随着人工智能技术的飞速发展,大语言模型在各个领域都展现出了巨大的潜力。然而,传统的大语言模型在处理长文本时面临着效率低下和计算成本高昂的问题。为了解决这一难题,DeepSeek-AI推出了实验性版本DeepSeek-V3.2-Exp,该模型通过引入DeepSeek稀疏注意力机制(DSA),在保持与V3.1-Terminus相当性能的同时,显著提升了长文本处理的效率。
 图片
图片
一、项目概述
DeepSeek-V3.2-Exp是DeepSeek-AI于2025年9月29日发布的实验性大语言模型,旨在探索和验证在长上下文场景下训练和推理效率的优化。该模型基于V3.1-Terminus构建,引入了创新的DeepSeek稀疏注意力(DSA)机制,实现了细粒度稀疏注意力,突破了传统Transformer架构的限制。在多个公开基准测试中,DeepSeek-V3.2-Exp的性能与V3.1-Terminus基本持平,但在长文本处理场景中,其推理成本显著降低。
二、核心功能
(一)架构创新
DeepSeek-V3.2-Exp的核心创新在于其稀疏注意力机制。传统的Transformer模型在处理长文本时,由于需要计算每个标记之间的注意力权重,导致计算复杂度呈二次方增长,极大地限制了模型的效率。而DeepSeek-V3.2-Exp通过引入闪电索引器(lightning indexer)和细粒度标记选择机制,实现了细粒度的稀疏注意力。这种机制只关注最相关的标记,从而大幅减少了不必要的计算。
(二)性能优化
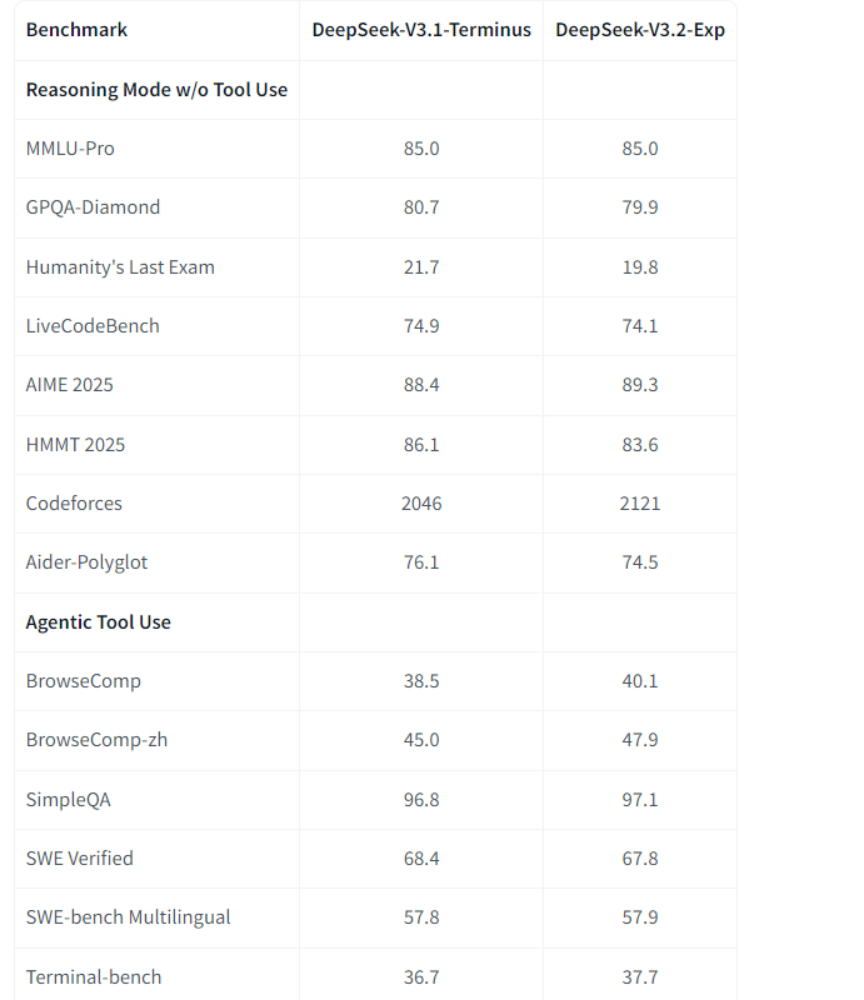
尽管引入了稀疏注意力机制,DeepSeek-V3.2-Exp在性能上并未受到影响。在多个领域的公共基准测试中,其表现与V3.1-Terminus相当。例如,在MMLU-Pro知识测试和代码挑战中,DeepSeek-V3.2-Exp的得分与V3.1-Terminus相当,甚至在某些任务中略有提升。
(三)成本降低
DeepSeek-V3.2-Exp的API定价大幅下降,输入成本低至$0.07/百万token(缓存命中),降低了开发者的使用成本。这一成本降低主要得益于稀疏注意力机制带来的计算成本降低和引入的缓存机制。
(四)开源支持
DeepSeek-V3.2-Exp提供了完整的推理代码、CUDA内核和多平台部署解决方案。这使得研究人员和开发者可以轻松地在本地部署和使用该模型,进一步推动了其在实际应用中的广泛部署。
三、技术揭秘
(一)稀疏注意力机制
DeepSeek-V3.2-Exp的稀疏注意力机制是其核心技术。该机制通过闪电索引器计算查询标记与前序标记之间的索引分数,然后选择前k个关键值条目进行注意力计算。这种细粒度的稀疏注意力机制不仅显著提高了长文本处理的效率,还保持了模型输出质量。
(二)闪电索引器
闪电索引器是DSA的核心组件,它通过少量的索引头和高效的计算方式,快速确定哪些标记对查询标记最重要。这种高效的索引机制使得模型能够在长文本场景下快速定位关键信息,从而提高推理速度。
(三)训练策略
DeepSeek-V3.2-Exp的训练过程分为两个阶段:密集预热阶段和稀疏训练阶段。在密集预热阶段,仅训练索引器,保持其余参数不变,使其输出的分数分布与原始注意力分布对齐。在稀疏训练阶段,引入令牌选择机制,同时优化索引器和主模型参数,使模型适应稀疏注意力模式。
四、基准评测
在多项基准测试中,DeepSeek-V3.2-Exp的表现与V3.1-Terminus基本持平。例如,在MMLU-Pro、GPQA-Diamond等任务中,DeepSeek-V3.2-Exp的性能与V3.1-Terminus相当。然而,在长文本处理场景中,DeepSeek-V3.2-Exp的推理成本显著降低。
五、应用场景
(一)长文本处理
DeepSeek-V3.2-Exp适用于需要处理长文本的场景,如长篇文档分析、长文本生成等。其稀疏注意力机制能够显著提高长文本的处理效率,使得模型能够在更短的时间内完成任务。
(二)代码生成与编程辅助
DeepSeek-V3.2-Exp在代码生成和编程辅助任务中表现出色。它能够帮助开发者快速生成代码片段、优化代码结构,提高编程效率。
(三)多语言处理
DeepSeek-V3.2-Exp支持多语言任务,可应用于跨语言的文本生成、翻译等场景。这使得该模型能够在不同语言环境下的需求中发挥作用。
六、快速使用
(一)HuggingFace原生部署
用户可以从Hugging Face平台下载DeepSeek-V3.2-Exp的模型权重,按照提供的本地运行指南,将权重转换为推理演示所需格式,并启动交互式聊天界面进行使用。
1、格式转换
首先将huggingface 模型权重转换为推理演示所需的格式。设置 MP 以匹配您可用的 GPU 数量
复制2、启动运行
启动交互式聊天界面,开始探索DeepSeek 的功能:
复制(二)SGLang高性能部署
SGLang是DeepSeek-V3.2的官方推理框架,具有优化的稀疏注意力内核、动态KV缓存,并能无缝扩展到128K个token。用户可以通过Docker镜像快速部署该模型,并根据硬件平台选择对应的镜像。
1、使用 Docker 安装
复制2、启动命令:
复制(三)vLLM集成
vLLM提供了对DeepSeek-V3.2-Exp的day-0支持,用户可以参考官方recipes进行配置。
https://docs.vllm.ai/projects/recipes/en/latest/DeepSeek/DeepSeek-V3_2-Exp.html
七、结语
DeepSeek-V3.2-Exp的发布,不仅展示了一种高效的长上下文处理方案,也为大模型在保持性能的同时降低计算成本提供了新的思路。该模型通过引入稀疏注意力机制,在长文本处理场景中实现了显著的效率提升,同时保持了与V3.1-Terminus相当的性能。DeepSeek-V3.2-Exp的开源支持和多平台部署解决方案,进一步推动了其在实际应用中的广泛部署。
项目地址
HuggingFace模型库:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
魔搭社区:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
技术论文:https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf


