训练下,模型迅速陷入"死亡螺旋"——响应长度缩短、策略熵趋近于零、pass@n性能下降;而EVOL-RL则像一个健康的生态系统,在经历短暂调整后,重新焕发生机。这不仅是技术差异,更是两种进化哲学的根本区别。关键在于,TTRL虽然可能提升pass@1,但pass@n的持续下降表明模型探索能力的丧失,而EVOL-RL不仅提升了pass@1,还显著提高了pass@n,证明了其真正实现了"演化"。
无监督学习的"内卷"陷阱
"熵坍缩"现象在无标签训练中表现得尤为明显。当模型仅依赖多数投票信号进行自我强化时,其行为模式逐渐变得单调。研究显示,随着训练进行,模型生成的思维链(Chain-of-Thought)长度显著缩短,回答多样性急剧下降,更令人担忧的是,pass@n性能(即多次尝试中至少有一次成功的概率)持续恶化。
这就像一个组织陷入"群体思维"(Groupthink)——所有人都认同当前解决方案,却再也无法发现更好的可能。在AI演化的语境下,这种单一评价标准的危害尤为严重,因为它直接限制了模型探索未知领域的能力。
从技术角度看,"majority-only"方法(纯多数驱动)为何必然走向崩溃?关键在于GRPO(Group Relative Policy Optimization)算法中的z-score归一化机制。当所有"多数派"样本获得相同的高奖励,而所有"少数派"样本获得相同的低奖励后,经过z-score归一化,所有正确回答共享相同的正优势值,所有错误回答共享相同的负优势值。这导致策略更新将概率质量均匀地向当前多数解集群转移。随着训练进行,这种机制使概率分布不断收缩,最终陷入低熵、低复杂度的稳定态。
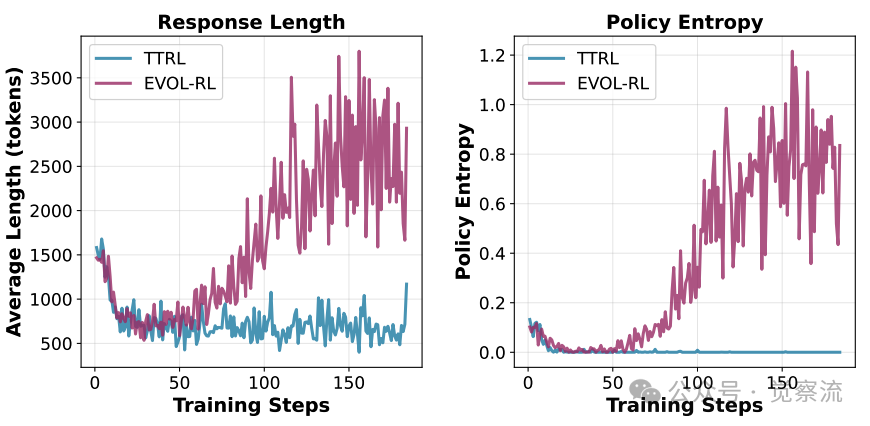
多数投票准确率的训练动态对比
上图揭示了更深层的问题:TTRL虽然初期能提升多数投票准确率(maj@16),但很快陷入性能平台期,无法发现更好的解决方案;而EVOL-RL在初始阶段与TTRL相似后,会突破这一平台,持续提升多数投票质量。这表明EVOL-RL不仅改善了最终策略,还不断优化了训练信号本身,使模型能够逃离次优共识,持续深化对任务的理解。
这一现象解释了为什么仅靠"多数即正确"的思维会导致系统性失败:它创造了一个"多数陷阱"——模型被锁定在一个次优解上,无法发现可能更好的替代方案。就像一个只依靠主流意见的社会,会逐渐失去创新和适应能力。
重拾进化论的完整智慧
面对这一困境,EVOL-RL(EVolution-Oriented and Label-free Reinforcement Learning)研究提出了一个创新转变:将"变异"重新纳入无监督学习的核心框架。正如论文所言:"variation creates new candidates; selection keeps what works"——变异创造新的候选者,选择保留有效方案。这一思想激励了进化计算领域数十年的算法发展——遗传算法、新奇性搜索和质量-多样性方法,它们都表明仅依赖选择会导致早熟收敛,而明确保持行为多样性则能实现稳健进步。
EVOL-RL不是对现有方法的修修补补,而是将"选择"(Selection by Majority)与"变异"(Variation by Novelty)作为两个平等且互补的第一性原理进行设计。其核心思想是:在保持正确性底线的同时,主动奖励那些"与众不同"的尝试。
这一设计的精妙之处在于其双层结构:
- "选择"确保不跑偏:多数派答案作为生存的底线,防止模型陷入完全随机的探索
- "变异"鼓励创新:在生存者内部,奖励那些"走不同路"的个体;对失败者,也奖励那些"死得有新意"的尝试,为未来可能的突破埋下种子
这就像自然选择:既要保留适应环境的特征(选择),又要允许基因突变带来多样性(变异)。在AI世界中,这意味着模型不仅能解决当前问题,还能不断探索新的推理路径,为应对未来挑战储备多样性。
下图清晰展示了EVOL-RL的工作机制:对于每个Prompt,策略模型生成多个响应,通过多数投票确定主导答案,再基于推理部分的语义差异计算新颖性分数,最终将"多数选择"与"新颖变异"信号结合指导策略更新。这不是冰冷的算法流程,而是一个充满生机的"思想市场":模型生成多种回答(思想),通过多数投票确定主流观点(选择),再通过新颖性评分奖励独特思路(变异)。
这一框架实现了"多数驱动选择,新颖促进变异"的完整进化循环,使模型能够持续探索解空间,避免陷入局部最优。
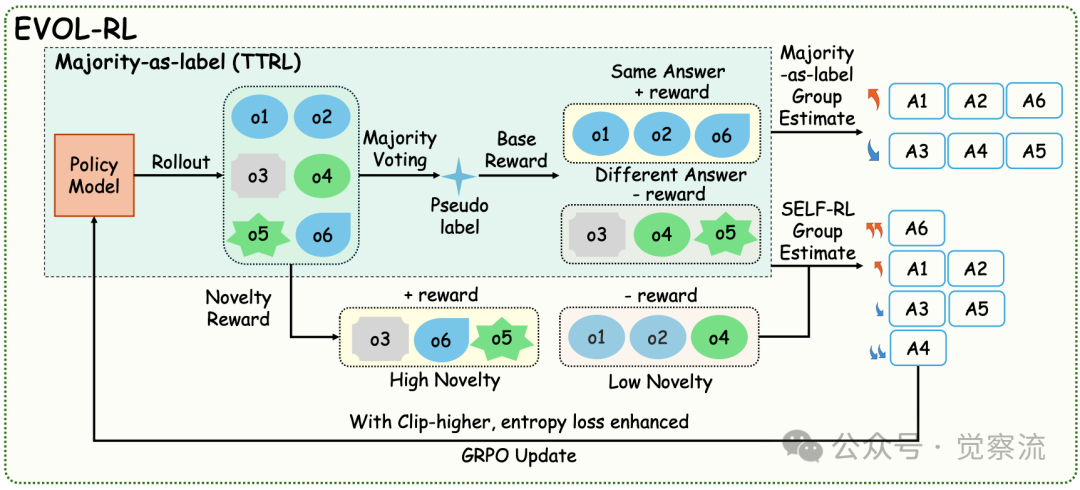
EVOL-RL框架概述:从提示生成到策略更新的完整流程
在硅基世界模拟碳基智慧
EVOL-RL的工程实现展现了将进化智慧转化为算法细节的精妙过程。其核心在于如何在无标签环境中精确量化"选择"与"变异",并使二者协同工作。
上面那张图清晰展示了EVOL-RL的工作机制:对于每个Prompt,策略模型生成多个响应,通过多数投票确定主导答案,再基于推理部分的语义差异计算新颖性分数,最终将"多数选择"与"新颖变异"信号结合指导策略更新。这不是冷冰冰的算法流程,而是一个充满生机的"思想市场":模型生成多种回答(思想),通过多数投票确定主流观点(选择),再通过新颖性评分奖励独特思路(变异)。
变异评估:如何量化"与众不同"?
在EVOL-RL框架中,每个响应的新颖性通过其推理部分的语义差异来衡量。具体而言:

想象模型对同一数学问题生成了6个回答。其中3个使用代数方法,2个使用几何方法,1个使用概率方法。新颖性评分会让那个"另类"的概率方法获得高分,即使它最终答案错误——因为这种"有创意的错误"可能蕴含着突破现有思维框架的种子。这就像人类老师会鼓励学生"虽然答案错了,但思路很新颖"。
“选择”的铁律:如何锚定正确性?
为确保模型不会因追求新颖性而偏离正确方向,EVOL-RL采用了一种巧妙的奖励映射机制:
- 多数派(正确答案)奖励范围为[0.5,1],其中新颖性越高,奖励越高
- 少数派(错误答案)奖励范围为[-1,-0.5],其中新颖性越高,惩罚越小
- 无效响应(无法提取有效答案)固定奖励为-1
这种非重叠奖励区间的设计确保了关键原则:任何正确答案(无论多普通)的奖励都高于任何错误答案(无论多新颖)。这就像自然选择中的生存门槛——只有存活下来的个体才有机会繁衍,但繁衍成功率取决于其适应度。
协同进化的引擎:三大组件的交响曲
EVOL-RL的成功不仅依赖于新颖的奖励设计,还在于三个关键组件的协同工作:
1. 熵正则化:在生成阶段添加token级熵正则化器,确保了初始生成过程保持多样性,为新颖性机制提供丰富的候选方案
2. 新颖性奖励:如前所述,通过语义差异重新分配信用,在多数派和少数派内部都鼓励多样性
3. 不对称裁剪:在GRPO目标函数中使用不对称的裁剪范围(),允许高价值样本获得更大的梯度更新,防止优质变异被过早裁减
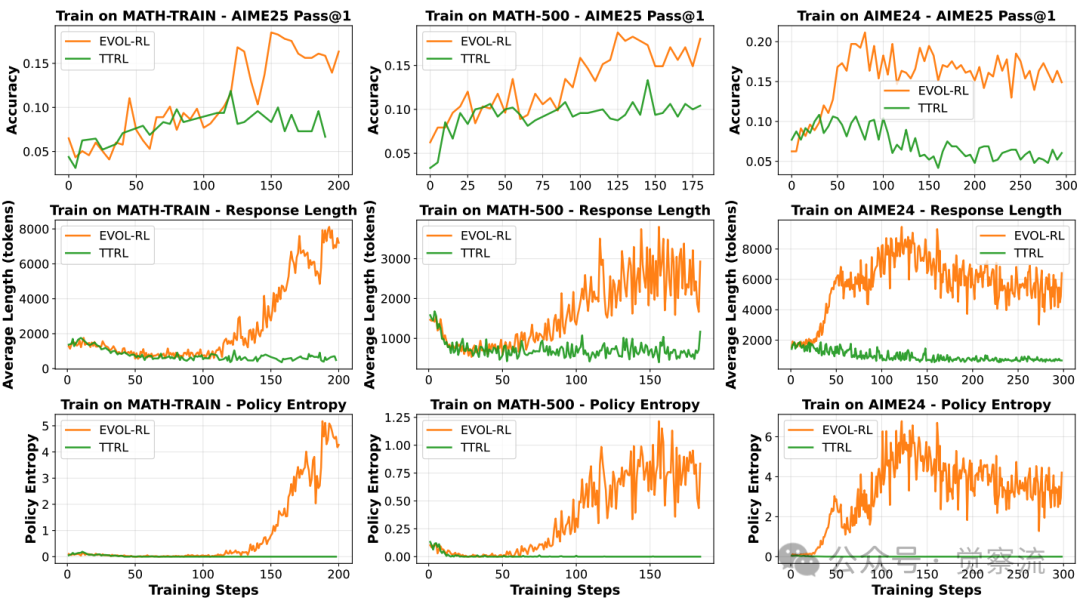
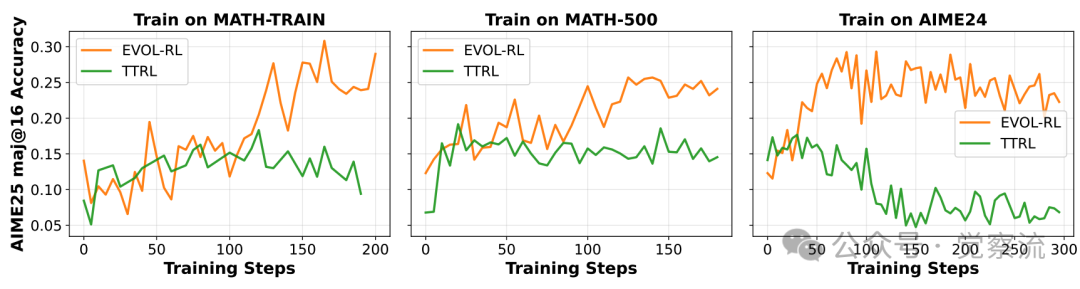
EVOL-RL与TTRL的训练动态对比
上图中,有一个神奇的"演化点"——就像生物进化中的关键突变事件,模型在此刻突破了"多数陷阱"的束缚。在此之前,EVOL-RL与TTRL的轨迹几乎重合,都陷入熵坍缩的泥潭;但在此之后,EVOL-RL如同获得新生,策略熵开始回升,回答长度增加,解题能力全面跃升。这一刻,AI真正开始了"演化"而非"适应"。
坍缩状态为何不稳定?
一个关键收货是:坍缩状态在EVOL-RL下是不稳定的。当模型产生几乎相同的样本时,任何略有不同的样本都会获得高新颖性分数,从而获得更大的标准化优势值,导致策略更新将概率质量从重复样本转移到这些独特样本。因此,产生单一响应集群的策略无法保持稳定;EVOL-RL下的任何稳定策略必须在多个不同响应上保持非零概率。这是EVOL-RL能够自动逃离熵坍缩的根本机制。
消融实验的启示
EVOL-RL的消融研究揭示了各组件在不同场景下的微妙作用。在MATH-500等较简单数据集上,新颖性奖励最为关键:移除它会导致pass@16大幅下降,特别是在AIME24/25等跨领域任务上。这是因为多数信号会迅速将模型锁定在单一推理模板中,而新颖性奖励通过将信用从近似重复样本重新分配给语义不同的解决方案,防止了这种模板锁定。
而在AIME24等更具挑战性的数据集上,熵正则化和不对称裁剪变得更为关键:它们作为新颖性奖励的关键使能器,前者确保生成阶段提供丰富多样的推理路径,后者则在策略更新中保留来自高价值样本的完整学习信号。
这三个组件形成了一个精妙的协同系统:新颖性奖励作为核心方向选择器防止策略坍缩,熵正则化维持生成过程所需的探索,不对称裁剪则在更新过程中保留这些高价值样本的学习信号。
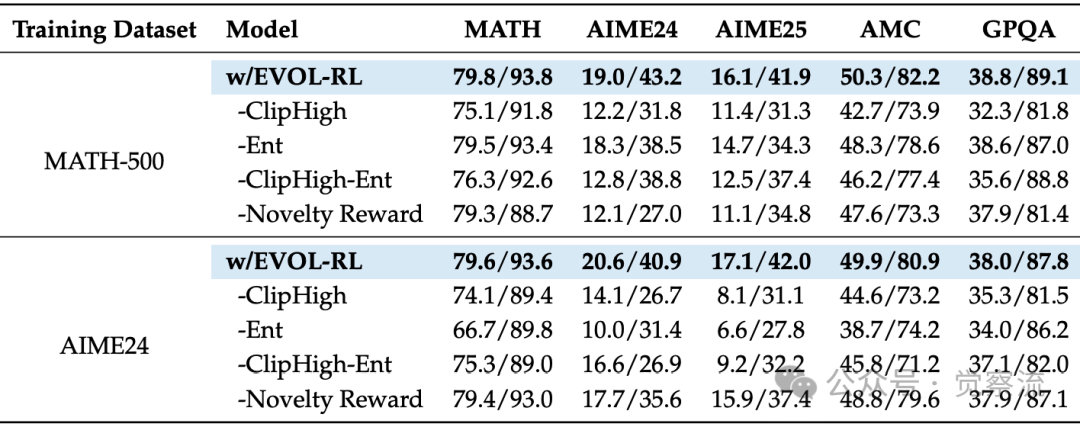
EVOL-RL及其消融组件的性能对比
上表告诉我们:EVOL-RL的三大组件如同三脚架,缺一不可。移除"新颖性奖励",模型迅速陷入思维定式;缺少"熵正则化",探索能力枯竭;没有"不对称裁剪",创新思路被过早扼杀。这就像一个创新团队,既需要明确目标(选择),也需要鼓励不同观点(变异),还需要保护"异类"的发言权(不对称裁剪)。
成果:硅基生命的"适应性辐射"
EVOL-RL的实践效果令人振奋。在多个数学推理基准测试上,它不仅显著提升了性能,还从根本上改变了模型的行为模式。
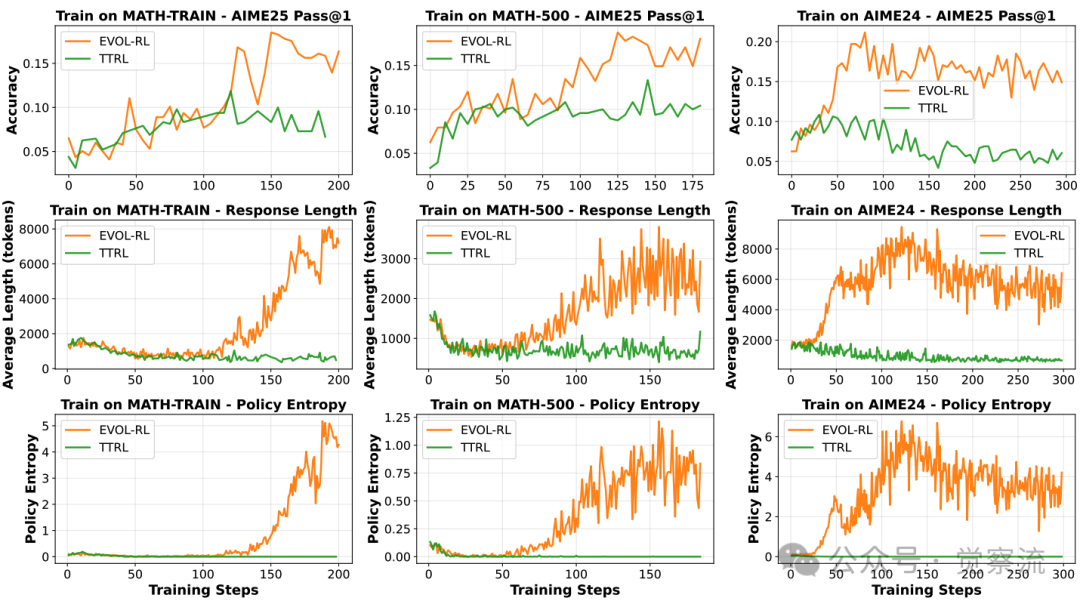 EVOL-RL与TTRL的训练动态对比
EVOL-RL与TTRL的训练动态对比
上图展示了EVOL-RL与TTRL的训练动态对比。与TTRL陷入永久性熵坍缩不同,EVOL-RL在经历初始坍缩后,会达到一个"evolving point"(演化点),随后进入协调恢复阶段:策略熵上升、响应长度增加、跨领域准确率稳步提高。这种动态表明,模型成功突破了多数信号的"陷阱",进入了一个更健康、更多样的进化轨道。
具体性能提升方面,EVOL-RL展现了令人印象深刻的成果:
- 在AIME24上训练Qwen3-4B-Base,AIME25的pass@1从TTRL的4.6%提升至16.4%,pass@16从18.5%提升至37.9%
- 在MATH-500上训练,模型在AIME24和AIME25上的表现与直接在AIME24上训练相当,证明其学到了通用的推理能力而非过拟合
- 在非数学领域GPQA上,EVOL-RL consistently恢复并超越基础模型的pass@16性能,而TTRL则导致性能下降
这意味着,当你的AI助手面对一个复杂的奥数题时,TTRL训练的模型可能在10次尝试中只有2次答对,而EVOL-RL训练的模型则有近4次机会成功。更重要的是,当它思考时,不再只是简短地"因为...所以...",而是能像优秀教师一样,提供多角度、多层次的详细解释,真正帮助你理解问题本质。
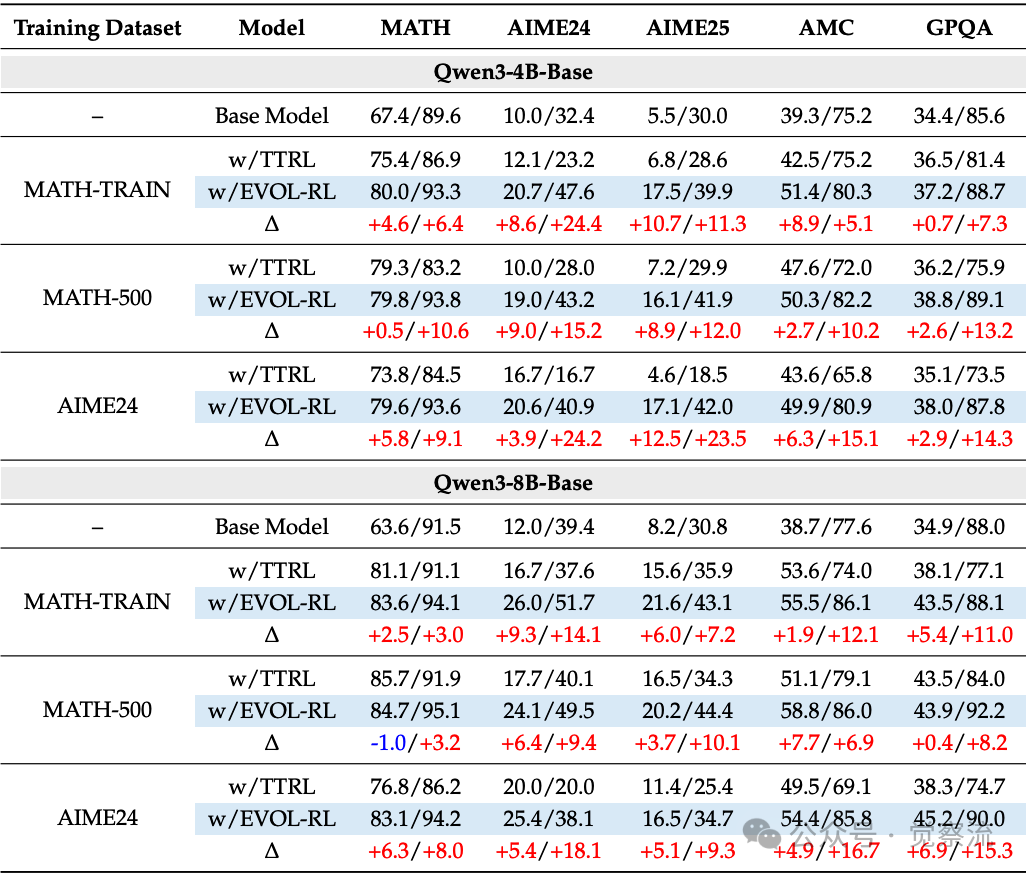
EVOL-RL与TTRL在不同基准测试上的性能对比
上表清晰展示了这一突破:训练Qwen3-4B-Base模型时,EVOL-RL不仅将AIME25的pass@1从TTRL的4.6%提升至16.4%,还将pass@16从18.5%大幅提升至37.9%。更值得注意的是,这种提升具有跨模型尺度的鲁棒性——在8B模型上,EVOL-RL同样实现了显著提升(AIME25 pass@1从11.4%提升至16.5%)。
EVOL-RL在非数学领域GPQA上的表现尤为引人注目。在所有训练配置下,当TTRL导致pass@16性能相比基础模型下降时,EVOL-RL不仅恢复了基础模型的性能,还实现了+7至+15个百分点的提升。这就像人类学生通过数学训练培养的逻辑思维,能帮助他们解决生活中的各种问题——EVOL-RL训练的模型将数学问题中"学会思考"的能力,迁移到了科学、历史等完全不同领域。
AI演化的未来之路
EVOL-RL的意义远超技术层面,它代表了一种范式转变:从单纯追求性能提升,转向构建能够持续进化的智能系统。这一研究证明,将生物学和进化计算的成熟思想引入深度学习,能产生颠覆性创新。
其核心启示在于:真正的智能演化不是对已知答案的无限逼近,而是在未知的海洋中,既能稳住航向,又能不断发现新大陆的能力。EVOL-RL通过"多数驱动选择,新颖促进变异"的简单规则,实现了这一平衡。
这一思想具有广阔的应用前景:
- 在推荐系统中,避免用户陷入"信息茧房",同时保持推荐的相关性
- 在创意生成领域,平衡新颖性与可行性,产生真正有创意的内容
- 在机器人控制中,鼓励探索新技能,同时确保基本任务的可靠性
更重要的是,EVOL-RL提醒我们:在构建自主智能时,多样性不是需要消除的"噪声",而是进化的必要条件。正如生物多样性是生态系统韧性的基础,认知多样性也是智能系统持续发展的关键。
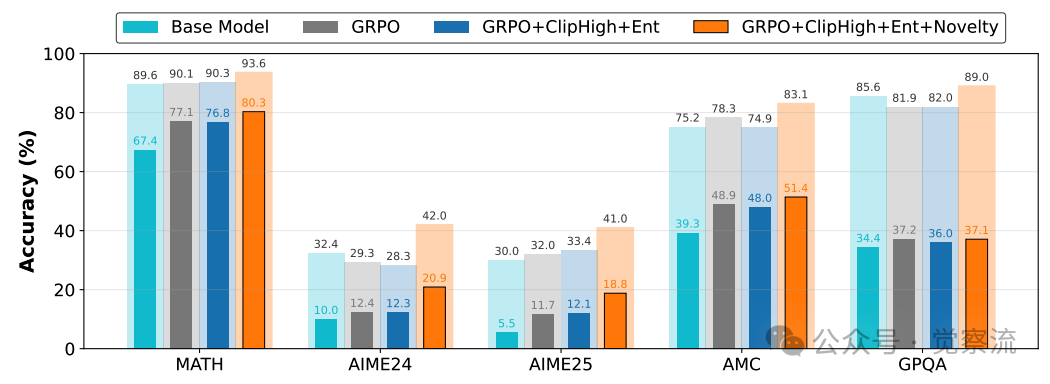
EVOL-RL组件在监督式GRPO中的表现
上图进一步证明了该方法的普适价值:当将EVOL-RL的探索增强组件应用于标准监督式GRPO(RLVR)时,完整组合(GRPO+ClipHigh+Ent+Novelty)在AIME24和AIME25等挑战性跨领域基准上将pass@16准确率提升了7%至12%。这表明"探索与选择相互依赖"的原则不仅适用于无标签场景,在有标签环境中同样能释放巨大潜力。
当AI研究者们重新拾起达尔文的进化智慧,我们或许正在见证一个新时代的开端——在这个时代,AI不仅能够解决已知问题,还能像生命一样,在无尽的探索中不断超越自身,真正实现"演化"而非"优化"。
EVOL-RL的突破性意义在于,它让AI从"应试机器"蜕变为"思考伙伴"。在传统方法下,AI会像一个只会说标准答案的学生——面对数学问题,不再提供详细的解题步骤,而是直接给出简短答案;当被问及创意问题时,只会重复常见观点,无法提出新颖见解。而EVOL-RL训练的模型则能提供更长、更丰富的思考过程,真正帮助用户理解问题本质。
这一转变不仅是技术指标的提升,还是AI与人类互动方式的变革。通过平衡"选择"与"变异",EVOL-RL实现了"演化"——在提升当前任务能力的同时,保持或增强其在域外问题上的表现和整体潜力。这正是从"适应"到"演化"的质变,也是AI迈向自主智能的关键一步。
EVOL-RL 通过将进化论的完整智慧引入AI领域,它不仅解决了无标签自演化的核心挑战,还为构建更加自主、灵活和适应性强的智能系统提供了新的范式。正如生命在地球上的演化历程,真正的智能进步不在于短期的性能优化,而在于长期的适应性和创新潜力——EVOL-RL,正是朝这个方向迈出的坚实一步。


