性能

DeepSeek-V3.2-Exp:用稀疏注意力机制,开启长文本处理的“加速引擎”
随着人工智能技术的飞速发展,大语言模型在各个领域都展现出了巨大的潜力。 然而,传统的大语言模型在处理长文本时面临着效率低下和计算成本高昂的问题。 为了解决这一难题,DeepSeek-AI推出了实验性版本DeepSeek-V3.2-Exp,该模型通过引入DeepSeek稀疏注意力机制(DSA),在保持与V3.1-Terminus相当性能的同时,显著提升了长文本处理的效率。
10/14/2025 9:00:48 AM
AGI小兵

高水准的开发:能用AI解决的问题,绝不自己动手去写
对于开发人员和软件测试人员来说,最重要的是有一款量身定制的接口调试工具,可以让开发和测试工作事半功倍。 Apipost是AI驱动的集API设计、调试、文档生成、自动化测试、性能测试于一体的API开发协作管理平台,功能全面,尤其适合注重团队协作和轻量体验的用户。 图片一、Apipost核心优势无需登录,离线可用:Apipost无需账号登录,支持离线调试,保护用户隐私,提升效率;高效的AI智能开发助手:集成AI大模型,解决接口开发测试过程中命名难题、手动维护文档繁琐等痛点问题,实现API设计、调试、文档生成和自动化测试的闭环高效开发管理;超轻量设计:资源占用少,加载迅速,适合对性能敏感的用户;100%兼容Postman脚本语法:用户可以无缝迁移现有Postman脚本,降低学习成本。
7/31/2025 12:00:05 AM

只需一次指令微调,大模型变身全能专家天团,8B模型性能反超全微调基线 | ACL25 Oral
只需一次指令微调,即可让普通大模型变身“全能专家天团”? 改造位置自动定位专家协作动态平衡8B模型性能反超全微调基线1.6%,安全指标暴涨10%,推理内存直降30%! 图片当前预训练语言大模型(LLM)虽具备通用能力,但适应专业领域需高昂的指令微调成本;稀疏混合专家(SMoE)架构作为可扩展的性能-效率平衡框架,虽能提升推理效率并灵活扩展模型容量,但其从头训练消耗巨大资源,因此复用密集大模型参数的升级改造(LLM Upcycling)成为更具成本效益的替代方案。
7/29/2025 2:12:00 AM

大模型的性能提升:KV-Cache
大语言模型(LLM)在生成文本时,通常是一个 token 一个 token 地进行。 每当模型生成一个新的 token,它就会把这个 token 加入输入序列,作为下一步预测下一个 token 的依据。 这一过程不断重复,直到完成整个输出。
6/18/2025 11:16:50 AM
曹洪伟

arXiv 2025 | 无需增参!加权卷积wConv2D助力分类去噪双提升,传统CNN焕然一新!
一眼概览本文提出了一种无需增加参数的加权卷积算子,通过引入空间密度函数显著提升CNN在图像分类与去噪任务中的性能表现。 核心问题传统卷积操作默认局部邻域内的像素等权贡献,忽视其空间位置差异,这限制了模型对空间特征的刻画能力。 该研究旨在解决如何在不增加模型参数的前提下,使卷积操作能够自适应地感知像素间的空间结构,从而提升图像分类与去噪性能。
6/13/2025 4:12:00 AM
萍哥学AI

OCR 识别质量如何影响 RAG 系统的性能?有何解决办法?
检索增强生成(RAG)已成为连接大语言模型与企业数据的标准范式,但该方法存在一个鲜少被讨论的致命缺陷:当前生产环境中的 RAG 系统几乎全部依赖光学字符识别(OCR)技术处理 PDF、扫描件、演示文稿等文档,并默认假设识别结果足以支撑下游 AI 任务。 我们的深度分析表明,这一假设存在根本性缺陷。 OCR 的识别质量形成了一个隐形的天花板,甚至限制了最先进 RAG 系统的性能。
6/11/2025 3:10:00 AM
Baihai IDP

性能优化!七个策略,让Spring Boot 处理每秒百万请求
环境:SpringBoot3.4.21. 简介在实施任何优化前,我首先明确了性能基准。 这一步至关重要——若不清楚起点,便无法衡量进展,也无法定位最关键的改进方向。
5/28/2025 5:10:00 AM
Springboot实战案例锦集
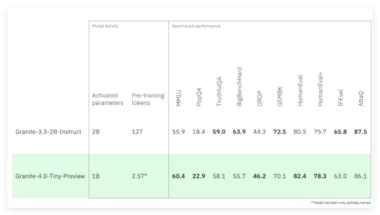
小巧却强大!IBM发布新语言模型Granite 4.0 Tiny Preview:长上下文处理
IBM 发布了 Granite4.0Tiny Preview,这是即将推出的 Granite4.0系列语言模型中最小的一款的预览版本。 该模型不仅具备高效的计算能力,还为开源社区提供了一个值得关注的实验平台。 高效的性能与极小的内存需求 Granite4.0Tiny 在 FP8精度下,能够在消费级硬件上运行多个长上下文(128K)的并发任务,适用于市面上价格低于350美元的 GPU。
5/7/2025 6:00:54 PM
AI在线
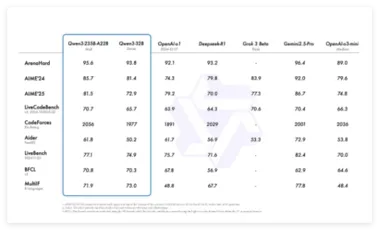
阿里发布开源Qwen3,成本大幅降低仅需DeepSeek-R1的三分之一
阿里巴巴正式推出新一代通义千问模型 Qwen3(千问3),并宣布其开源。 阿里云表示,千问3是国内首个 “混合推理模型”,同时集成了 “快思考” 与 “慢思考” 的能力。 相比于 DeepSeek-R1,千问3的参数量仅为其三分之一,而部署成本大幅降低,使用仅需四张 H20显卡即可实现满血版的部署。
4/29/2025 9:00:40 AM
AI在线

ScaleOT框架亮相AAAI 2025:提升隐私保护50%,降算力成本90%
近日,在全球人工智能顶级学术会议AAAI2025期间,蚂蚁数科、浙江大学、利物浦大学和华东师范大学联合团队提出创新的跨域微调(offsite-tuning)框架——ScaleOT。 该框架能在模型性能无损前提下,将隐私保护效果提升50%,与知识蒸馏技术相比,算力消耗显著降低90%,为百亿级参数模型的跨域微调提供高效轻量化方案,论文因创新性入选AAAI的oral论文(本届大会近13000篇投稿,口头报告比例仅4.6%)。 跨域微调是目前业内保护模型产权与数据隐私的主流方案,通过有损压缩将大模型转换为仿真器,数据持有方基于其训练适配器并返回给大模型完成调优,数据和模型均未出域,可保护双方隐私,但存在局限性:一是“均匀抽积木”式处理易致模型关键层缺失,使性能显著下降;二是用蒸馏技术弥补性能损失,计算成本高;且现有方法隐私保护缺乏灵活性。
2/26/2025 2:13:00 PM
AI在线

DeepSeek开源FlashMLA:Hopper GPU解码新标杆,测评大揭秘!
DeepSeek今天正式启动为期五天的开源成果发布计划,首个亮相的项目是FlashMLA。 这一开源项目将先进的MLA算法与GPU优化技术相结合,为大模型推理提供了一套高性能、低延迟的解码方案。 FlashMLA是一款专门为Hopper GPU(比如H800 SXM5)优化的高效MLA解码内核,旨在加速大模型的计算任务,尤其是在NVIDIA高端显卡上提升性能。
2/25/2025 10:09:00 AM
新闻助手

李飞飞谢赛宁新作「空间推理」:多模态大模型性能突破关键所在
李飞飞谢赛宁再发新成果:直接把o1式思考拉至下一个level——多模态大语言模型的空间思维! 这项研究系统评估了多模态大模型的视觉空间智能,结果发现:当前,即使是最先进的多模态大模型,在空间认知方面与人类相比仍有显著差距,测试中约71%的错误都源于空间推理方面的缺陷,即空间推理能力是当前主要瓶颈。 图片更为有趣的是,在这种情况下,思维链、思维树等常用的语言提示技术直接失灵了——不仅没有提升模型在空间任务上的表现,反而会使性能下降。
12/23/2024 12:37:34 PM

明确了:文本数据中加点代码,训练出的大模型更强、更通用
代码知识原来这么重要。如今说起大语言模型(LLM),写代码能力恐怕是「君子六艺」必不可少的一项。在预训练数据集中包含代码,即使对于并非专门为代码设计的大模型来说,也已是必不可少的事。虽然从业者们普遍认为代码数据在通用 LLM 的性能中起着至关重要的作用,但分析代码对非代码任务的精确影响的工作却非常有限。在最近由 Cohere 等机构提交的一项工作中,研究者系统地研究了代码数据对通用大模型性能的影响。论文链接:「预训练中使用的代码数据对代码生成以外的各种下游任务有何影响」。作者对范围广泛的自然语言推理任务、世界知识任
8/22/2024 6:20:00 PM
机器之心

1230 亿参数,Mistral 发布 Large 2 旗舰 AI 模型:支持 80 多种编程语言,增强代码生成、数学和推理能力
AI 竞赛日益激烈,Meta 公司昨日推出开源 Llama 3.1 模型之后,法国人工智能初创公司 Mistral 也加入了竞争行列,推出了新一代旗舰模型 Mistral Large 2。模型简介该模型共有 1230 亿个参数,在代码生成、数学和推理方面比其前身功能更强大,并提供更强大的多语言支持和高级函数调用功能。Mistral Large 2 拥有 128k 的上下文窗口,支持包括中文在内的数十种语言以及 80 多种编码语言。该模型在 MMLU 上的准确度达到了 84.0%,并在代码生成、推理和多语言支持方面有
7/25/2024 6:53:16 AM
故渊

90/270 亿参数,谷歌发布 Gemma 2 开源 AI 模型:性能力压同级、单 A100 / H100 GPU 可运行
感谢谷歌公司昨日发布新闻稿,面向全球研究人员和开发人员发布 Gemma 2 大语言模型,共有 90 亿参数(9B)和 270 亿参数(27B)两种大小。Gemma 2 大语言模型相比较第一代,推理性能更高、效率更高,并在安全性方面取得了重大进步。谷歌在新闻稿中表示,Gemma 2-27B 模型的性能媲美两倍规模的主流模型,而且只需要一片英伟达 H100 ensor Core GPU 或 TPU 主机就能实现这种性能,从而大大降低了部署成本。Gemma 2-9B 模型优于 Llama 3 8B 和其他类似规模的开源模
6/28/2024 8:21:10 AM
故渊

比原始材料强8倍,清华、武汉理工团队用AI筛选高熵电介质材料
编辑 | 萝卜皮电介质材料能够储存和释放电荷,广泛应用于电容器、电子和电力系统中。它们因其高功率密度和快速响应特性,被用于混合动力电动汽车、便携式电子设备和脉冲电力系统等领域,但其能量密度仍需进一步提高。高熵策略已成为提高储能性能的有效方法,然而,在高维组成空间中发现新的高熵系统对于传统的试错实验来说是一个巨大的挑战。武汉理工大学、清华大学、宾夕法尼亚州立大学的研究团队基于相场模拟和有限的实验数据,提出了一种生成学习方法,用于加速在超过 10^11 种组合的无限探索空间中发现高熵介电材料(HED)。该工作为设计高熵
6/25/2024 7:15:00 PM
ScienceAI

苹果推出 300 亿参数 MM1 多模态 AI 大模型,可识别图像推理自然语言
感谢苹果公司旗下研究团队近日在 ArXiv 中公布了一篇名为《MM1:Methods, Analysis & Insights from Multimodal LLM Pre-training》的论文,其中介绍了一款 “MM1”多模态大模型,该模型提供 30 亿、70 亿、300 亿三种参数规模,拥有图像识别和自然语言推理能力。IT之家注意到,苹果研究团队相关论文主要是利用 MM1 模型做实验,通过控制各种变量,找出影响模型效果的关键因素。研究表明,图像分辨率和图像标记数量对模型性能影响较大,视觉语言连接器对模型的
3/16/2024 6:31:33 PM
漾仔
Llama2推理RTX3090胜过4090,延迟吞吐量占优,但被A800远远甩开
这是为数不多深入比较使用消费级 GPU(RTX 3090、4090)和服务器显卡(A800)进行大模型预训练、微调和推理的论文。大型语言模型 (LLM) 在学界和业界都取得了巨大的进展。但训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的开源框架和方法。然而,不同硬件和软件堆栈的运行时性能可能存在很大差异,这使得选择最佳配置变得困难。最近,一篇题为《Dissecting the Runtime Performance of the Training,
12/27/2023 3:04:00 PM
机器之心
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
大模型
机器人
数据
AI新词
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
马斯克
英伟达
Anthropic
图像
AI创作
训练
LLM
论文
代码
算法
苹果
AI for Science
Agent
Claude
腾讯
芯片
Stable Diffusion
蛋白质
具身智能
开发者
xAI
生成式
神经网络
机器学习
人形机器人
3D
AI视频
RAG
大语言模型
Sora
研究
百度
生成
GPU
工具
华为
字节跳动
计算
AGI
大型语言模型
AI设计
搜索
生成式AI
视频生成
DeepMind
AI模型
特斯拉
场景
深度学习
亚马逊
架构
Transformer
MCP
Copilot
编程
视觉