自动驾驶

文远知行获Grab投资数千万美元,双方将合作在东南亚大规模部署Robotaxi
8月15日,全球领先的自动驾驶科技公司文远知行WeRide(NASDAQ:WRD)宣布,东南亚地区的超级应用平台Grab(NASDAQ:GRAB)将对其进行数千万美元的股权投资。 此项投资是双方战略合作的一部分,旨在加速在东南亚大规模部署L4级Robotaxi及其他自动驾驶车辆,展现了双方的共同愿景:将文远知行的自动驾驶车辆接入Grab的运营网络当中,提升服务质量与安全水平。 该笔投资预计不晚于2026年上半年完成交割,具体交割时间将根据文远知行选定的时间点和成交条件确定。

深度解析:你的自动驾驶汽车会让你陷入网络攻击吗?
译者 | 晶颜审校 | 重楼随着自动驾驶汽车日益融入交通生态系统,新的、严峻的网络安全挑战也随之而来。 自动驾驶汽车(AVs)已从科幻构想快速发展为现实,有望彻底变革全球交通系统。 借助人工智能(AI)、机器学习、传感器融合及实时数据处理等先进技术,目前处于测试及上路阶段的自动驾驶汽车,正有望改变人们的通勤方式、货物运输模式以及与周边环境的互动形式。
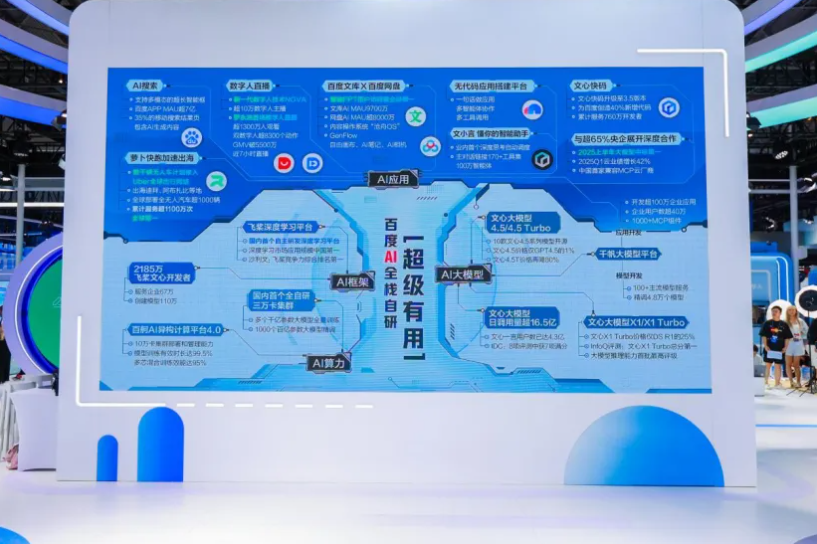
直击WAIC:萝卜快跑入选「国家队」,AI数字人技术升级,百度全栈自研杀疯了
前几天,奥特曼在采访中透露,亲自体验 GPT-5 后,被其强大的能力吓到。 有个自己都搞不懂的问题,模型却能一下答出来,那一刻他甚至觉得自己在擅长的领域也有些「无力」。 尽管 AI 进展飞快,但总有人质疑:真正落地的 AI 不多,很多所谓的新技术,可能只是炒作。

ICCV 2025 | UniOcc: 自动驾驶占用预测与推理统一数据集及基准平台
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。 UniOcc 融合真实世界(nuScenes、Waymo)与仿真环境(CARLA、OpenCOOD)的多源数据,统一体素(voxel)格式与语义(semantic)标签,首次引入体素级前后向运动流标注,并支持多车协同占位预测与推理。 为摆脱伪标签(pseudo-label)评估限制,UniOcc 设计了多项免真值(ground-truth-free)指标,用于衡量物体形状合理性与时序一致性。

特斯拉首次实现客户车辆“自动驾驶交付”,奥斯汀之路挑战重重
在奥斯汀推出有限的自动驾驶出租车服务仅几天后,特斯拉再次展示了其自动驾驶软件的最新进展。 一辆 Model Y SUV 在无人干预的情况下,完成了从特斯拉工厂到新车主公寓楼的约15英里行程,首席执行官埃隆·马斯克称之为首次客户汽车“自动驾驶交付”。 据称,这辆 Model Y 搭载了与特斯拉奥斯汀自动驾驶出租车相同的软件,但在交付时被降级为市售的全自动驾驶(监督)软件,该软件要求驾驶员保持专注并随时准备接管。

马斯克生日惊喜!全球首例Model Y无人「自驾交付」,30分钟见证历史
就在昨天,一个足以载入史册的时刻悄然到来。 一辆特斯拉Model Y从得州超级工厂缓缓驶出,没有驾驶员,没有安全员,也没有远程操控员。 它独自穿越城市街道,上下高速公路,以最高约115公里/小时(72英里/小时)的速度,在30分钟内平稳地把自己交付给主人。

破解自驾数据难题!毫米波雷达可控仿真技术新框架来了
以神经网络为核心引擎,让AI承担雷达仿真数据生成任务,还实现对雷达物理特性的建模与控制——这就是光轮智能联合清华AIR、LeddarTech等机构提出的全新自动驾驶神经渲染框架SA-Radar。 在无需雷达具体细节的情况下,它能实现可控且逼真的雷达仿真,支持场景的灵活编辑——包括雷达属性修改、演员移除以及新视角合成,并能显著增强多种下游任务。 作为高级驾驶辅助系统(ADAS)中扮演着至关重要角色的雷达,其相关研究和开发仍面临数据获取的挑战。

H-MBA层次化MamBa模型如何突破自动驾驶视频理解瓶颈?这三大创新亮点揭示答案!
一眼概览:H-MBA (Hierarchical MamBa Adaptation) 提出了一个创新的多模态视频理解框架,通过结合高低时域分辨率,显著提升了自动驾驶场景中的视频理解和风险物体检测性能。 核心问题:现有的多模态大语言模型(MLLMs)在处理自动驾驶中复杂的时空动态视频时,性能有限。 特别是在捕捉背景变化、车辆和行人运动等方面,现有方法难以做到准确的时空理解。

35.98万元起售,2025款小鹏X9香港上市,科技旗舰全面升舱
4 月 15 日晚,小鹏汽车在中国香港举办面向全球消费者的首场品牌发布会 —— 小鹏全球热爱之夜 2025 首款全球旗舰小鹏 X9 上市发布会,分享了在飞行汽车、AI 机器人领域的技术布局成果,并宣布将继续以技术创新和本地化战略加速全球市场布局。 发布会上,小鹏宣布超舒适 AI 大七座 2025 款小鹏 X9 正式上市,新车共发布四个版本,包括 650 长续航 Max、740 超长续航 Max、702 四驱高性能 Max 以及星舰版,官方指导售价分别为 35.98 万元、37.98 万元、39.98 万元以及 41.98 万元。 至 2025 年 6 月 30 日(含)前支付 5000 元定金的用户,可享购车好礼、置换复购礼、交付礼、无忧用车礼等多重上市订购权益。

小鹏汽车探索众包建图技术,但官方重申坚持无图和大模型路线
近日,有消息透露小鹏汽车正在内部积极研发一种名为 “众源建图” 的新技术,旨在为其自动驾驶系统提供更加精准的导航支持。 这项技术已推进数月,目前处于预研阶段,未来可能作为小鹏 L3级别自动驾驶方案的补充。 众源建图技术的核心在于通过多辆汽车的协同作业,实时采集道路数据,从而动态生成和更新地图。

小鹏高管谈特斯拉FSD入华:小鹏更懂中国路况
昨日,小鹏汽车举办AI大模型技术分享会,自动驾驶负责人李力耘在会上表示,AI大模型技术的突破正推动自动驾驶向实际落地迈出关键一步。 他提到,当前自动驾驶技术已具备前所未有的实现潜力,行业正迎来重要转折点。 针对特斯拉FSD进入中国市场的话题,李力耘指出,中美两国在智能驾驶拟人化表现上均达到较高水平,但小鹏汽车凭借对中国复杂路况的深刻理解,在本土化适配与用户实际体验中更具优势。

自动驾驶行业现状,端到端大模型,训练,数据合成方法
自动驾驶行业现状1、当前行业主要玩家有 第一梯队有:华为,momenta,元戎 第二梯队有:鉴智, 绝影智能等2、主机厂现在都要求自动驾驶厂商白盒交付,本质上就是前两年依赖供应商,后面打算自己做。 整个行业基本上是赔本赚吆喝的阶段。 没有收入,每年还要自己投入几个亿进行模型的训练,人才等。

Wayve推完整世界模型GAIA-2:支持同时生成5个视角的视频,可模拟高风险场景
Wayve公司近日隆重推出了其最新的视频生成世界模型——GAIA-2。 这一突破性的技术是其上一代模型GAIA-1的重大升级,旨在通过生成高度多样化和可控的驾驶场景视频,极大地推动辅助和自动驾驶系统的安全性发展. GAIA-2的发布标志着Wayve在利用生成式人工智能技术赋能更安全、更智能的出行方面迈出了坚实的一步。

自动驾驶首次应用测试时计算!港大英伟达等新技术让AI边开边学,无人车遇变道自如应对
当开车遇到变道、加塞等场景时,驾驶员往往会下意识地激活自己的“安全驾驶思维”,从而做出激进的规避行为。 与之类似,自动驾驶汽车在上述场景中,更会表现得像个谨小慎微的”新手司机”,这是因为模型的决策往往依赖于工程师预设的固定规则,进而导致“不求无功,但求无过”的驾驶风格,但过多的无故急刹、过度避让反而会引发额外的安全隐患。 针对上述问题,来自香港大学、英伟达和德国图宾根大学的联合团队提出Centaur(Cluster Entropy for Test-time trAining using UnceRtainty)方法,能够动态地改善驾驶策略,通过在线的数据驱动,摆脱了对预设规则的依赖,大幅提高了自动驾驶汽车在不确定性场景中的适应性与安全性。

仅凭RGB图像实现户外场景高精度定位与重建,来自港科广团队 | ICRA 25
从自动驾驶、机器人导航,到AR/VR等前沿应用,SLAM都是离不开的核心技术之一。 现有基于3D高斯分布(3DGS)的SLAM方法虽在室内场景表现出色,但使用仅RGB输入来处理无界的户外场景仍然面临挑战:准确的深度和尺度估计困难,这影响了姿态精度和3DGS初始化图像重叠有限且视角单一,缺乏有效的约束,导致训练难以收敛为了解决上述挑战,港科广团队提出全新解决方案——OpenGS-SLAM。 仅凭RGB图像实现高精度定位与逼真场景重建。

GTC大会上,理想发布下一代自动驾驶架构MindVLA
MindVLA 一种是视觉-语言-行为大模型,是机器人大模型的新范式。它将空间智能、语言智能和行为智能统一在单个模型里,为 AI 赋予了强大的 3D 空间理解能力、逻辑推理能力和行为生成能力,让自动驾驶能够感知、思考和适应环境。

深度解析以Decoder为核心的无BEV的大一统端到端架构 | 对话CCF-CV学术新锐奖贾萧松博士
论文的一些巧思1. 人开车其实并没有最优解,请问如何确定学习时的参考数据呢?开车其实也是多种多样的,然后你模仿学习本质上就是告诉他你只能这样做,你做了别的那个mass loss还会惩罚他。 其实就是我们说的,我们其实就不能通过模仿来做。

首创GRPO方案!AlphaDrive:VLM+RL破解自动驾驶长尾难题
写在前面 & 笔者的个人理解OpenAI o1 和 DeepSeek R1 在数学和科学等复杂领域达到了或甚至超越了人类专家的水平,强化学习(RL)和推理在其中发挥了关键作用。 在自动驾驶领域,最近的端到端模型极大地提高了规划性能,但由于常识和推理能力有限,仍然难以应对长尾问题。 一些研究将视觉-语言模型(VLMs)集成到自动驾驶中,但它们通常依赖于预训练模型,并在驾驶数据上进行简单的监督微调(SFT),没有进一步探索专门为规划设计的训练策略或优化方法。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉